Redis-cluster的安装管理环境介绍系统环境:Red Hat Enterprise linux Server release 6.2 (SantiaGo)内核版本:Linux zxt-02.com
Redis-cluster的安装管理
环境介绍
系统环境:Red Hat Enterprise linux Server release 6.2 (SantiaGo)
内核版本:Linux zxt-02.com 2.6.32-220.el6.x86_64 #1 SMP Wed Nov 9 08:03:13 EST 2011 x86_64 x86_64 x86_64 GNU/Linux
软件版本:redis-3.0.5
主机名:redis-01.com、redis-02.com
主机IP:192.168.1.193 192.168.1.176
安装所需软件环境:
Zlib、ruby(必须1.9.2以上)、rubygem、gem-redis
注:在阅读文本文档之前需要读者知道的是本文档以及目前网络上的大部分相近的文档都来源于Http://redis.io。如果您的英文阅读能较好的话建议您阅读Reis官方文档。http://redis.io/topics/cluster-spec
http://redis.io/topics/cluster-tutorial
Redis 集群是一个可以在多个Redis 节点之间进行数据共享的设施(installation)。Redis 集群不支持那些需要同时处理多个键的Redis 命令,因为执行这些命令需要在多个Redis 节点之间移动数据,并且在高负载的情况下,这些命令将降低Redis 集群的性能,并导致不可预测的行为。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability):即使集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令请求。
Redis 集群提供了以下两个好处:
• 将数据自动切分(split)到多个节点的能力。
• 当集群中的一部分节点失效或者无法进行通讯时,仍然可以继续处理命令请求的能力
Redis 集群没有使用一致性hash, 而是引入了哈希槽的概念.
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
l 节点 A 包含 0 到 5500号哈希槽
l 节点 B 包含5501 到 11000 号哈希槽.
l 节点 C 包含11001 到 16384号哈希槽.
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我像移除节点A,需要将A中得槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可.
由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有N-1个复制品.
在我们例子中具有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用.
然而如果在集群创建的时候(或者过一段时间)我们为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了
不过当B和B1 都失败后,集群是不可用的.
Redis 并不能保证数据的强一致性. 这意味这在实际中集群在特定的条件下可能会丢失写操作.
第一个原因是因为集群是用了异步复制. 写操作过程:
客户端向主节点B写入一条命令.
主节点B向客户端回复命令状态.
主节点将写操作复制给他得从节点 B1, B2 和 B3.
主节点对命令的复制工作发生在返回命令回复之后, 因为如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低 —— 我们必须在性能和一致性之间做出权衡。
注意:Redis 集群可能会在将来提供同步写的方法。
Redis 集群另外一种可能会丢失命令的情况是集群出现了网络分区, 并且一个客户端与至少包括一个主节点在内的少数实例被孤立。.
举个例子 假设集群包含 A 、 B 、 C 、 A1 、 B1 、 C1 六个节点, 其中 A 、B 、C 为主节点, A1 、B1 、C1 为A,B,C的从节点, 还有一个客户端 Z1
假设集群中发生网络分区,那么集群可能会分为两方,大部分的一方包含节点 A 、C 、A1 、B1 和 C1 ,小部分的一方则包含节点 B 和客户端 Z1 .
Z1仍然能够向主节点B中写入, 如果网络分区发生时间较短,那么集群将会继续正常运作,如果分区的时间足够让大部分的一方将B1选举为新的master,那么Z1写入B中得数据便丢失了.
注意, 在网络分裂出现期间, 客户端 Z1 可以向主节点 B 发送写命令的最大时间是有限制的, 这一时间限制称为节点超时时间(node timeout), 是 Redis 集群的一个重要的配置选项:
redis-cluster要求最少需要3个节点,由于测试环境我这里使用两台虚拟机安装多个节点来模拟redis集群。
节点分配:
node1 192.168.1.193:6379
node2 192.168.1.193:6479
node3 192.168.1.193:6579
备机节点:
node1 192.168.1.176:6379
node2 192.168.1.176:6479
node3 192.168.1.176:6579
Zlib软件可以根据心情选择yum安装或者编译安装
Yum安装
[zxt@redis-01 ~]$ yum install -y zlib*
[zxt@redis-01 ~]$ rpm -qa |grep zlib
zlib-1.2.3-27.el6.x86_64
zlib-devel-1.2.3-27.el6.x86_64编译安装:
#download: http://www.zlib.net/
tar zxf zlib-1.2.7.tar.gz
cd zlib
./configure
make
make install
想要运行Redis cluter必须安装ruby并需安装1.9.2及以上版本。此处不要使用yum安装,因为RedHat6.2系统yum安装默认版本为1.8.7
#ruby-2.1.7.tar.gz
tar zxvf ruby-2.1.7.tar.gz
cd ruby-2.1.7
./configure -prefix=/usr/local/ruby
make
make install
cp ruby /usr/local/bin
# rubygems-1.8.5.tgz
tar zxvf rubygems-1.8.5.tgz
cd rubygems-1.8.5
ruby setup.rb
cp bin/gem /usr/local/bin安装运行redis集群所必需的redis和ruby的接口。
gem install redis --version 3.0.5
#由于某些原因,gem源不能访问或者可能下载失败可能下载失败,以下提供两种解决方案:
法一:手动下载下来安装
#download地址:http://rubygems.org/gems/redis/versions/3.0.0
gem install -l /soft/redis-3.0.5.gem
法二:更换gem 源
gem sources --remove https://rubygems.org/
gem sources -a http://ruby.sdutlinux.org/
gem sources -l
*** CURRENT SOURCES ***
https://ruby.taobao.org常用的源
http://rubygems.org/
http://gems.GitHub.com
http://gems.rubyforge.org
http://ruby.sdutlinux.org/
https://ruby.taobao.org 国内应该找个比较靠谱了,适合安装大多数常见的gem
tar xzf redis-3.0.5.tar.gz
cp -r redis-3.0.5 /opt/app/
ln -s /opt/app/redis-3.0.5/ /opt/redis
cd /opt/redis
make test
make
make install说明:
make install命令执行完成后,会在/usr/local/bin目录下生成本个可执行文件,分别是redis-server、redis-cli、redis-benchmark、redis-check-aof 、redis-check-dump,它们的作用如下:
redis-server:Redis服务器的daemon启动程序
redis-cli:Redis命令行操作工具。也可以用telnet根据其纯文本协议来操作
redis-benchmark:Redis性能测试工具,测试Redis在当前系统下的读写性能
redis-check-aof:数据修复
redis-check-dump:检查导出工具
1)配置集群初始化脚本:
cd /opt/redis
cp /opt/redis/src/redis-trib.rb /usr/local/bin
2)配置redis cluster配置文件
daemonize yes
#以后台进程redis运行.
pidfile /opt/redis/run/redis_6379.pid
#若以后台进程运行Reids,则需指定pid文件及路径.
port 6379
#指定redis监听端口.
tcp-backlog 511
#在高并发的环境中,为避免客户端的连接缓慢问题.
bind 0.0.0.0
#绑定主机IP.(这里设置为4个0可以方便程序调用).
timeout 0
#客户端连接时的超时时间,单位为秒.
tcp-keepalive 60
#在 Linux 上,指定值(秒)用于发送 ACKs 的时间,注意关闭连接需要双倍的时间.默认为 0
loglevel notice
#日志记录等级,有4个可选值,debug,verbose(默认值),notice,warning
logfile "/var/log/redis/redis_6379.log"
#log 文件地址
databases 16
#可用数据库数
save 900 1
save 300 10
save 60 10000
#根据给定的时间间隔和写入次数将数据保存到磁盘,单位为秒
stop-writes-on-bgsave-error yes
#后台存储错误停止写。
rdbcompression yes
#存储至本地数据库时(持久化到dump.rdb文件)是否压缩数据,默认为 yes
rdbchecksum yes
#是否校验rdb文件.
dbfilename dump_6379.rdb
#本地持久化数据库文件名,默认值为 dump.rdb
dir /opt/redis/data
#数据库镜像备份的文件放置的路径。
#slaveof <masterip> <masterport>
#设置该数据库为其他数据库的从数据库时启用该参数。
#masterauth <master-passWord>
#slave服务连接master的密码
slave-serve-stale-data yes
slave-read-only yes
#slave只读
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
slave-priority 100
#requirepass foobared
#设置客户端连接密码
appendonly yes
#打开aof持久化
appendfilename "appendonly_6379.aof"
#aof文件名,默认为appendonly.aof
appendfsync everysec
#每秒一次aof写
no-appendfsync-on-rewrite yes
#关闭在aof rewrite的时候对新的写操作进行fsync
auto-aof-rewrite-percentage 100
#部署在同一机器的redis实例,把auto-aof-rewrite搓开,因为cluster环境下内存占用基本一致.
#防止同一机器下瞬间fork所有redis进程做aof rewrite,占用大量内存(ps:cluster必须开启aof)
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
lua-time-limit 5000
cluster-enabled yes
#打开redis集群
cluster-config-file nodes-6379.conf
#集群节点配置文件(启动自动生成)
cluster-node-timeout 15000
#节点互连超时的阀值
cluster-migration-barrier 1
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
activerehashing yes
client-output-buffer-limit nORMal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
aof-rewrite-incremental-fsync yes注意:其他节点只需要复制配置文件将所有端口号更改即可。
192.1.168.1.193
cd /opt/redis
redis-server redis_6379.conf
redis-server redis_6479.conf
redis-server redis_6579.conf
192.1.168.1.193
cd /opt/redis
redis-server redis_6379.conf
redis-server redis_6479.conf
redis-server redis_6579.conf启动之后使用netstat –lntp 命令查看端口是否别监听,如图所示则启动正常。

redis-trib.rb create --replicas 1 192.168.1.193:6379 192.168.1.193:6479
192.168.1.193:6579 192.168.1.176:6379 192.168.1.193:6479 192.168.1.193:6579注:
#redis-trib.rb的create子命令构建
#--replicas 则指定了为Redis Cluster中的每个Master节点配备几个Slave节点
#节点角色由顺序决定,先master之后是slave(为方便辨认,slave的端口比master大1000)
#redis-trib.rb 的check子命令
#ip:port可以是集群的任意节点
redis-trib.rb check 192.168.1.193:6379最后输出如下信息,没有任何警告或错误(如图),表示集群启动成功并处于ok状态
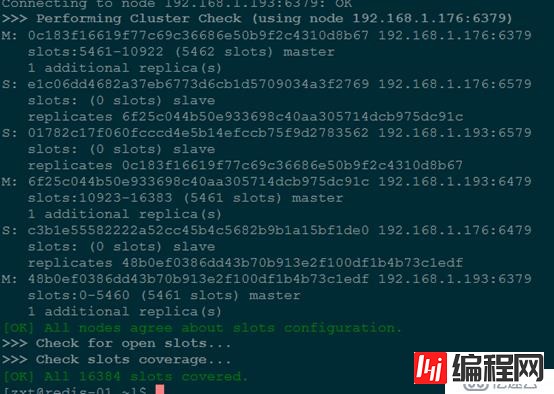
创建一个空节点(empty node),然后将某些哈希插槽移动到这个空节点上。
a)、创建新节点配置文件:
为了方便区分我这里再开启一台虚拟机增加一对节点:
192.168.1.187:6379
192.168.1.187:6479
cd /opt/redis
scp redis_6379.conf 192.168.1.187:/opt/redis/
cp redis_6379.conf redis_6479.conf
sed –ie s/6379/6479/g redis_6479.confb)、启动新节点:
redis-server redis_6379.conf
c)、将新节点加入集群:
redis-trib.rb add-node 192.168.1.187:6379 192.168.1.193:6379
add-node 将一个节点添加到集群里面, 第一个是新节点ip:port, 第二个是任意一个已存在节点ip:port注意:在添加新节点时,新节点中不能包含任何数据,否则会添加失败。
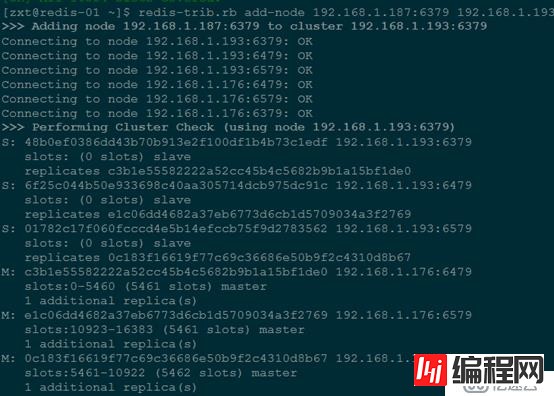

因为它没有包含任何哈希插槽。新加入的加点是一个主节点,当集群需要将某个从节点升级为新的主节点时, 这个新节点不会被选中,同时新的主节点因为没有包含任何哈希插槽,不参加选举和failover。
d)、手动为新节点添加哈希插槽:
redis-trib.rb reshard 192.168.1.187:6379
#根据提示选择要迁移的哈希插槽数量
How many slots do you want to move (from 1 to 16384)? 1000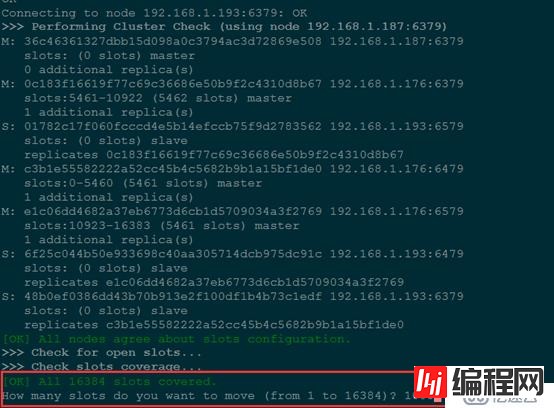
#选择要接受这些哈希插槽的node-id
What is the receiving node ID? 36c46361327dbb15d098a0c3794ac3D72869e508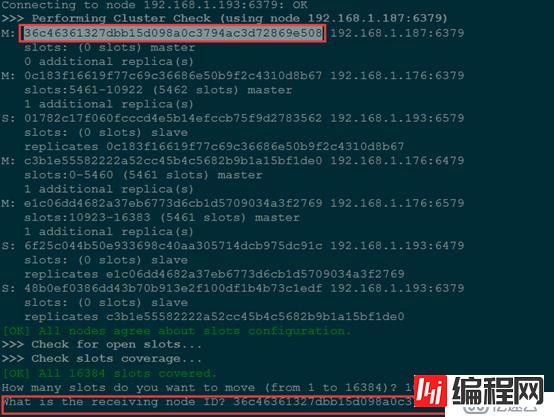
#选择哈希插槽来源:
#all表示从所有的master重新分配,
#或者数据要提取哈希插槽的master节点id,最后用done结束
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:all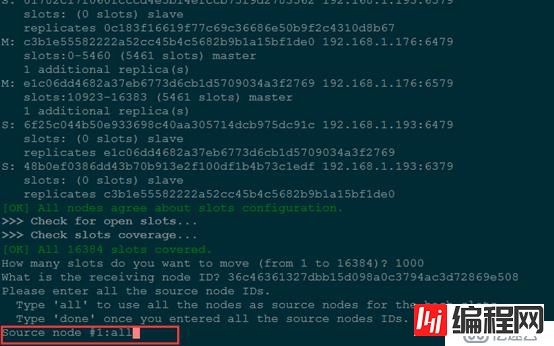
#打印被移动的哈希插槽后,输入yes开始移动哈希插槽以及对应的数据.
#Do you want to proceed with the proposed reshard plan (yes/no)? yes
#结束
可以使用命令查看对比哈希槽的分配情况(如图)
redis-trib.rb check 192.168.1.176:6379
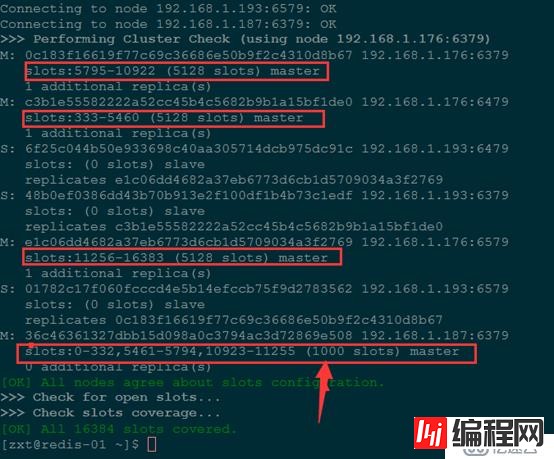
至此,一个新的主节点就添加完成了,执行命令查看现在的集群中节点的状态
redis-trib.rb check 192.168.1.176:6379
redis-cli -c -p 6379 cluster nodesa):前三步操作同添加master一样
注意:新添加的节点群集默认分配为master但是节点没有分配任何插槽(如图)

b)第四步:redis-cli连接上新节点shell,输入命令:cluster replicate 对应master的node-id(这里我们输入节点192.168.1.187:6379的id)。
redis-cli -h 192.168.1.187 -p 6479
cluster replicate 36c46361327dbb15d098a0c3794ac3d72869e508
exit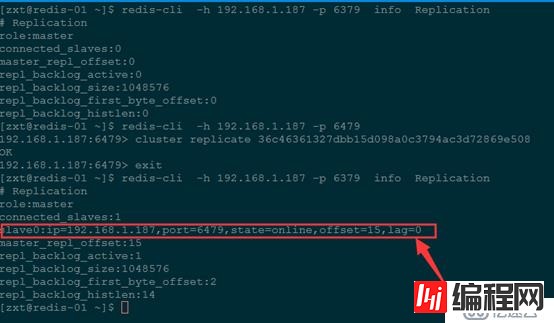
也可通过查看集群状态确定是否添加成功
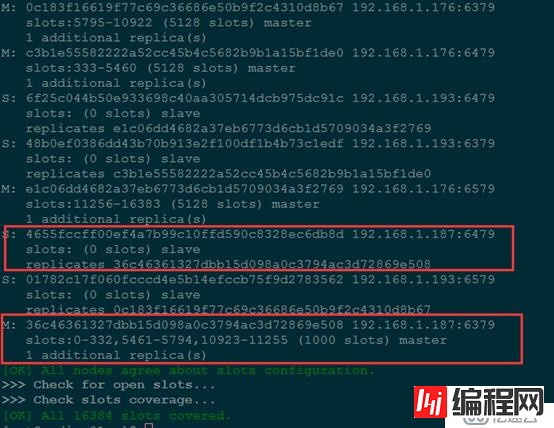
注意:在线添加slave 时,需要bgsave整个master数据,并传递到slave,再由 slave加载rdb文件到内存,rdb生成和传输的过程中消耗Master大量内存和网络IO,以此不建议单实例内存过大,线上小心操作。
法一:
#redis-trib del-node ip:port '<node-id>'
redis-trib.rb del-node 192.168.1.187:6479 4655fccff00ef4a7b99c10ffd590c8328ec6db8d法二:
直接停止或kill掉 节点即可
Redis-cli –p 6479 shutdown
or
kill -9 `cat /opt/redis/run/redis_6479.pid`a):删除master节点之前首先要使用reshard移除master的全部slot,然后再删除当前节点
#把192.168.1.187:6379当前master迁移到192.168.1.176:6579上
redis-trib.rb reshard 192.168.1.176:6579
#根据提示选择要迁移的哈希插槽数量
How many slots do you want to move (from 1 to 16384)? 1000
(被删除master的所有哈希插槽数量)
#选择要接受这些哈希插槽的192.168.1.176:6579
What is the receiving node ID? e1c06dd4682a37eb6773d6cb1d5709034a3f2769(ps: 192.168.1.176:6579的node-id)
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #36c46361327dbb15d098a0c3794ac3d72869e508 (被删除master的node-id)
Source node #2:done
#打印被移动的哈希插槽后,输入yes开始移动哈希插槽以及对应的数据.
#Do you want to proceed with the proposed reshard plan (yes/no)? yes b):删除空master节点
redis-trib.rb del-node 192.168.1.187:6379 '36c46361327dbb15d098a0c3794ac3d72869e508'
--结束END--
本文标题: 怎么安装和管理redis-cluster集群
本文链接: https://www.lsjlt.com/news/35733.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0