帝国cms是我们用得比较多得PHP的建站系统,在建站过程中,如果自己没有信息源,只能靠手工不断的重复copy和粘贴,这样费时费力,于是我们就要使用帝国cms自带的采集功能来完成信息的录入。为了深入了解帝国cms采集功能,
帝国cms是我们用得比较多得PHP的建站系统,在建站过程中,如果自己没有信息源,只能靠手工不断的重复copy和粘贴,这样费时费力,于是我们就要使用帝国cms自带的采集功能来完成信息的录入。为了深入了解帝国cms采集功能,下面我们以“新浪各地新闻”栏目为例来进行实战采集。
一、增加采集节点
1、添加节点:

2、选择要增加采集的栏目:

3、进入增加节点表单:
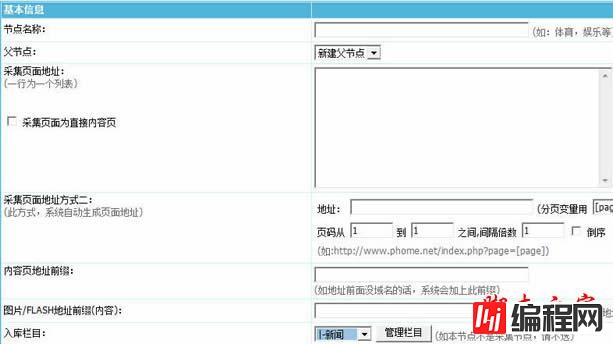
4、在节点名称框里起个名字,然后把要采集的新浪各地新闻列表地址copy过来:
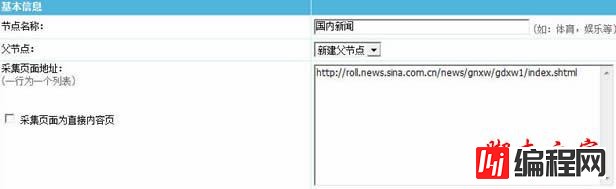
5、下来发现好多选项,如“采集页面地址方式二,内容页地址前缀...”先不要理他,后面再一一详解,直接拉到 “信息链接区域正则”这里:

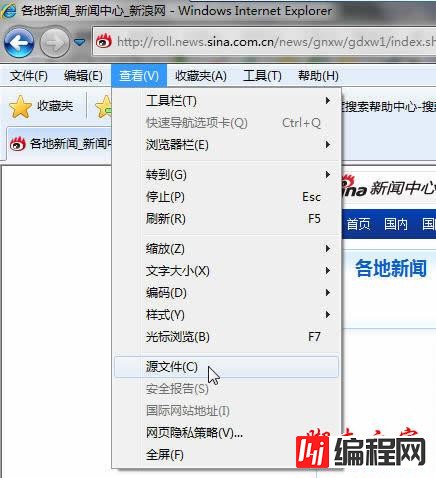
6、这里是设置采集的列表信息链接区域正则,我们点击查看新浪各地新闻列表“源文件”:
7、把源文件代码copy到Dreamweaver里,在Dreamweaver里选定要采集的信息链接区域:

8、切换到Dreamweaver代码方式,

9、得到信息链接区域正则:

10、得到信息页链接正则:
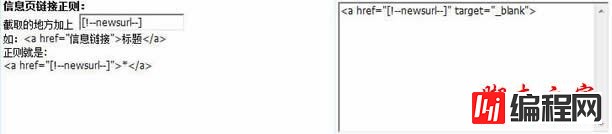
11、注意:如果信息页链接是相对地址,例如< a href="/c/2012-03-05/205924063527.shtml" target="_blank" >,那么“内容页地址前缀”要加域名:
12、现在要采集内容页的标题和内容:

13、查看新闻页“源文件”,找title标签:
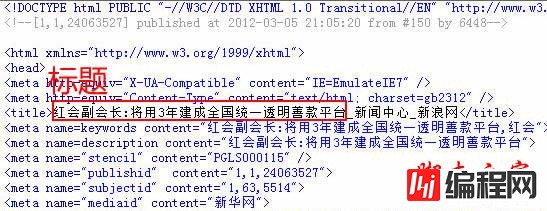
14、取得标题正则:

15、这里是要采集的内容区域:

16、取得新闻内容正则:
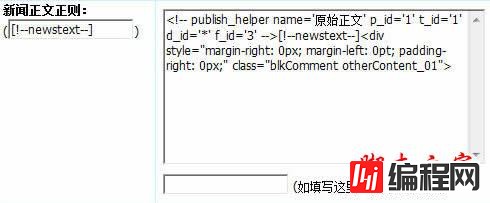
(注意:新闻内容正则里的 d_id='*' 用了通配符,因为每一篇新闻的d_id值是不同的,所以可以用*来代替它,“*”可以代替任意字符。)
17、点击提交按钮就完成了整个采集节点:
二、预览采集节点是否正确
1、提交按钮后返回管理节点:

2、点击“预览”采集,进入节点预览结果:
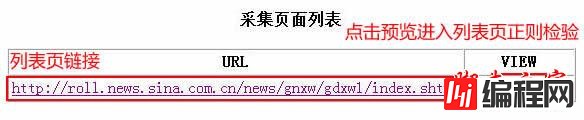
3、采集内容页列表

4、采集内容页页面:

三、采集
1、预览采集节点无误后,然后返回“管理节点”,点击“开始采集”链接就开始进行采集:

2、系统正在采集中:

3、采集完后显示本地临时入库的信息,这时可以对临时入库的信息进行修改或者删除:
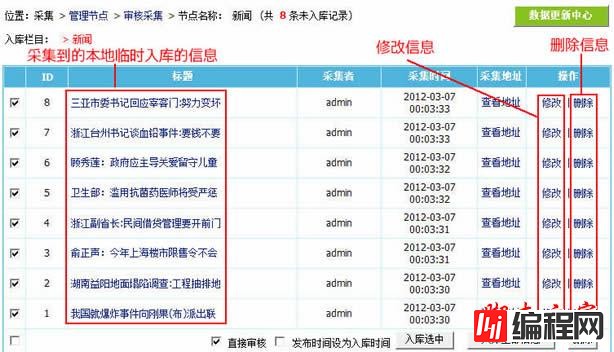
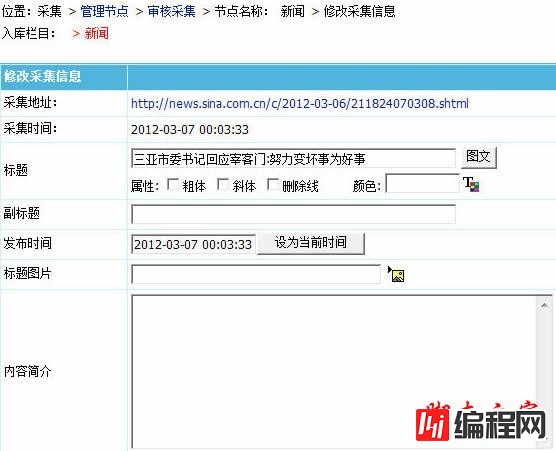
4、修改信息页面如图:
5、对采集的信息进行审核并入库,点击“入库全部信息按钮”:
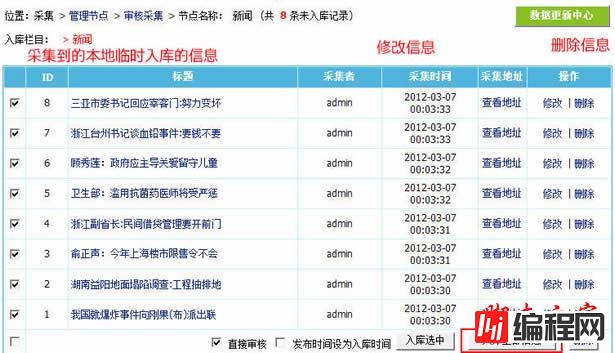
6、确定操作:

7、信息入库完毕提示:

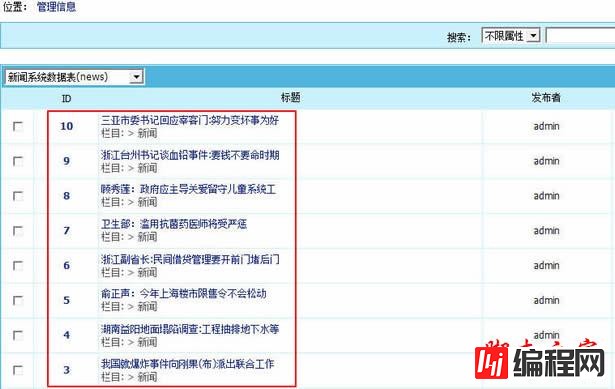
信息入库完毕后下来点击”管理信息“:

我们可以看到刚刚采集入库的新闻信息:
最后到“数据更新”刷新首页、栏目、和内容页就可以完成网站的信息采集了。由于帝国cms采集功能非常强大,一时半刻也说不完,下一页将继续讲解其他功能的使用和技巧。
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列出来了。
1、我们以“中华网内容分页(Http://auto.china.com/dongtai/yejie/11012724/20120309/17081442.html)”为例:
可以看到这条新闻总共有3条分页。
2、查看源代码:
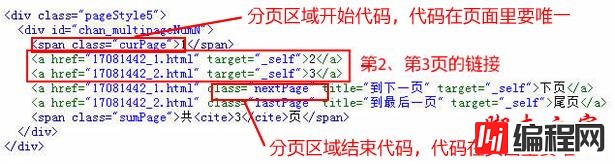
这一页里除了已经采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列出来了。
3、取得 分页区域正则([!--smallpageallzz--]):

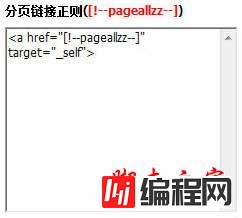
4、取得 分页链接正则([!--pageallzz--]):
二、上下页导航式
上下页导航式是分页采集的难点,他需要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比分析然后确定分页正则。
1、我们以“爱丽网内容分页(http://fashion.aili.com/76/445845.html)”为例:
可以看到这条新闻总共有20条分页。
2、查看源代码:

这一页里除了已经采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列出来,这时候我们拿用第1页和第2页的代码来进行对比分析,来确定分页正则:
(1)第1页代码:

(2)第2页代码:

从这两幅图片可以看到他们有着相同的“分页区域开始代码”,“分页链接”格式,“分页区域结束代码”,那么就可以确定“分页区域正则”,“分页链接正则”。
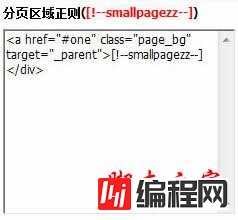
3、取得 分页区域正则([!--smallpageallzz--]):
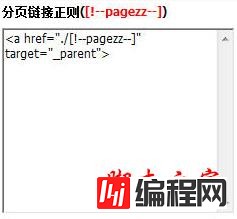
4、取得 分页链接正则([!--pageallzz--]):
5、为了方便教程显示,newstext我采集了标题而不是采集内容,预览结果:

注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列出来的情况下我们使用“全部列出式”。在第一页的页面HTML代码里,内容分页链接没有全部列出来的情况下我们使用“上下页导航式”。
第二、用全部列出式时,采集规则正确但是莫名其妙的出现重复的分页,这时可以利用替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时,老是采到第1页,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环到底,这也是因为分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
好的,这一讲就到这里,下一页我们主要介绍帝国cms采集过滤和替换。
前两讲我们分别介绍了帝国cms采集基本流程和帝国cms如何采集内容分页,最后这一讲主要介绍帝国cms采集过滤与替换,还有些技巧。
一、过滤
1、帝国cms采集过滤分为两种:
(1)“整体页面过滤正则”:

(2)“过滤广告正则”:

我们有些疑惑,这两种过滤到底有什么区别?“整体页面过滤正则”是过滤整个网页的html代码。“过滤广告正则”是过滤文章内容,仅对文章内容([!--newstext--])起作用。
2、过滤实例:
过滤实例(1):
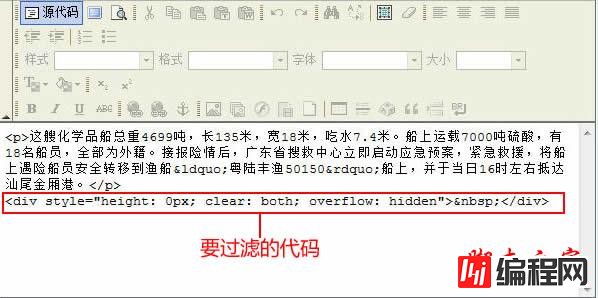
我们采集后发现信息内容底部多了行代码:“<div style="clear:both;height:0;visibility:hiDDDen;overflow:hidden;"> </div>”,根据格式“广告开始[!--ad--]广告结束”得到“过滤广告正则
”:

过滤实例(2):
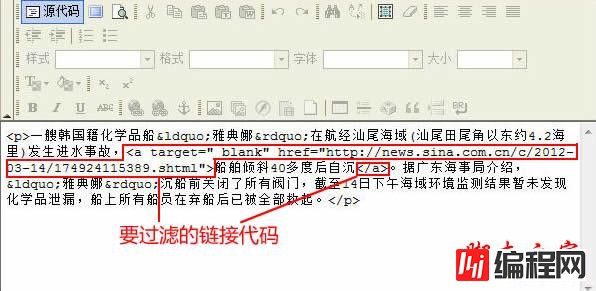
要过滤链接代码怎么办,注意“过滤广告正则”右边有堆代码:

鼠标先点击A,系统自动生成过滤链接代码“,,,”,这样就可以把采集后的内容链接过滤掉了。同理,如果想过滤其他html代码就点击相应的标签代码。
注意事项:当内容分页包含在内容([!--newstext--])里时,要过滤掉内容分页,否则会重复出现内容分页。
二、替换
1、帝国cms采集替换也分为两种:
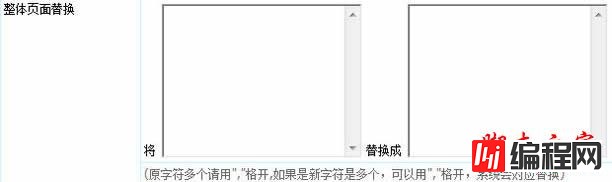
(1)“整体页面替换”:
(2)“替换”:
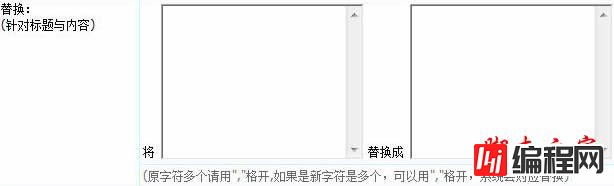
他们两种区别:“整体页面替换”是替换整个网页的html代码。“替换”是替换文章标题和内容,仅对标题([!--title--])和([!--newstext--])起作用。
2、替换实例:
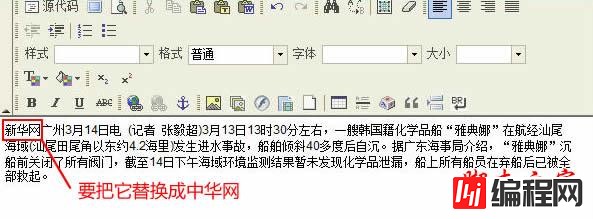
我们要把内容里的“新华网”替换成“中华网”:
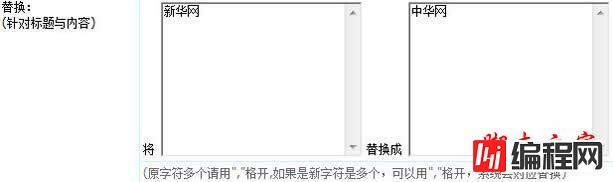
预览下:
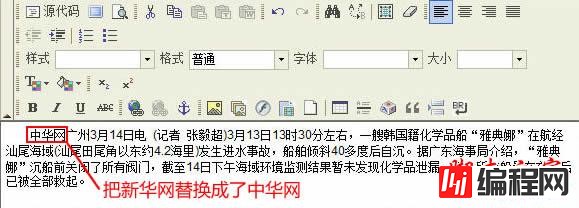
没有问题,替换过来了。
三、图片采集
(1)我们采集时会碰到信息内容可以正常采集,但是里面的图片却不显示,例子:
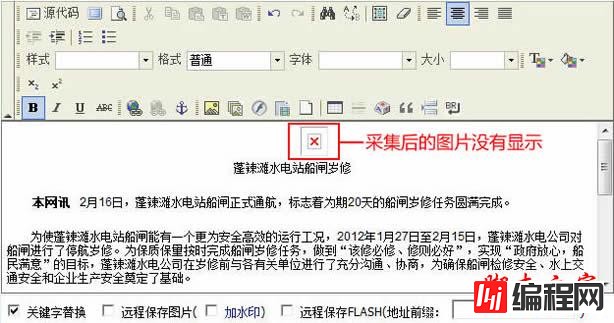
信息内容可以正常采集,就是图片不显示出来,这是由于内容图片的路径不对,图片的路径为相对地址。
(2)查看源代码:
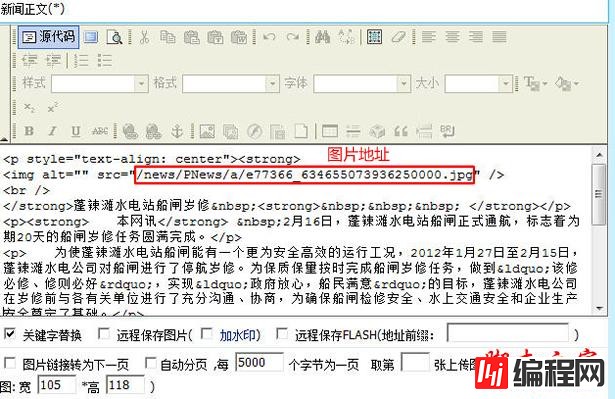
图片是相对地址,要换成绝对地址才能采集成功。
(3)替换成绝对地址:
先在目标站的图片右键查看属性:
目标站的图片地址为“http://www.gdyd.com/news/PNews/a/e77366_634655073936250000.jpg”,我们采集所到的图片地址为“/news/PNews/a/e77366_634655073936250000.jpg”,分析得到前缀“http://www.gdyd.com”,我们把前缀放到“图片/FLASH地址前缀(内容)”,如下图:
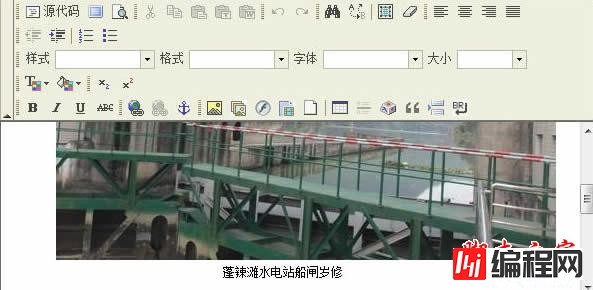
(4)前台预览图片:
图片显示出来了:
查看源代码:
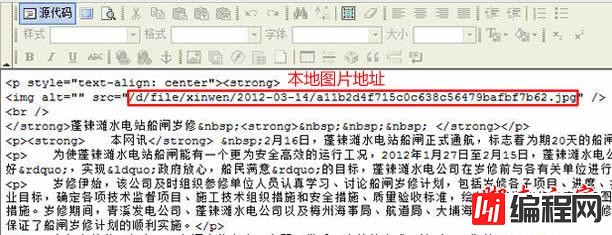
图片地址没错,是本地地址。
注意事项:我们在采集预览和在本地临时入库信息时,发现已经添加了图片地址前缀了,但是图片还是不显示,出现这个你不用理他,直接入库,入库了系统才会自动添加图片地址前缀。
至此采集实例讲解完毕,这三讲对帝国cms采集的基本流程,重点,难点基本都概括了,还有些基础的功能没能一一介绍清楚,大家可以到帝国官方网站看下基础教程。
本文由 国外网站大全http://www.kguowai.com 原创,转载请注明出处,谢谢!
--结束END--
本文标题: 帝国cms采集图文教程(上,中,下)全集
本文链接: https://www.lsjlt.com/news/31902.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-02-29
2024-02-29
2024-02-27
2023-10-27
2023-10-26
2023-10-25
2023-10-21
2023-10-21
2023-10-18
2023-10-12
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作



0