Python 官方文档:入门教程 => 点击学习
目录GitHub源码地址:各类图表的实现效果爬取的说说内容个性化说说内容词云图每年发表说说总数柱状图、每年点赞和评论折线图7天好友动态柱状图、饼图使用方法主要代码github源码地址: https://github.
https://github.com/kuishou68/python




按照你的谷歌浏览器下载指定版本的驱动 Http://chromedriver.storage.Googleapis.com/index.html


驱动跟两个Python脚本放入同目录,我的版本是90.0.4430的,查看你自己的版本,下载后把我的chromedriver.exe替换掉!

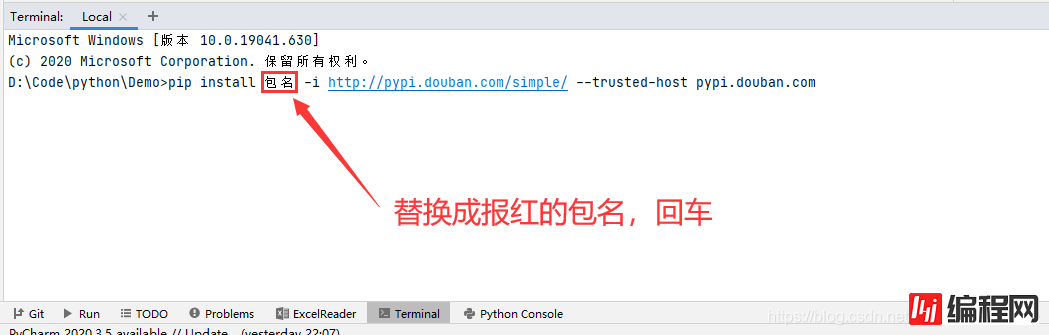
这里用到了很多第三方包,鼠标放在报红的包名下,用Alt+Enter导包,如果失败则在控制台用下面的必杀技
pip install 包名 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
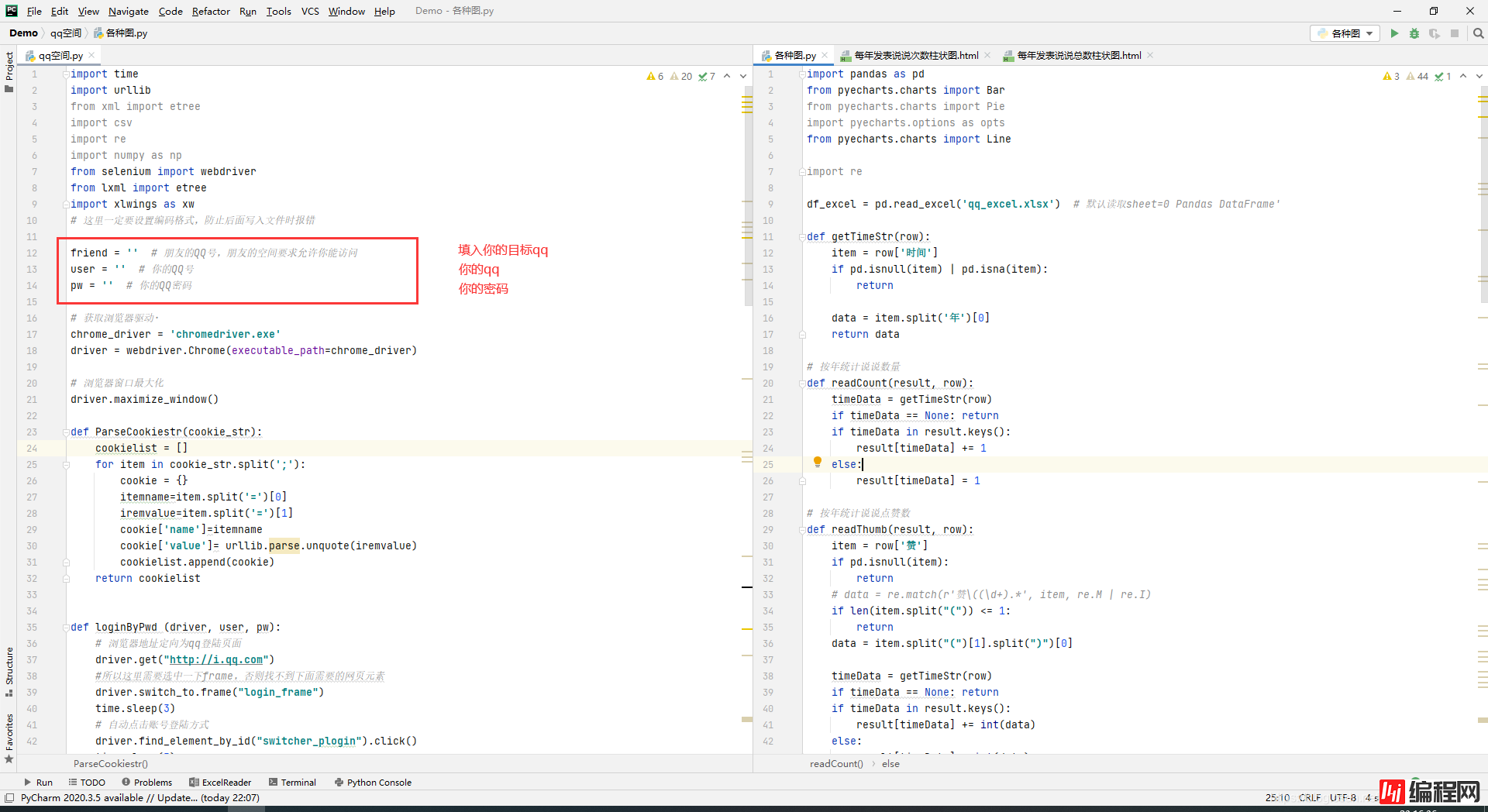
qq空间txt.py
import time
from selenium import WEBdriver
from lxml import etree
# 这里一定要设置编码格式,防止后面写入文件时报错
friend = '1569339843' # 朋友的QQ号,朋友的空间要求允许你能访问
user = '783533896' # 你的QQ号
pw = '1323mkoNJI.@' # 你的QQ密码
# 获取浏览器驱动
chrome_driver = 'chromedriver.exe'
driver = webdriver.Chrome(executable_path=chrome_driver)
# 浏览器窗口最大化
driver.maximize_window()
# 浏览器地址定向为qq登陆页面
driver.get("http://i.qq.com")
# 所以这里需要选中一下frame,否则找不到下面需要的网页元素
driver.switch_to.frame("login_frame")
time.sleep(3)
# 自动点击账号登陆方式
driver.find_element_by_id("switcher_plogin").click()
time.sleep(3)
# 账号输入框输入已知qq账号
driver.find_element_by_id("u").send_keys(user)
time.sleep(5)
# 密码框输入已知密码
driver.find_element_by_id("p").send_keys(pw)
time.sleep(5)
# 自动点击登陆按钮
driver.find_element_by_id("login_button").click()
time.sleep(5)
# 让webdriver操纵当前页
driver.switch_to.default_content()
time.sleep(5)
# 跳到说说的url, friend你可以任意改成你想访问的空间
driver.get("http://user.qzone.qq.com/" + friend + "/311")
time.sleep(5)
next_num = 0 # 初始“下一页”的id
while True:
# 下拉滚动条,使浏览器加载出动态加载的内容,
# 我这里是从1开始到6结束 分5 次加载完每页数据
for i in range(1, 6):
height = 20000 * i # 每次滑动20000像素
strWord = "window.scrollBy(0," + str(height) + ")"
driver.execute_script(strWord)
time.sleep(4)
# 很多时候网页由多个<frame>或<iframe>组成,webdriver默认定位的是最外层的frame,
# 所以这里需要选中一下说说所在的frame,否则找不到下面需要的网页元素
driver.switch_to.frame("app_canvas_frame")
selector = etree.HTML(driver.page_source)
divs = selector.xpath('//*[@id="msgList"]/li/div[3]')
# 这里使用 a 表示内容可以连续不清空写入
with open('qq_word.txt', 'a', encoding="utf-8") as f:
for div in divs:
qq_name = div.xpath('./div[2]/a/text()')
qq_content = div.xpath('./div[2]/pre/text()')
qq_time = div.xpath('./div[4]/div[1]/span/a/text()')
qq_praise = div.xpath('./div[4]/div[2]/span/span/a[2]/text()')
qq_comment = div.xpath('./div[4]/div[2]/a[3]/text()')
qq_name = qq_name[0] if len(qq_name) > 0 else ''
qq_content = qq_content[0] if len(qq_content) > 0 else ''
qq_content = qq_content.replace('\n', ' ')
qq_time = qq_time[0] if len(qq_time) > 0 else ''
qq_praise = qq_praise[0] if len(qq_praise) > 0 else ''
qq_comment = qq_comment[0] if len(qq_comment) > 0 else ''
print(qq_name, qq_time, qq_content, qq_praise, qq_comment)
f.write(qq_content + "\n")
# 当已经到了尾页,“下一页”这个按钮就没有id了,可以结束了
if driver.page_source.find('pager_next_' + str(next_num)) == -1:
break
# 找到“下一页”的按钮,因为下一页的按钮是动态变化的,这里需要动态记录一下
driver.find_element_by_id('pager_next_' + str(next_num)).click()
# “下一页”的id
next_num += 1
# 因为在下一个循环里首先还要把页面下拉,所以要跳到外层的frame上
driver.switch_to.parent_frame()
# 关闭浏览器
driver.quit()各种图表的生成
import pandas as pd
from pyecharts.charts import Bar
from pyecharts.charts import Pie
import pyecharts.options as opts
from pyecharts.charts import Line
import re
df_excel = pd.read_excel('qq_excel.xlsx') # 默认读取sheet=0 Pandas DataFrame'
def getTimeStr(row):
item = row['时间']
if pd.isnull(item) | pd.isna(item):
return
data = item.split('年')[0]
return data
# 按年统计说说数量
def readCount(result, row):
timeData = getTimeStr(row)
if timeData == None: return
if timeData in result.keys():
result[timeData] += 1
else:
result[timeData] = 1
# 按年统计说说点赞数
def readThumb(result, row):
item = row['赞']
if pd.isnull(item):
return
# data = re.match(r'赞\((\d+).*', item, re.M | re.I)
if len(item.split("(")) <= 1:
return
data = item.split("(")[1].split(")")[0]
timeData = getTimeStr(row)
if timeData == None: return
if timeData in result.keys():
result[timeData] += int(data)
else:
result[timeData] = int(data)
# 按年统计说说评论数
def readComment(result, row):
item = row['评论']
if pd.isnull(item):
return
# data = re.match(r'赞\((\d+).*', item, re.M | re.I)
if len(item.split("(")) <= 1:
return
data = item.split("(")[1].split(")")[0]
timeData = getTimeStr(row)
if timeData == None: return
if timeData in result.keys():
result[timeData] += int(data)
else:
result[timeData] = int(data)
def readExcel(df_excel):
count = {}
result = {}
thumb = {}
comment = {}
for index, row in df_excel.iterrows():
readCount(count, row)
readThumb(thumb, row)
readComment(comment, row)
result['count'] = count
result['thumb'] = thumb
result['comment'] = comment
return result
def geTKEyAndVal(keyWord):
data = readExcel(df_excel).get(keyWord)
key = []
value = []
for item in data.keys():
key.append(item)
value.append(data[item])
key.reverse()
value.reverse()
return [key, value]
# 统计每年发表说说次数柱状图
def paintBar():
count = readExcel(df_excel).get('count')
# V1 版本开始支持链式调用
data = getKeyAndVal('count')
print(data[0])
d = (
Bar()
.add_xaxis(data[0])
.add_yaxis("每年发表说说总数", data[1])
.render("每年发表说说总数柱状图.html")
)
paintBar()
# 统计点赞和评论折线图
def paintLine():
commentData = getKeyAndVal('comment')
thumbData = getKeyAndVal('thumb')
xaxis_data = commentData[0]
commentValue = commentData[1]
thumbValue = thumbData[1]
d = (
Line()
.add_xaxis(xaxis_data=xaxis_data)
.add_yaxis("每年评论数", y_axis=commentValue)
.add_yaxis("每年点赞数", y_axis=thumbValue)
.render("每年点赞和评论折现图.html") # 输出图形
)
paintLine()其他代码自行下载项目查看
以上就是python爬取网页版QQ空间,生成各类图表的详细内容,更多关于python 爬取QQ空间的资料请关注编程网其它相关文章!
--结束END--
本文标题: python爬取网页版QQ空间,生成各类图表
本文链接: https://www.lsjlt.com/news/10828.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0