Python 官方文档:入门教程 => 点击学习
正则表达式的使用 想要学习 python 爬虫 , 首先需要了解一下正则表达式的使用,下面我们就来看看如何使用。 . 的使用这个时候的点就相当于一个占位符,可以匹配任意一个字符,什么意思呢?看个例子就知道
正则表达式的使用
想要学习 python 爬虫 , 首先需要了解一下正则表达式的使用,下面我们就来看看如何使用。
. 的使用这个时候的点就相当于一个占位符,可以匹配任意一个字符,什么意思呢?看个例子就知道
import re
content = "helloworld"
b = re.findall('w.',content)
print b`
注意了,我们首先导入了 re,这个时候大家猜一下输出结果是什么?因为 . 相当于一个占位符,所以理所当然的这个时候的输出结果是 wo 。
* 的使用跟上面的 . 不同,* 可以匹配前一个字符任意次数,看个例子
content = "helloworldhelloworld"
b = re.findall('w*',content)
print b
这个时候的输出结果是 ['', '', '', '', '', 'w', '', '', '', '', '', '', '', '', '', 'w', '', '', '', '', ''],可见是一个列表,长度和匹配的字符串一致,遇到要匹配的字符就打印出来。
.* 的使用.* 是一种组合使用,它可以尽可能多的匹配内容,比如下面这个例子
content = "helloworldhelloworldworld"
b = re.findall('he.*ld',content)
print b
它会输出 ['helloworldhelloworldworld'],它为什么不只打印一个 helloworld,为什么全部打印下来了?这就是一种贪心算法,也就是说我要找到最长的那个符合条件的内容。
.*? 的使用与 上面相反,这个符号会找到尽可能短的符合条件的内容,然后放到一个列表中去,如下所示
content = 'xxhelloworldxxxxhelloworldxx'
b = re.findall('xx.*?xx',content)
print b
输出的结果为 ['xxhelloworldxx', 'xxhelloworldxx'],可见,有个 xx 在前面好烦,怎么才能去掉呢?很简单,加个括号即可,括号加在哪?
content = 'xxhelloworldxxxxhelloworldxx'
b = re.findall('xx(.*?)xx',content)
print b
以上我们讨论的都是内容不包含换行符的情况,如果有了换行符结果又会发生什么变化呢?
content = '''xxhelloworld xx'''
b = re.findall('xx(.*?)xx',content)
print b
这个时候的输出结果为一个空列表,那怎么办啊?如果我们写网络爬虫的时候,网页源代码肯定不止是一行啊,如果换一行我们就读不出来了,那就好尴尬了,当然有解决办法~
content = '''xxhelloworld xx'''
b = re.findall('xx(.*?)xx',content,re.S)
print b
这样就可以了,还有一个非常方便的提取数字的技巧,如下所示
content = '''xx123456 xx'''
b = re.findall('(d+)',content,re.S)
print b
在网页源代码中爬取图片链接并下载
这篇文章中只是网络爬虫的第一步,所以讲解的也比较浅,所以现在我们先来利用正则表达式实现一个手动的网络爬虫,什么是手动的呢?就是我们自己把网页源代码复制下来,保存在一个 txt 文件中,然后利用正则表达式去过滤信息,然后去下载。
首先我搜索了一下 linux 桌面,然后找到了如下一个网页
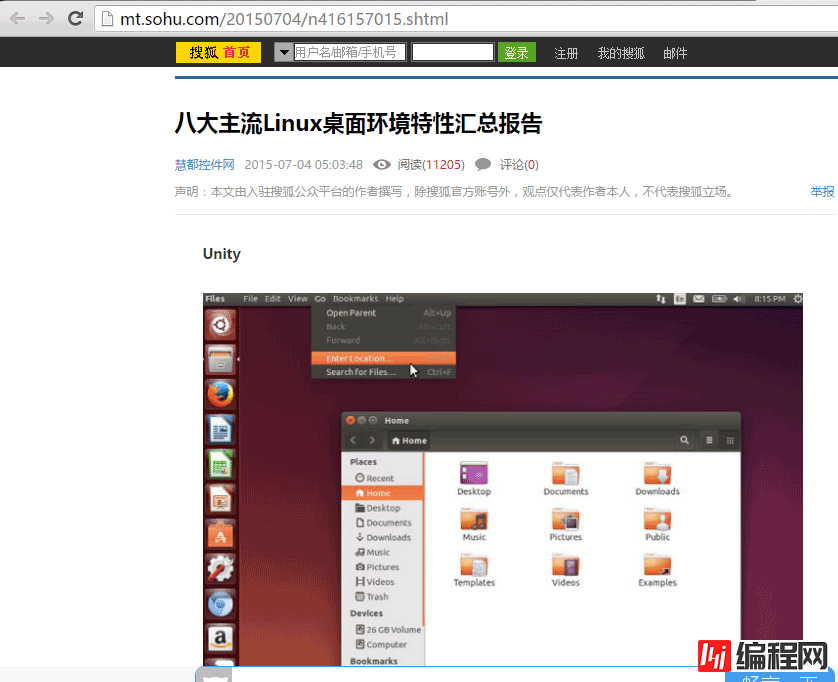
右击查看网络源代码,按 ctrl+f 搜索 img src 找到中间一部分进行复制,并且粘贴到一个 txt 文件中去,
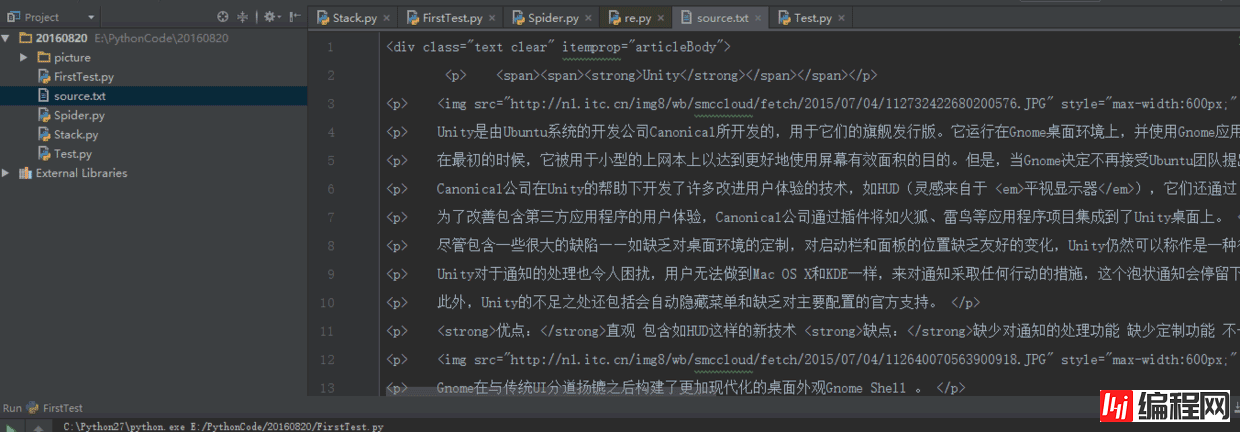
然后就可以利用我们上述的知识去提取我们想要的信息,源代码如下
import re import requests
f = open('source.txt', 'r')
html = f.read()
f.close()
pattern = '<img src="(.*?)"'
pic_url = re.findall(pattern, html, re.S)
i = 0
for each in pic_url:
print 'Downloading :' + each
pic = requests.get(each)
fp = open('picture\' + str(i) + '.jpg', 'wb')
fp.write(pic.content)
fp.close()
i = i + 1
首先打开我们保存网络源代码的 txt文件,进行读取,关闭文件流,然后就是利用正则表达式提取图片链接,最后利用requests 中的 get() 方法进行图片下载,注意这个 requests 不是Python 中自带的,我们需要下载指定的文件,然后将其放入到 Python 的Lib 目录下,此处下载,进入网站后,按ctrl+f 搜索关键词 requests 就可以看到如下页面

,可以看出,我们下载的是 .whl 后缀的文件,手动将其改成 .zip 后缀,然后解压,就可以得到两个目录,将名为 requests 的目录复制粘贴到上面讲的目录即可使用。
好了介绍完了,我们去看下运行结果
C:Python27python.exe E:/PythonCode/20160820/Spider.py
Downloading:Http://n1.itc.cn/img8/wb/smccloud/fetch/2015/07/04/112732422680200576.JPG
Downloading :http://n1.itc.cn/img8/wb/smccloud/fetch/2015/07/04/112640070563900918.JPG
Downloading :http://n1.itc.cn/img8/wb/smccloud/fetch/2015/07/04/112547718465744154.JPG
Downloading :http://n1.itc.cn/img8/wb/smccloud/fetch/2015/07/04/112455366330382227.JPG
Downloading :http://n1.itc.cn/img8/wb/smccloud/fetch/2015/07/04/112363014254719641.JPG
Downloading :http://n1.itc.cn/img8/wb/smccloud/fetch/2015/07/04/112270662197888742.JPG
Downloading :http://n1.itc.cn/img8/wb/smccloud/fetch/2015/07/04/112178310031994750.JPG
Downloading :http://n1.itc.cn/img8/wb/smccloud/fetch/2015/07/04/112085957910403853.JPG
Process finished with exit code 0
这个时候就下载成功了,到我们的 picture 目录下去查看下载的图片
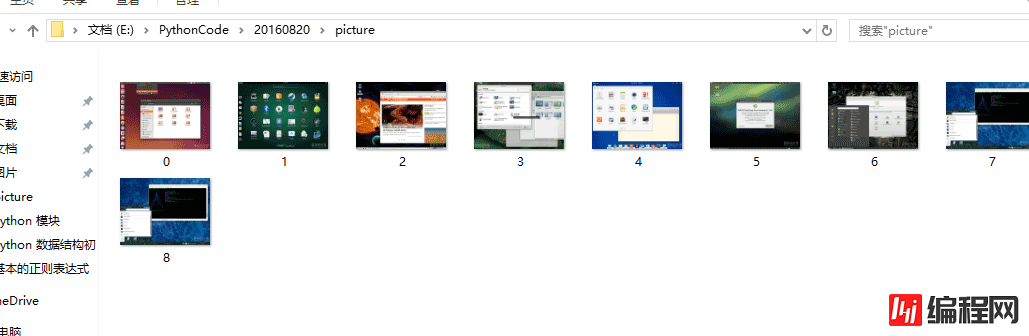
下载成功了。注意,自己找网页源代码实验的时候,最好不要让链接中带有中文,否则可能会出现乱码,由于我本身学习 Python 也才很短的时间,关于中文乱码问题,应对起来还不是那么得心应手,所以在此也就不再讲解,本文暂时告以段落,有意见或疑问可留言或者私聊我。
--结束END--
本文标题: Python 爬虫学习笔记之正则表达式
本文链接: https://www.lsjlt.com/news/14158.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0