Python 官方文档:入门教程 => 点击学习
这段时间看了数据分析方面的内容,对python中的numpy和pandas有了最基础的了解。我知道如果我不用这些技能做些什么的话,很快我就会忘记。想起之前群里发过一个学校的四六级成绩表,正好可以用来熟悉一下
这段时间看了数据分析方面的内容,对python中的numpy和pandas有了最基础的了解。我知道如果我不用这些技能做些什么的话,很快我就会忘记。想起之前群里发过一个学校的四六级成绩表,正好可以用来熟悉一下pandas中的一些用法。
1.数据介绍。
成绩表中包含的字段十分详细,里面有年级、性别、姓名、分数等等的一系列内容,我只想简单的分析一下我们学校的四六级过关率而已,所以去除了一些不必要的字段。留下的有如下几个字段:
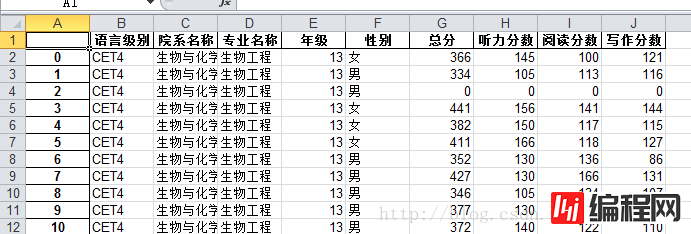
第一列是自增的序号,没有什么实际意义。
第二列就是代表着该学生参加的是四级还是六级。
第三列是我们学校的院系名称。
第四列是学校院系的各个专业。
第五列是年级,13代表着2013年入学。
第六列是性别。
后面的三列分别是总分、听力、阅读、写作等。
其中总分为0的都是缺考的。一共有接近9000条数据(没有报名的不在其中)。
2.预期结果。
我想利用这些数据最终通过图标的形式展示出以下几点:
1.各个学院的四六级平均分。
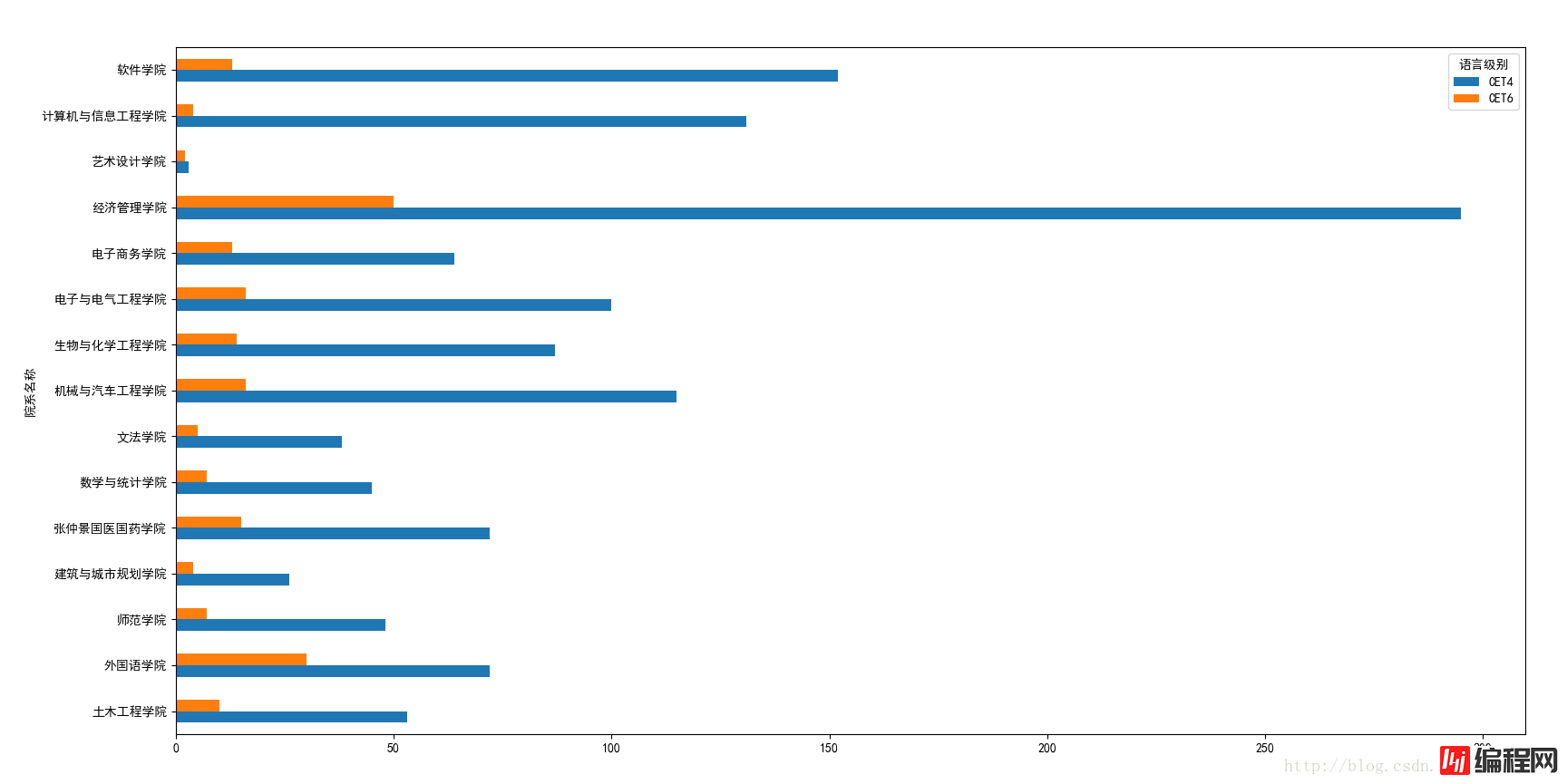
2.各个学院的四六级过关人数。
3.各个学院的各个年级过关人数。
4.各个年级的过关人数。
5.男生女生分别过关人数。
最终结果:
各个学院的四六级过关人数:
3.实现过程。
(1)导入依赖包。
程序分别使用了pandas进行分组转换,和matplotlib提供的绘图功能。
import pandas as pd
import matplotlib.pylab as plt
(2)加载数据。
想要分析数据自然要得到数据了,我将整理的数据存放在sj.xls中,是一个excel类型的数据。
这一步使用pandas的read_excel即可,生成一个DataFrame对象。
#加载全部数据
sj = pd.read_excel(r'F:DataAnalysissj.xls')加载完之后输出一下看看内容:
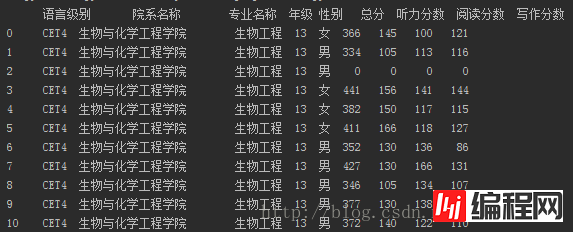
除了排版没有对齐之外其他都一样。
(3)统计各个学院平均分。
在这里就可以完成我们预期的第一个结果:
各个学院的四六级平均分:
想要各个学院的情况当然是要根据学院来进行分组了,同时也需要分出“CET4”和“CET6”两组。使用groupby即可,这样会生成一个SeriesGroupBy对象,然后再调用mean函数(默认是轴0计算,也就是我们想要的结果)即可统计出平均分情况。
#按照各个学院进行分组
xymean = sj['总分'].groupby([sj['院系名称'],sj['语言级别']])
#计算各个学院的平均分数
xymean = xymean.mean()
这个时候将其输出的话会得到如下结果:
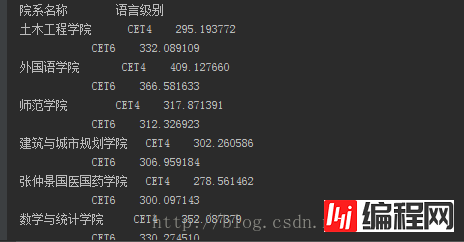
由于院系名称和语言级别是层次化索引的缘故,看起来并不是十分的友好,因此使用unstack将语言级别转从行转换为列。
xymean = xymean.unstack(level='语言级别')再次输出的话结果就比较清晰了
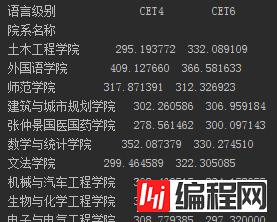
使用pandas的绘图功能进行绘图:
#使用横向柱状图显示
xymean.plot(kind='barh')
#在PyCharm中需要使用,在IPython环境中如果以--pylab形式打开就不需要
plt.show()
运行一下看看结果:
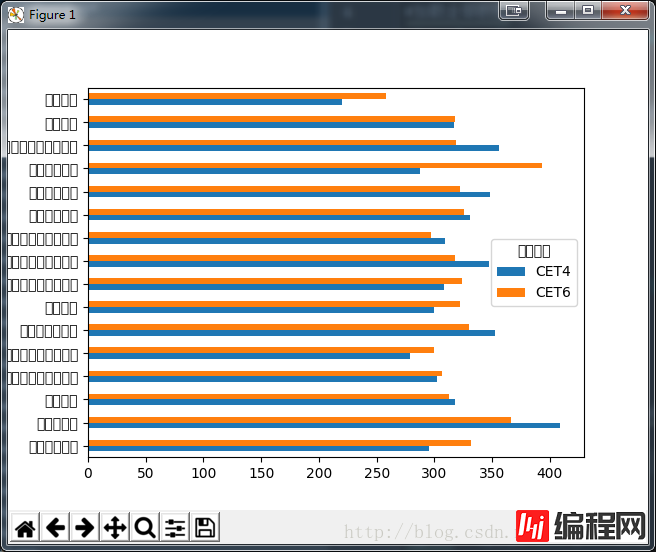
可以看到这时候数据的结果都能够显示出来了,但是中文部分出现了问题,不过不要紧,科学上网一查就解决了:https://GitHub.com/mwaskom/seaborn/issues/1009
添加一下代码即可:
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['font.serif'] = ['SimHei']
再次运行就OK了。
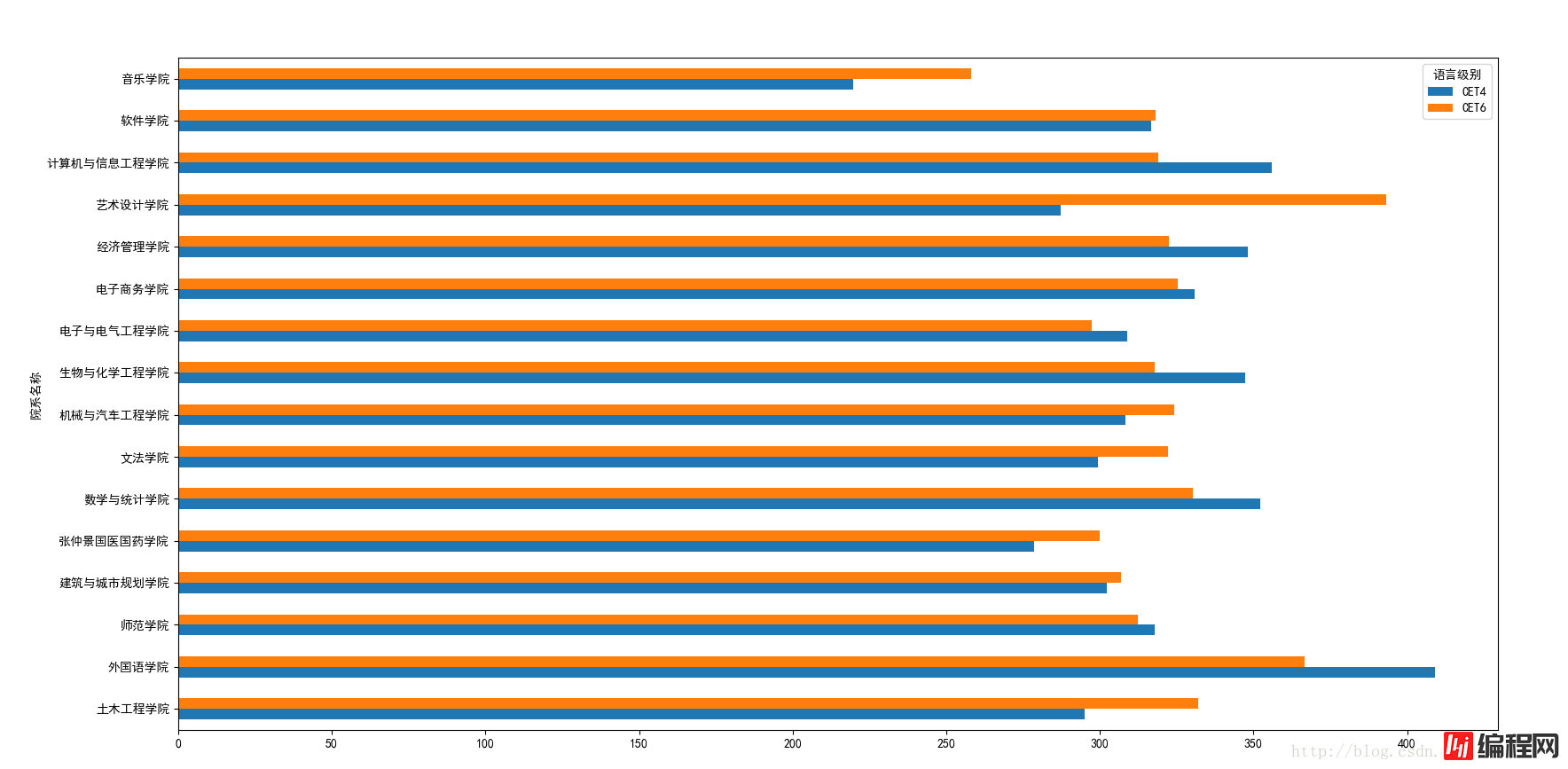
接下来要分析过关的情况了。
(4)筛选数据。
既然已经有了所有的数据内容了,下一步就是筛选出所有过关的人数了。
#过滤出过关人数
sjpass = sj[sj['总分'] >= 425]这时候sjpass存放的就是所有的过关人数了。
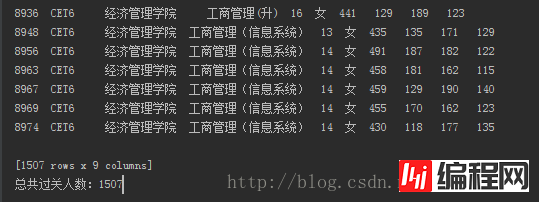
在输出结果的最下面就可以看到一共有1507行数据,当然也可以使用len()或者shape[0]查看共有多少行。
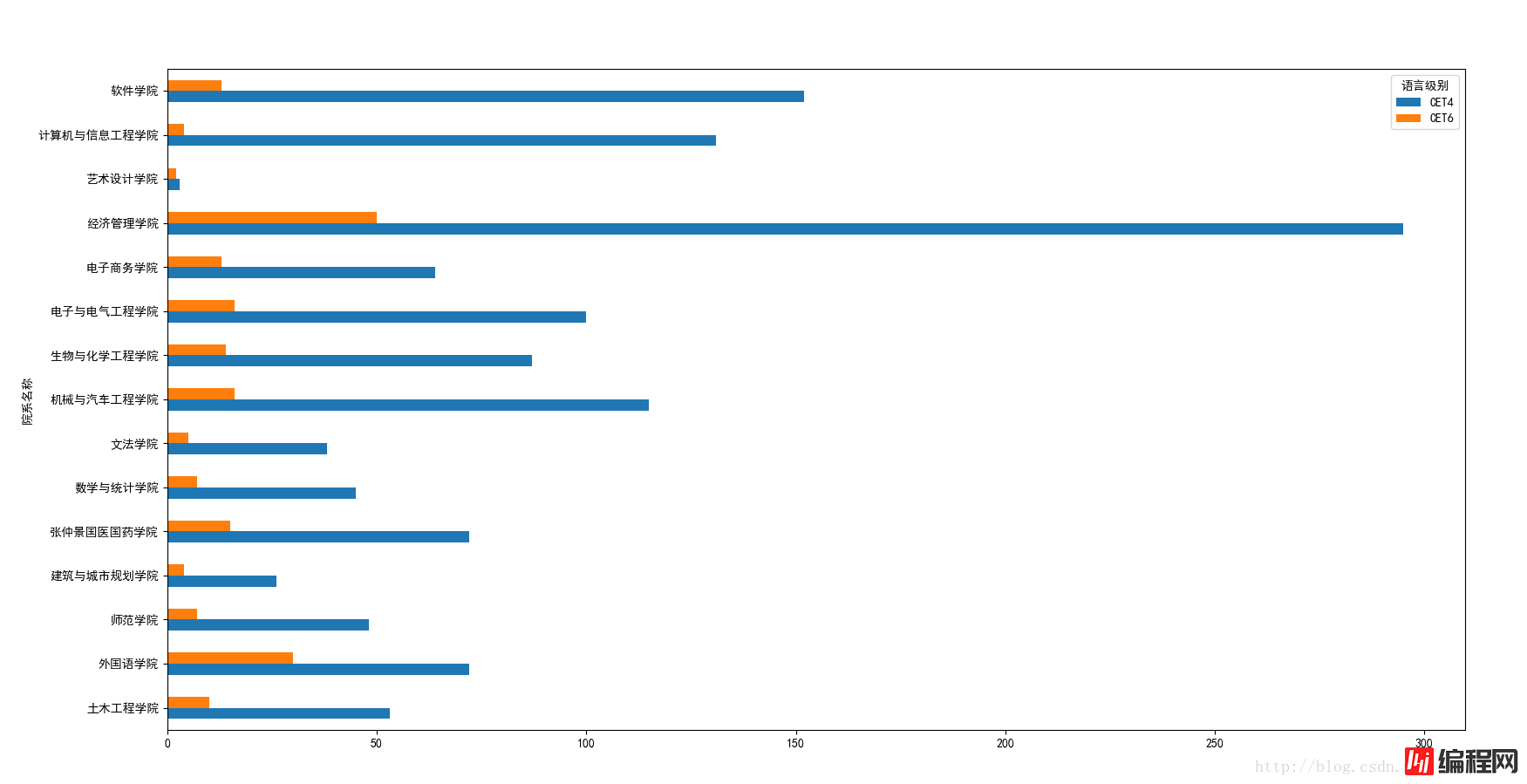
(5)各个学院的四六级过关人数。
已经有了全部过关人的数据了,接下来根据预期结果进行分组即可。同样的根据“院系名称”和“语言级别”对总分进行分组,然后使用count函数进行求和最后再用unstack进行调整绘图展示。
#按照各个学院进行分组
xypass = sjpass['总分'].groupby([sjpass['院系名称'],sjpass['语言级别']])
#计算各个学院的过关总人数
xypass = xypass.count()
#将语言级别作为columns
xypass = xypass.unstack(level='语言级别')
#进行绘图
xypass.plot(kind='barh')
plt.show()
绘图结果:
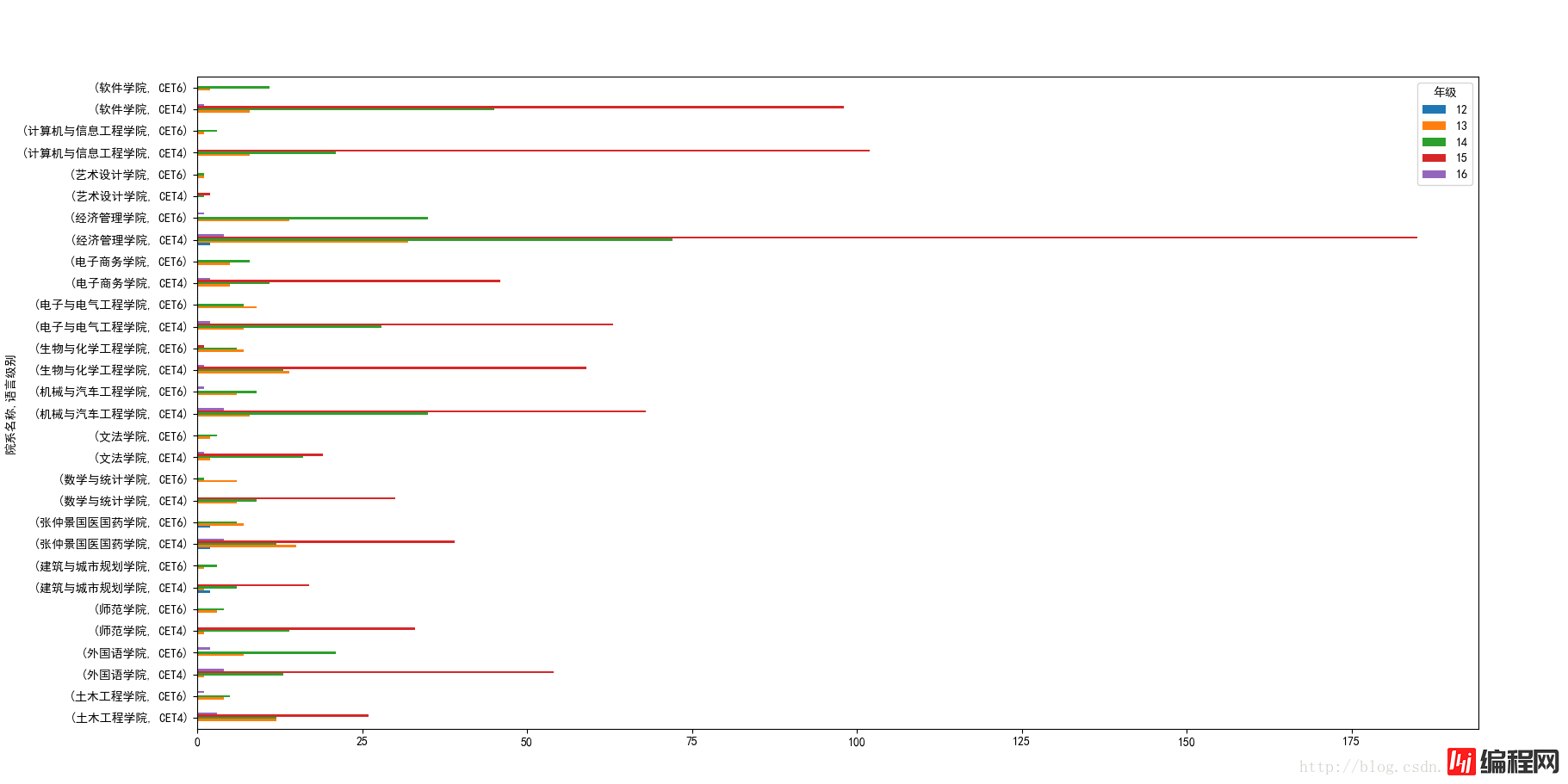
(6)各个学院的各个年级过关人数。。
这次分组的时候加上年级即可,并且为了绘图比较好看一点,这次可以将“年纪”转换为列,并且像12年这种的有些学员已经没有人参加了,所以需要将缺失值用0填充:
#按照各个学院和年级进行分组
xypass = sjpass['总分'].groupby([sjpass['院系名称'],sjpass['语言级别'],sjpass['年级']])
#计算各个学院的过关总人数
xypass = xypass.count()
#将语言级别作为columns,并且将缺失值用0进行填充
xypass = xypass.unstack(level='年级').fillna(0)
xypass.plot(kind='barh')
plt.show()
绘图结果:
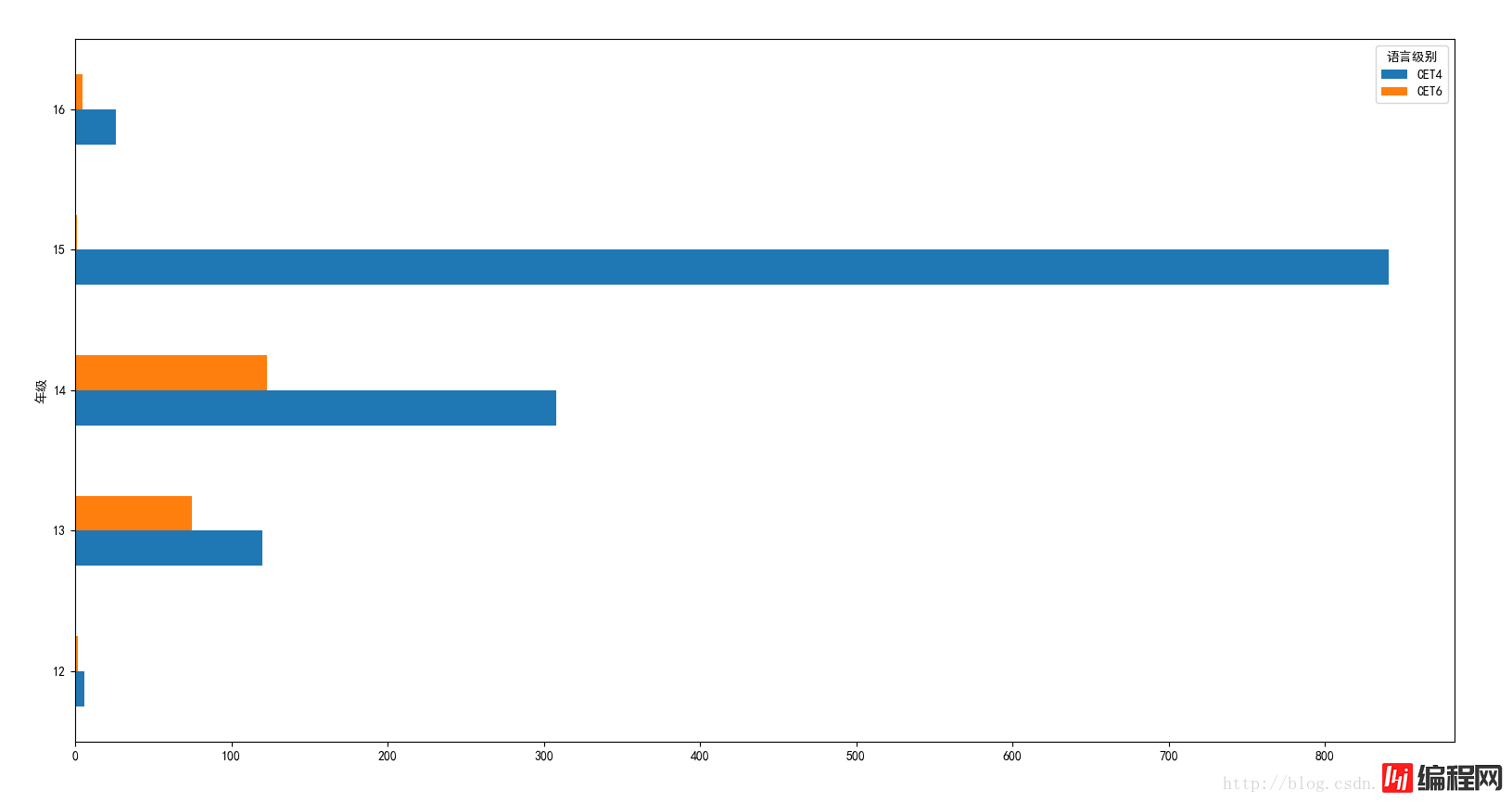
(7)各个年级的过关人数。
使用groupby对年级进行分组即可:
#-----------------各个年级过关人数------------------
njpass = sjpass['总分'].groupby([sjpass['年级'],sjpass['语言级别']]).count().unstack(level='语言级别')
njpass.plot(kind='barh')
plt.show()
绘图结果:
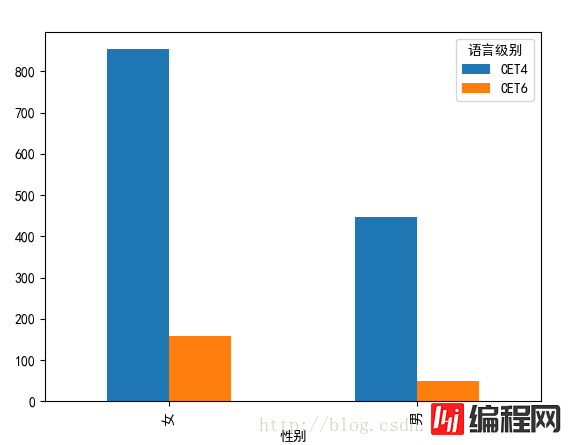
(8)男生女生分别过关人数。
将性别和语言级别进行分组:
#---------------男生女生过关情况----------------------
nvpass = sjpass['总分'].groupby([sjpass['性别'],sjpass['语言级别']]).count().unstack(level='语言级别')
nvpass.plot(kind='bar')
plt.show()
绘图结果:
4.结果分析。
从绘图的结果上来看的话,各个学院之间音乐学院的平均分比较低,艺术设计和外国语学院的平均分都比较高,但是过关人数却没有那么的多,尤其是艺术设计的人数比较少,主要也是因为该学院的总人数比较少。
四级的过关人数明显比六级的人数多的多,而且因为15级是大二年级,在我们学校大二才可以参加四六级考试,所以过关的人数里面15级占有比较大的比分。
而且不得不承认,女生的过关率要比男生高的不止一点。
--结束END--
本文标题: Python分析学校四六级过关情况
本文链接: https://www.lsjlt.com/news/15913.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0