Python 官方文档:入门教程 => 点击学习
前言 我们先说一下思路:先对目标网站发送请求,获取html源码,然后对源码里面的所以图片链接进行筛选,然后再次对图片链接发送请求,然后保存。 思路大致是这样,话不多说,直接上代码:
我们先说一下思路:先对目标网站发送请求,获取html源码,然后对源码里面的所以图片链接进行筛选,然后再次对图片链接发送请求,然后保存。
思路大致是这样,话不多说,直接上代码:
用到的模块:
import requests #请求库 第三方库,需要安装: pip install requests
import re #筛选库,py自带,无需安装查找接口:
打开F12打开开发者工具,点击网络、Fetch/XHR、载荷、依次点下去,可以看到查询参数有两个,分别是:word:风景图 queryWord:风景图
我们可以利用这两个查询参数进行自定义:

我们要查找到真实的url地址,然后对url查询参数自定义,点击旁边的标头,我们看见了刚才的查询参数:word 和queryWord这两个参数,

接下来,我们使用让用户输入参数值,然后进行传参到url地址里面的word和queryWord参数,
那么word和queryWord参数,url地址里面就不能有了值了,使用{}被传参,后面使用fORMat函数对输入的参数进行传参{},最后形成我们需要的网址
Word = input('请输入要搜索的图片:')
url = 'https://image.baidu.com/search/acJSON?tn=resultjson_com&logid=5853806806594529489&ipn=rj&ct=201326592&is=&fp=result&fr=ala&word={}&queryWord={}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&expermode=&nojc=&isAsync=&pn=30&rn=30&gsm=1e&1658411978178='.format(word, word)
print(url) 打开网址就是你输入的内容headers = {"User-Agent": 'Mozilla/5.0 (windows NT 10.0; Win64; x64) AppleWEBKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39'}判断该文件夹是否存在,存在则创建,不存在则覆盖;发送请求并打印源码
if not os.path.exists(files): #假如没有文件执行以下代码:
os.makedirs(files) #有文件夹则覆盖,没有则创建
req=requests.get(url=url,headers=headers).text #获取源码
print(req) #输出源码正则式:
res='"thumbURL":"(.*?)"' #正则式
zhengze=re.findall(res,req) #调用findall函数进行匹配遍历url地址并发送请求
i=1 #计数
for a in zhengze: #遍历刷选后的网址 get_image(a,i) #将遍历后的url地址传到get-image这个函数
i+=1 #每执行一次加1
print(a) #打印地址
response=requests.get(url=a,headers=headers).content #获取二进制文件设置保存类型及保存位置
file=files+word+str(i)+'张.jpg' #设置 文件夹 路径+文件名以及类型 (完整地址)
with open(file,'wb') as f: #写二级制文件类型,并修改变量名
f.write(response) #把获取到的二进制文件写入
print(word+str(i)+'张.jpg''保存成功') #提示保存成功那么接下来奉上完整源码:
import re #筛选url
import requests #请求
import os #创建文件夹
word = input('请输入要搜索的图片:')
url = 'Https://image.baidu.com/search/acjson?tn=resultjson_com&logid=5853806806594529489&ipn=rj&ct=201326592&is=&fp=result&fr=ala&word={}&queryWord={}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&expermode=&nojc=&isAsync=&pn=30&rn=30&gsm=1e&1658411978178='.format(word, word)
#伪装浏览器
headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39'}
files='D:/{}/'.format(word) #创建文件夹路径
if not os.path.exists(files): #假如没有文件执行以下代码:
os.makedirs(files) #有文件夹则覆盖,没有则创建
req=requests.get(url=url,headers=headers).text #获取源码
res='"thumbURL":"(.*?)"' #正则式
zhengze=re.findall(res,req) #筛选
i=1 #计数
for a in zhengze: #遍历刷选后的网址 get_image(a,i) #将遍历后的url地址传到get-image这个函数
i+=1 #每执行一次加1
print(a) #打印地址
response=requests.get(url=a,headers=headers).content #获取二进制文件
file=files+word+str(i)+'张.jpg' #设置 文件夹 路径+文件名以及类型 (完整地址)
with open(file,'wb') as f: #写二级制文件类型,并修改变量名
f.write(response) #把获取到的二进制文件写入
print(word+str(i)+'张.jpg''保存成功') #提示保存成功我们来看看运行结果怎么样:
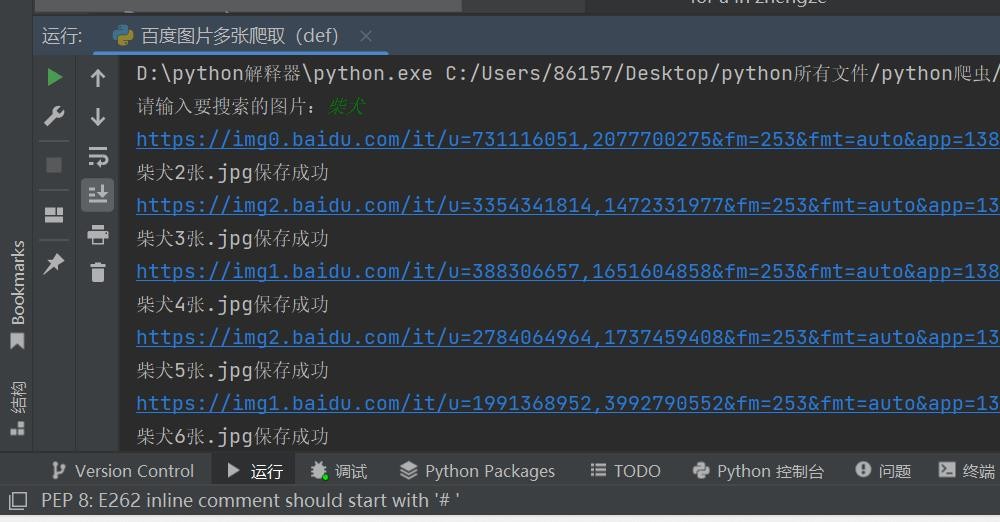
可以看到我搜索的是柴犬,对源码中的每个图片链接进行发送并保存。
那我保存的图片是否是柴犬呢?我们看看吧:
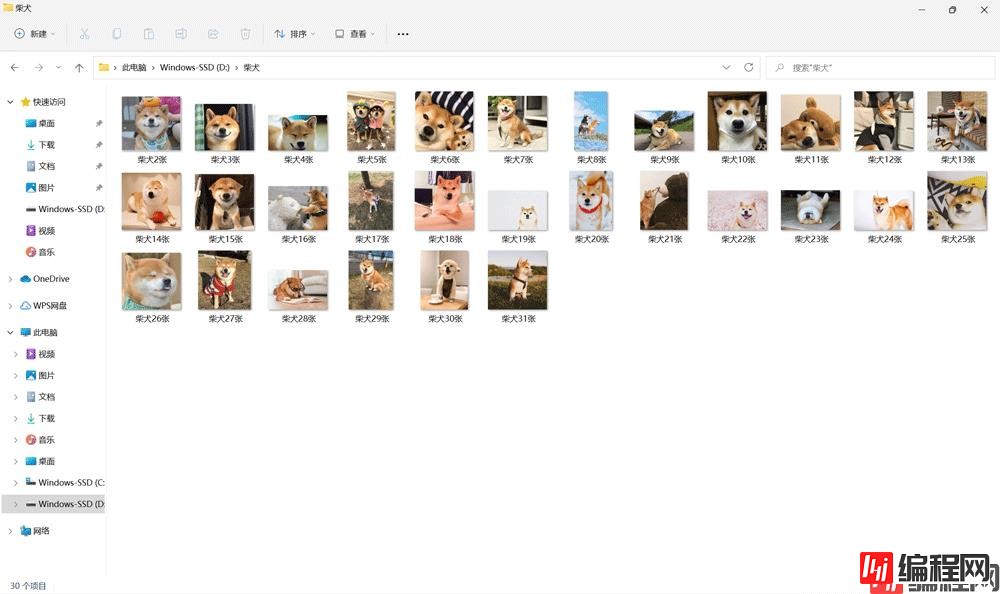
可以看到保存的就是柴犬图片并且创建了一个文件夹!
到此这篇关于python做图片搜索引擎并保存到本地详情的文章就介绍到这了,更多相关Python图片搜索引擎内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: python做图片搜索引擎并保存到本地详情
本文链接: https://www.lsjlt.com/news/119911.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0