Python 官方文档:入门教程 => 点击学习
目录一、Pandoc转换1.1 问题1.2 下载1.3 md转docx1.4 md转pdf二、python库实现2.1 安装 wkhtmltopdf2.2 安装 mdutils2.3
由于我们markdown编辑器比较特殊,一般情况下,我们不太好看,如果转换成pdf的话,我们就不需要可以的去安装各种编辑器才可以看了,所以我们有了md转pdf或者是docx的需求。
资源地址
安装后,本地查看版本,是否安装成功:

出现如上图表示安装成功。
cd进入我们需要转换的文件目录下,输入:
pandoc xxx.md -s -o xxxx.docx
-s:生成恰当的文件头部和底部。
-o:指定输出的文件。
查看实际效果:


此时发现文件已经生成好.我们打开看下,

整体转换效果还是不错的。
pandoc xxx.md -o xxxx.pdf --pdf-engine=xelatex
使用 Typora可以直接转换
结合 wkhtmltopdf 使用 markdown 库 和 pdfkit 库
wkhtmltopdf 下载地址
pip install markdown
pip install pdfkit参考案例:
import pdfkit
from markdown import markdown
input = r"F:\csdn博客\PyTorch\【Pytorch】pytorch安装.md"
output = r"【Pytorch】pytorch安装.pdf"
with open(input, encoding='utf-8') as f:
text = f.read()
html = markdown(text, output_fORMat='html') # MarkDown转HTML
htmltopdf = r'D:\htmltopdf\wkhtmltopdf\bin\wkhtmltopdf.exe'
configuration = pdfkit.configuration(wkhtmltopdf=htmltopdf)
pdfkit.from_string(html, output_path=output, configuration=configuration, options={'encoding': 'utf-8'}) # HTML转PDF
但是我们此时存在一个问题,如果我们的md中有表格的话,如图:
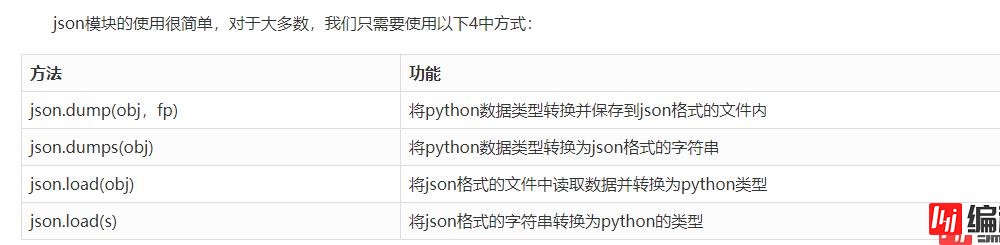
那么转换之后会发现是乱的:

我们此时需要设定参数,修改为如下:
html = markdown(text, output_format='html',extensions=['tables'])
我们再看下效果:

pip install python-markdown-math
import pdfkit
from markdown import markdown
input_filename = 'xxxx.md'
output_filename = 'xxxx.pdf'
html = '<!DOCTYPE html><body><link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/katex/dist/katex.min.CSS" rel="external nofollow" crossorigin="anonymous"><script src="Https://cdn.jsdelivr.net/npm/katex/dist/katex.min.js" crossorigin="anonymous"></script><script src="https://cdn.jsdelivr.net/npm/katex/dist/contrib/mathtex-script-type.min.js" defer></script>{}</body></html>'
text = '$$E=mc^2$$'
text = markdown(text, output_format='html', extensions=['mdx_math']) # MarkDown转HTML
html = html.format(text)
pdfkit.from_string(html, output_filename, options={'encoding': 'utf-8'}) # HTML转PDF
import pdfkit
pdfkit.from_file('xxx.html', 'xxxx.pdf', options={'encoding': 'utf-8'}) # HTML转PDF
pip install pymdown-extensions
progressbar.css
.progress-label {
position: absolute;
text-align: center;
font-weight: 700;
width: 100%;
margin: 0;
line-height: 1.2rem;
white-space: nowrap;
overflow: hidden;
}
.progress-bar {
height: 1.2rem;
float: left;
background-color: #2979ff;
}
.progress {
display: block;
width: 100%;
margin: 0.5rem 0;
height: 1.2rem;
background-color: #eeeeee;
position: relative;
}
.progress.thin {
margin-top: 0.9rem;
height: 0.4rem;
}
.progress.thin .progress-label {
margin-top: -0.4rem;
}
.progress.thin .progress-bar {
height: 0.4rem;
}
.progress-100plus .progress-bar {
background-color: #00e676;
}
.progress-80plus .progress-bar {
background-color: #fbc02d;
}
.progress-60plus .progress-bar {
background-color: #ff9100;
}
.progress-40plus .progress-bar {
background-color: #ff5252;
}
.progress-20plus .progress-bar {
background-color: #ff1744;
}
.progress-0plus .progress-bar {
background-color: #f50057;
}
progressbar.py
from markdown import markdown
filename = 'progressbar.md'
html = '''
<!DOCTYPE html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1, minimal-ui">
<title>progressbar</title>
<link rel="stylesheet" href="progressbar.css" rel="external nofollow" >
</head>
<body>
{}
</body>
</html>
'''
encoding = 'utf-8'
with open(filename, encoding=encoding) as f:
text = f.read()
extensions = [
'markdown.extensions.attr_list',
'pymdownx.progressbar'
]
text = markdown(text, output_format='html', extensions=extensions) # MarkDown转HTML
html = html.format(text)
print(html)
with open(filename.replace('.md', '.html'), 'w', encoding=encoding) as f:
f.write(html)
# pdfkit.from_string(html, output, options={'encoding': 'utf-8'}) # HTML转PDF
print('完成')
progressbar.md
[=0% "0%"]
[=5% "5%"]
[=25% "25%"]
[=45% "45%"]
[=65% "65%"]
[=85% "85%"]
[=100% "100%"]
[=85% "85%"]{: .candystripe}
[=100% "100%"]{: .candystripe .candystripe-animate}
[=0%]{: .thin}
[=5%]{: .thin}
[=25%]{: .thin}
[=45%]{: .thin}
[=65%]{: .thin}
[=85%]{: .thin}
[=100%]{: .thin}
我们看下最后的实际效果:

到此这篇关于Python实战之markdown转pdf(包含公式转换)的文章就介绍到这了,更多相关Python markdown转pdf内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python实战之markdown转pdf(包含公式转换)
本文链接: https://www.lsjlt.com/news/159966.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0