这篇文章主要介绍了pyspark dataframe列的合并与拆分方法是什么的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇pyspark dataframe列的合并与拆分方法是什么文章都会有
这篇文章主要介绍了pyspark dataframe列的合并与拆分方法是什么的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇pyspark dataframe列的合并与拆分方法是什么文章都会有所收获,下面我们一起来看看吧。
使用Spark sql在对数据进行处理的过程中,可能会遇到对一列数据拆分为多列,或者把多列数据合并为一列。
这里记录一下目前想到的对DataFrame列数据进行合并和拆分的几种方法。
from pyspark.sql import SparkSessionspark = SparkSession.builder \ .master("local") \ .appName("dataframe_split") \ .config("spark.some.config.option", "some-value") \ .getOrCreate() sc = spark.sparkContextdf = spark.read.csv('hdfs://master:9000/dataset/dataframe_split.csv', inferSchema=True, header=True)df.show(3)原始数据如下所示
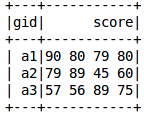
from pyspark.sql.functions import split, explode, concat, concat_wsdf_split = df.withColumn("s", split(df['score'], " "))df_split.show() 
zipWithIndex:给每个元素生成一个索引
排序首先基于分区索引,然后是每个分区内的项目顺序.因此,第一个分区中的第一个item索引为0,最后一个分区中的最后一个item的索引最大.当RDD包含多个分区时此方法需要触发spark作业.

first_row = df.first()numAttrs = len(first_row['score'].split(" "))print("新增列的个数", numAttrs)attrs = sc.parallelize(["score_" + str(i) for i in range(numAttrs)]).zipWithIndex().collect()print("列名:", attrs)for name, index in attrs: df_split = df_split.withColumn(name, df_split['s'].getItem(index))df_split.show() 
df_explode = df.withColumn("e", explode(split(df['score'], " ")))df_explode.show()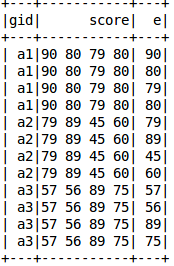
列的合并有两个函数:一个不添加分隔符concat(),一个添加分隔符concat_ws()
concat
df_concat = df_split.withColumn("score_concat", concat(df_split['score_0'], \ df_split['score_1'], df_split['score_2'], df_split['score_3']))df_concat.show() 
caoncat_ws
df_ws = df_split.withColumn("score_concat", concat_ws('-', df_split['score_0'], \ df_split['score_1'], df_split['score_2'], df_split['score_3']))df_ws.show()
pivot: 旋转当前[[dataframe]]列并执行指定的聚合
#DataFrame 数据格式:每个用户对每部电影的评分 userID 用户ID,movieID 电影ID,rating评分df=spark.sparkContext.parallelize([[15,399,2], \ [15,1401,5], \ [15,1608,4], \ [15,20,4], \ [18,100,3], \ [18,1401,3], \ [18,399,1]])\ .toDF(["userID","movieID","rating"])#pivot 多行转多列resultDF = df.groupBy("userID").pivot("movieID").sum("rating").na.fill(-1)#结果resultDF.show()pyspark中,dataframe与sql的耗时会经引擎优化,效率高于rdd,因此尽可能使用dataframe或者sql。执行效率之外,dataframe优于rdd的另一个好处是:dataframe的各个量有语义信息,便于后期维护。比如rdd[0][1][1]这种很难维护,但是,df.info.school.grade就容易理解。
在使用dataframe过程中,应尽量避免使用udf,因为序列化数据原本在JVM中,现在spark在worker上启动一个python进程,需要将全体数据序列化成Python可解释的格式,计算昂贵。
根据已有列生成新列
from pyspark.sql.functions import length, col, lit, sizedf.withColumn("length_col", length(col("existing_str_col"))) # 将existing_str_col的长度生成新列df.withColumn("constant_col", lit("hello")) # 生成一列常量df.withColumn("size_col", size(col("existing_array_col"))) # 将existing_array_col的元素个数生成新列从已有列选择部分列
from pyspark.sql.functions import coldf = df.select(col("col_1").cast("string"), col("col_2").alias("col_2_")) # 选择col_1列和col_2列,并将col_1列转换为string格式,将col_2列重命名为col_2_,此时不再存在col_2将几列连接起来形成新列
from pyspark.sql.functions import concat_ws df = df.withColumn("concat_col", concat_ws("_", df.col_1, df.col_2)) # 使用_将col_1和col_2连接起来,构成新列concat_col将string列分割成list
from pyspark.sql.functions import split df = df.withColumn("split_col", split(df.col, "-")) #按照-将df中的col列分割,此时split_col时一个list,后续或者配合filter(length(...))使用统计列均值
from pyspark.sql.functions import mean col_mean = df.select(mean(col)).collect()[0][0]从全体行中选择部分行(一般调试时使用)
print(df.take(5)) #交互式的pyspark shell中,等价于df.show(5)统计行数量
print(df.count()) #统计行数量从全体行中筛选出部分行
from pyspark.sql.functions import coldf = df.filter(col("col_1")==col("col_2")) #保留col_1等于col_2的行删除带null的行
df.na.drop("all") # 只有当所有列都为空时,删除该行df.na.drop("any") # 任意列为空时,删除该行df.na.drop("all", colsubset=["col_1","col_2"]) # 当col_1和col_2都为空时,删除该行去除重复行
df = df.distinct() # 删除所有列值相同的重复行df = df.dropDuplicates(["date", "count"]) # 删除date, count两列值相同的行一行拆分成多行
from pyspark.sql.functions import explode, split df = df.withColumn("sub_str", explode(split(df["str_col"], "_"))) # 将str_col按-拆分成list,list中的每一个元素成为sub_str,与原行中的其他列一起组成新的行填补行中的空值
df.na.fill({"col_name":fill_content}) # 用fill_content填补col_name列的空值行前加入递增(不一定连续)唯一序号
from pyspark.sql.functions import monotonically_increasing_id df = df.withColumn("id", monotonically_increasing_id())两个dataframe根据某列拼接
df_3 = df_1.join(df_2, df_1.col_1==df_2.col_2) # inner join, 只有当df_1中的col_1列值等于df_2中的col_2时,才会拼接df_4 = df_1.join(df_2, df_1.col_1==df_2.col_2, "left") # left join, 当df_1中的col_1值不存在于df_2中时,仍会拼接,凭借值填充null两个dataframe合并
df3 = df1.uNIOn(df2)groupByfrom pyspark.sql.functions import concat_ws, split, explode, collect_list, struct concat_df = concat_df.groupBy("sample_id", "sample_date").agg(collect_list('feature').alias("feature_list")) # 将同sample_id, sample_date的行聚合成组,feature字段拼成一个list,构成新列feature_list。agg配合groupBy使用,效果等于select。此时concat_df只有两列:sample_id和feature_list。concat_tuple_df = concat_df.groupBy("sample_id", "sample_date").agg(collect_list(struct("feature", "owner")).alias("tuple")) # 将同sample_id, sample_date的行聚合成组, (feature, owner)两个字段拼成一个单位,组内所有单位拼成一个list,构成新列tuple窗口函数
from pyspark.sql.window import Windowfrom pyspark.sql.functions import col, row_number windowspec = Window.partitionBy(df.id, df.date).orderBy(col("price").desc(), col("discount").asc()) # 相同id,date的行被聚成组,组内按照price降序,discount升序进行排列df = df.withColumn("rank", row_number().over(windowSpec)) #为排序之后的组进行组内编号df = df.filter(df.rank<=1) # 取组内top-1行from pyspark.sql import SparkSessionfrom pyspark import SparkContext sc = SparkContext(appName="test_rw")sc_session = SparkSession(sc)df.write.mode("overwrite").options(header="true").csv(output_path)df = sc_session.csv.read(input_path, header=True)from pyspark import SparkContextfrom pyspark.sql import SparkSession sc = SparkContext(appName='get_sample')sc_session = SparkSession(sc) sample_df.createOrReplaceTempView("item_sample_df")sample_df = sc_session.sql( ''' select sample_id ,label ,type_ as type ,split(item_id, "_")[2] as owner ,ftime from item_sample_df ''')from pysprak.sql.functions import udf, colfrom pyspark.sql.types import StringType, ArrayType, StructField, StructType def simple_func(v1, v2): pass # return str simple_udf = udf(my_func, StringType()) df = df.withColumn("new", simple_udf(df["col_1"], df["col_2"])) # 复杂type def get_entity_func(): pass # return str_list_1, str_list_2 entity_schema = StructType([ StructField("location", ArrayType(StringType()), True), StructField("nondigit", ArrayType(StringType()), True) ]) get_entity_udf = udf(get_entity_func, entity_schema)from pyspark import SparkContextfrom pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType, StructField, StringType, FloatType sc = SparkContext(appName="rdd2df")sc_session = SparkSession(sc) rdd = df.rdd # df转rdd, 注意每列仍带header,要map(lambda line: [line.id, line.price])才可以转换成不带header schema = StructType([ StructField("id", StringType(), True), StructField("price", FloatType(), True) ])df = sc_session.createDataFrame(rdd, schema) # rdd转df关于“pyspark dataframe列的合并与拆分方法是什么”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“pyspark dataframe列的合并与拆分方法是什么”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注编程网精选频道。
--结束END--
本文标题: pyspark dataframe列的合并与拆分方法是什么
本文链接: https://www.lsjlt.com/news/352760.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0