Python 官方文档:入门教程 => 点击学习
一、pandas 2008年WesMcKinney开发出的库 专门用于数据挖掘的开源python库 以Numpy为基础,借力Numpy模块在计算方面性能高的优势 基于matplotlib,能够简便的画图 独特的数据结
2008年WesMcKinney开发出的库
以Numpy为基础,借力Numpy模块在计算方面性能高的优势
基于matplotlib,能够简便的画图
独特的数据结构
Series是一个类似于一维数组的数据结构,它能够保存任何类型的数据,比如整数、字符串、浮点数等,主要由一组数据和与之相关的索引两部分构成。
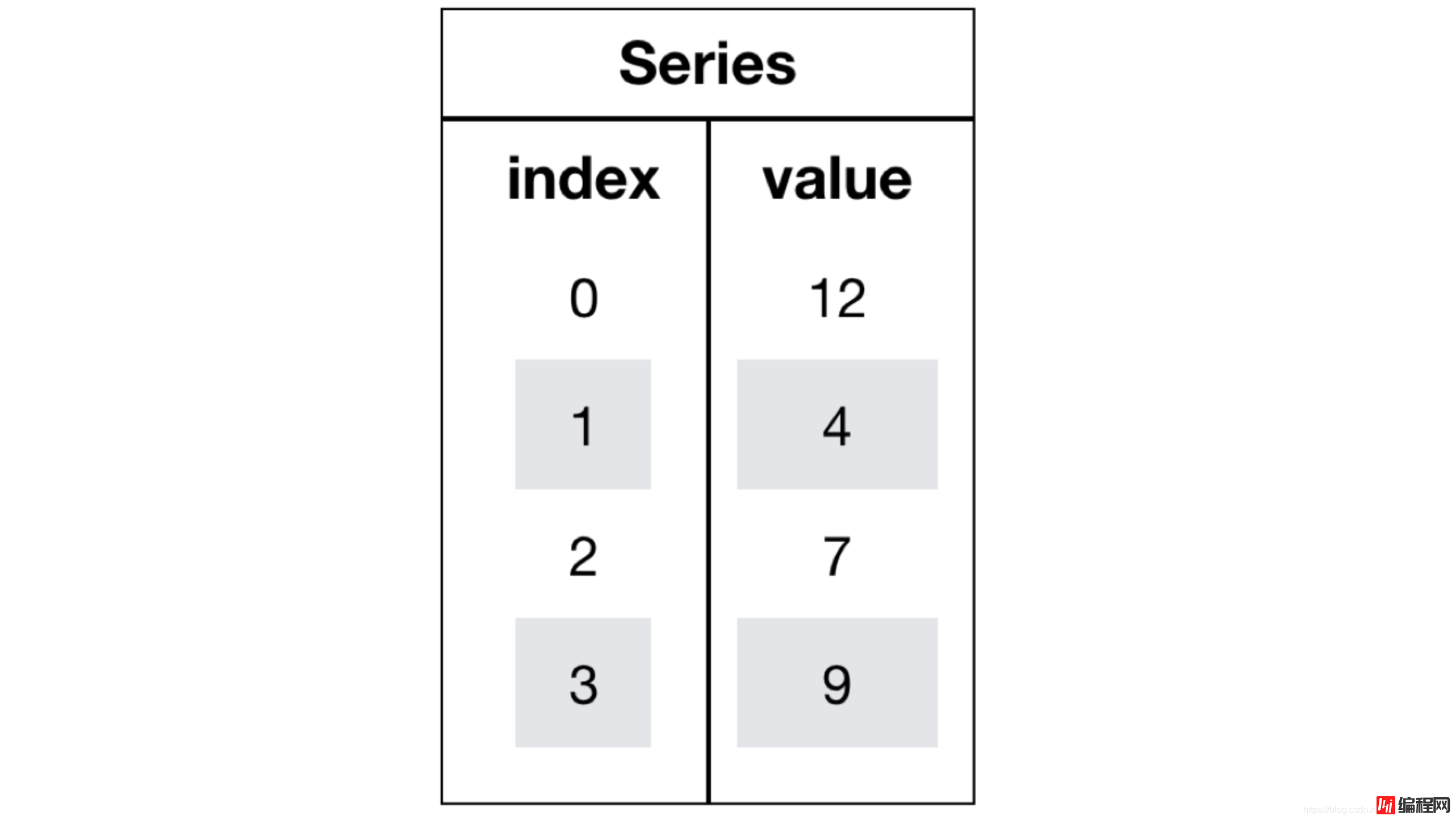
import pandas as pd
pd.Series(np.arange(3))0 0
1 1
2 2
dtype: int64
#指定索引
pd.Series([6.7,5.6,3,10,2], index=[1,2,3,4,5])1 6.7
2 5.6
3 3.0
4 10.0
5 2.0
dtype: float64
#通过字典数据创建
color_count = pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})
color_countblue 200
green 500
red 100
yellow 1000
dtype: int64
color_count.index
color_count.values也可以使用索引来获取数据:
color_count[2]100
data[‘p_change'].sort_values(ascending=True) # 对值进行排序
data[‘p_change'].sort_index() # 对索引进行排序
#series排序时,只有一列,不需要参数
创建
pd.DataFrame(np.random.randn(2,3))
score = np.random.randint(40, 100, (10, 5))
scorearray([[92, 55, 78, 50, 50],
[71, 76, 50, 48, 96],
[45, 84, 78, 51, 68],
[81, 91, 56, 54, 76],
[86, 66, 77, 67, 95],
[46, 86, 56, 61, 99],
[46, 95, 44, 46, 56],
[80, 50, 45, 65, 57],
[41, 93, 90, 41, 97],
[65, 83, 57, 57, 40]])
但是这样的数据形式很难看到存储的是什么的样的数据,可读性比较差!!
# 使用Pandas中的数据结构
score_df = pd.DataFrame(score)
data.shape
data.index
data.columns
data.values
data.T
data.head(5)
data.tail(5)
data.reset_index(keys, drop=True)
keys : 列索引名成或者列索引名称的列表
drop : boolean, default True.当做新的索引,删除原来的列
data[‘open'][‘2018-02-27'] # 直接使用行列索引名字的方式(先列后行)
data.loc[‘2018-02-27':‘2018-02-22', ‘open'] # 使用loc:只能指定行列索引的名字
data.iloc[:3, :5 ]# 使用iloc可以通过索引的下标去获取
data.sort_values(by=“open”, ascending=True) #单个排序
data.sort_values(by=[‘open', ‘high']) # 按照多个键进行排序
data.sort_index() # 对索引进行排序
DataFrame运算
应用add等实现数据间的加、减法运算
应用逻辑运算符号实现数据的逻辑筛选
应用isin, query实现数据的筛选
使用describe完成综合统计
使用max, min, mean, std完成统计计算
使用idxmin、idxmax完成最大值最小值的索引
使用cumsum等实现累计分析
应用apply函数实现数据的自定义处理
DataFrame.plot(kind=‘line')
kind : str,需要绘制图形的种类
‘line' : line plot (default)
‘bar' : vertical bar plot
‘barh' : horizontal bar plot
关于“barh”的解释:
Http://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.plot.barh.html
‘hist' : histogram
‘pie' : pie plot
‘scatter' : scatter plot
isnull、notnull判断是否存在缺失值
np.any(pd.isnull(movie)) # 里面如果有一个缺失值,就返回True
np.all(pd.notnull(movie)) # 里面如果有一个缺失值,就返回False
dropna删除np.nan标记的缺失值
movie.dropna()
fillna填充缺失值
movie[i].fillna(value=movie[i].mean(), inplace=True)
replace替换
wis.replace(to_replace="?", value=np.NaN)
p_change= data['p_change']
# 自行分组,每组个数差不多
qcut = pd.qcut(p_change, 10)
# 计算分到每个组数据个数
qcut.value_counts()
# 自己指定分组区间
bins = [-100, -7, -5, -3, 0, 3, 5, 7, 100]
p_counts = pd.cut(p_change, bins)得出one-hot编码矩阵
dummies = pd.get_dummies(p_counts, prefix="rise")
#prefix:分组名字前缀pd.concat([data1, data2], axis=1)
按照行或列进行合并,axis=0为列索引,axis=1为行索引pd.merge(left, right, how=‘inner', on=None)
可以指定按照两组数据的共同键值对合并或者左右各自
left: DataFrame
right: 另一个DataFrame
on: 指定的共同键
how:按照什么方式连接
交叉表:计算一列数据对于另外一列数据的分组个数 透视表:指定某一列对另一列的关系
#通过交叉表找寻两列数据的关系
count = pd.crosstab(data['week'], data['posi_neg'])
#通过透视表,将整个过程变成更简单一些
data.pivot_table(['posi_neg'], index='week')
count = starbucks.groupby(['Country']).count()
col.groupby(['color'])['price1'].mean()
#抛开聚合谈分组,无意义到此这篇关于Python机器学习三大件之二pandas的文章就介绍到这了,更多相关Python pandas内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python机器学习三大件之二pandas
本文链接: https://www.lsjlt.com/news/10595.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0