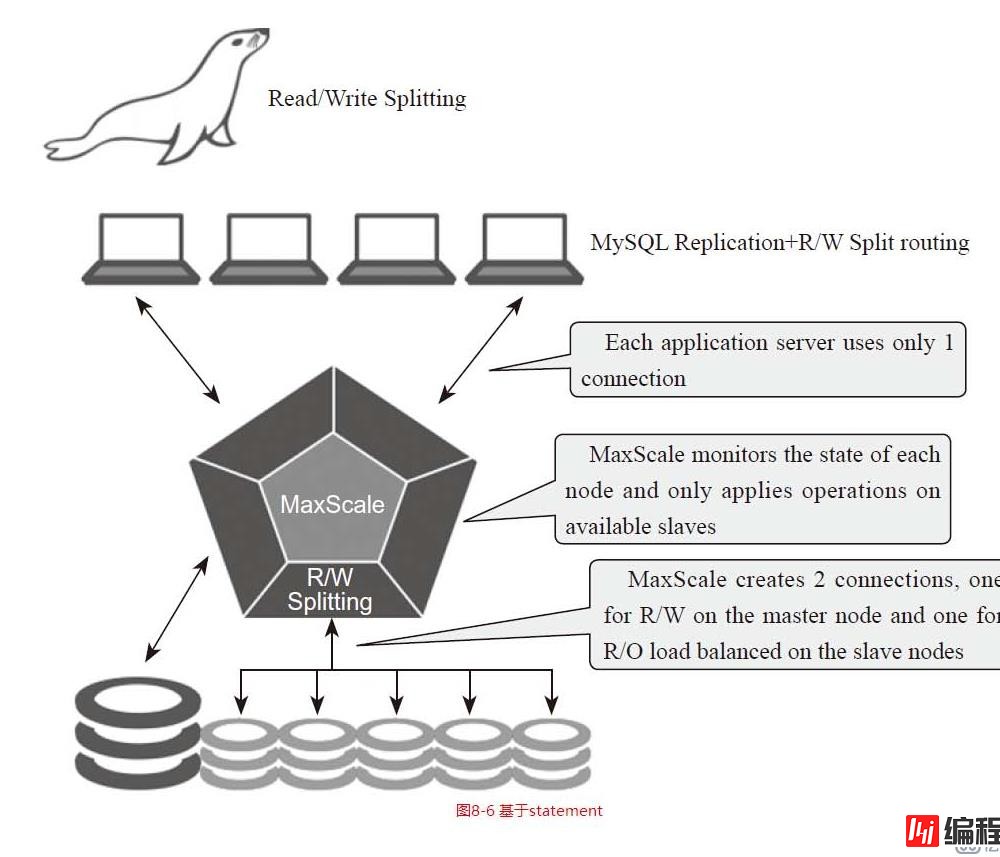
使用maxscale搭建的读写分离架构,后期还可以再结合MHA做master的故障转移,这样业务层面上不需要做任何的改动即可。基于connect方式的不要使用。从库延迟他还会继续分发请求过去,暂时不适合生产
使用maxscale搭建的读写分离架构,后期还可以再结合MHA做master的故障转移,这样业务层面上不需要做任何的改动即可。

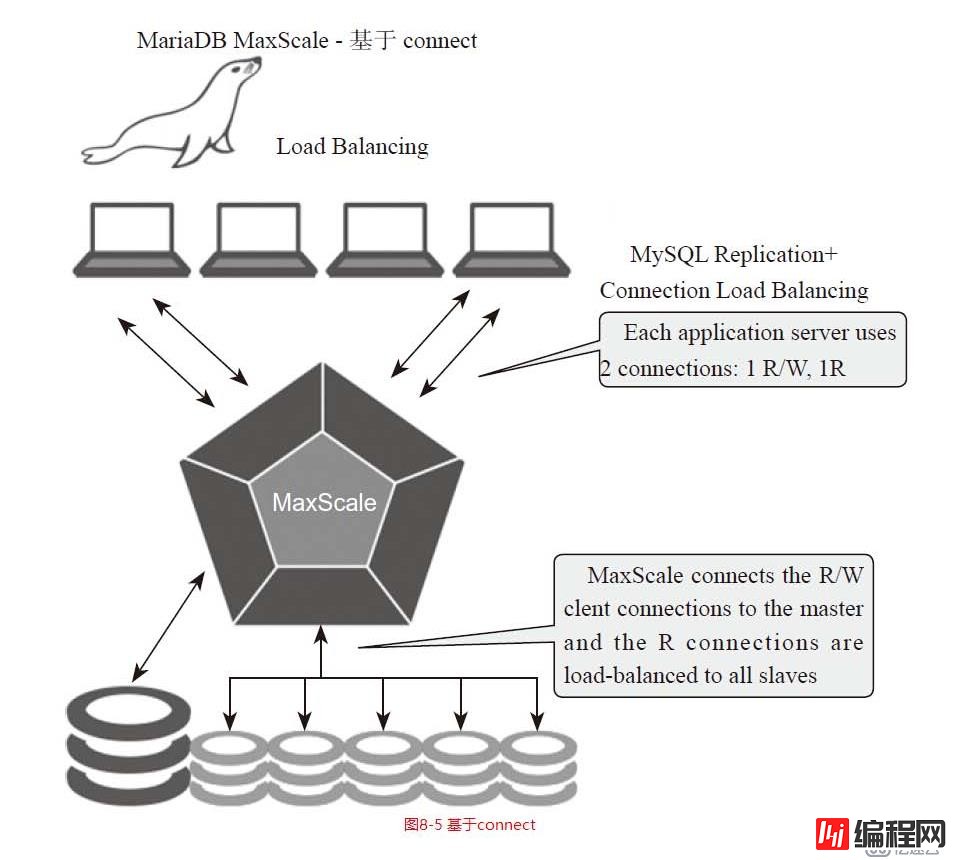
基于connect方式的不要使用。从库延迟他还会继续分发请求过去,暂时不适合生产使用。
实验演示:
目前的主从结构:
node93 10.1.20.93 master
node94 10.1.20.94 slave
node95 10.1.20.95 slave
node96 10.1.20.96 maxscale
先在master主库上创建相关的账户:
在开始配置之前,需要在 master中为MaxScale 创建两个用户,用于监控模块和路由模块。
创建监控用户,用于[MySQL Monitor]段的配置中:
> create database maxscale_schema ; # maxscale监控用的心跳信息会写到这个库里面
> create user scalemon@'%' identified by"111111";
> grant replication slave, replication client on*.* to scalemon@'%';
> grant all on maxscale_schema.* to scalemon@'%';
创建路由用户,用于[Read-Write Service]段的配置中:
> create user maxscale@'%' identified by"111111";
> grant select on Mysql.* to maxscale@'%';
maxscale 部署:
rpm -ivh maxscale-2.0.5-1.rhel.6.x86_64.rpm
主要生成文件如下:
/etc/maxscale.cnf
/etc/maxscale.cnf.template
/usr/bin/cdc.py
/usr/bin/cdc_kafka_producer.py
/usr/bin/cdc_last_transaction.py
/usr/bin/cdc_users.py
/usr/bin/maxadmin
/usr/bin/maxavrocheck
/usr/bin/maxbinloGCheck
/usr/bin/maxkeys
/usr/bin/maxpasswd
/usr/bin/maxscale
/var
/var/lib
/var/lib/maxscale
创建秘钥文件:
[root@maxscale /root ]# maxkeys /var/lib/maxscale
生成加密后的密码:
[root@maxscale /root ]# maxpasswd/var/lib/maxscale/.secrets 123456
上面划掉的这2步骤我们用不到,直接在配置文件/etc/maxscale.cnf里写上明文密码就行了。(这里踩了坑,配置这个参数,导致后面maxscale起来后,无法连接到其他库提示access denied)
vim/etc/security/limits.conf:
* softnofile 65535
* hardnofile 65535
vim/etc/sysctl.conf :
fs.file-max=655350
net.ipv4.ip_local_port_range= 1025 65000
net.ipv4.tcp_tw_reuse= 1
修改完内和参数后,需要重启下服务器。
修改配置文件:
cat /etc/maxscale.cnf
[maxscale]
threads=auto
ms_timestamp=1 #timestamp精度
syslog=1 #将日志写入到syslog中
maxlog=1 #将日志写入到maxscale的日志文件中
log_to_shm=0 #不将日志写入到共享缓存中,开启debug模式时可打开加快速度
log_warning=1 #记录告警信息
log_notice=1 #记录notice
log_info=1 #记录info
log_debug=0 #不打开debug模式
log_augmentation=1 #日志递增
# Server definitions
#
# Set the address of the server to the network
# address of a MySQL Server.
#
# 需要把master和slave地址都配上,maxscale会自动分辨出哪个是master和slave
[server1]
type=server
address=10.1.20.93
port=3306
protocol=mysqlBackend
[server2]
type=server
address=10.1.20.94
port=3306
protocol=MysqlBackend
[server3]
type=server
address=10.1.20.95
port=3306
protocol=MySQLBackend
# Monitor for the servers
#
# This will keep MaxScale aware of the state of theservers.
# MySQL Monitor documentation:
# https://GitHub.com/mariadb-corporation/MaxScale/blob/master/Documentation/Monitors/MySQL-Monitor.md
[MySQL Monitor]
type=monitor
module=mysqlmon
servers=server1,server2,server3 # 这里要把全部server都写上,以便maxscale去监测
user=scalemon
passwd=111111
monitor_interval=10000 # 每隔10s检查一次
detect_replication_lag=true # 检查复制延迟的情况
detect_stale_master=true # 当所有的slave都不可用时,select查询请求会转发到master。
# Service definitions
#
# Service Definition for a read-only service and
# a read/write splitting service.
#
# ReadConnRoute documentation:
#Https://github.com/mariadb-corporation/MaxScale/blob/master/Documentation/Routers/ReadConnRoute.md
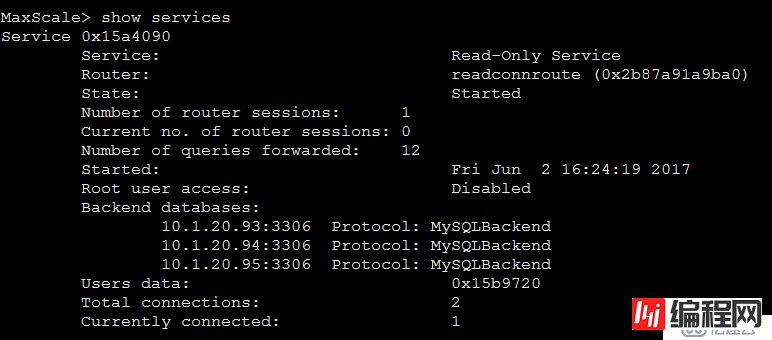
由于我们使用了 [Read-Write Service],可以删除另一个服务[Read-Only Service],注释掉下面整块儿内容即可。
# 需要把master和slave地址都配上
#[Read-Only Service]
#type=service
#router=readconnroute
#servers=server1,server2,server3
#user=maxscale # 读写分离的账户和密码
#passwd=111111 # 读写分离的账户和密码
#router_options=slave
# ReadWriteSplit documentation:
# https://github.com/mariadb-corporation/MaxScale/blob/master/Documentation/Routers/ReadWriteSplit.md
# 配置的读写分离,需要把master和slave地址都配上
[Read-Write Service]
type=service
router=readwritesplit
servers=server1,server2,server3
user=maxscale # 读写分离的账户和密码
passwd=111111 # 读写分离的账户和密码
max_slave_connections=100% # 所有的slave提供select查询服务
max_slave_replication_lag = 5 # slave超时5秒,就把请求转发到其他slave
use_sql_variables_in = all #
# This service enables the use of the MaxAdmininterface
# MaxScale administration guide:
#https://github.com/mariadb-corporation/MaxScale/blob/master/Documentation/Reference/MaxAdmin.md
[MaxAdmin Service]
type=service
router=cli
# Listener definitions for the services
#
# These listeners represent the ports the
# services will listen on.
#
#[Read-Only Listener]
#type=listener
#service=Read-Only Service
#protocol=MySQLClient
#port=4008
[Read-Write Listener]
type=listener
service=Read-Write Service
protocol=MySQLClient
port=4006
[MaxAdmin Listener]
type=listener
service=MaxAdmin Service
protocol=maxscaled
Socket=default
启动maxscale:
maxscale -f/etc/maxscale.cnf
ss -lnt 可以看到4006端口启动了。
可以使用之前的业务账号连接到maxscale的4006端口上,例如:
mysql -utest -ptest -P 4006 -h 10.1.20.96
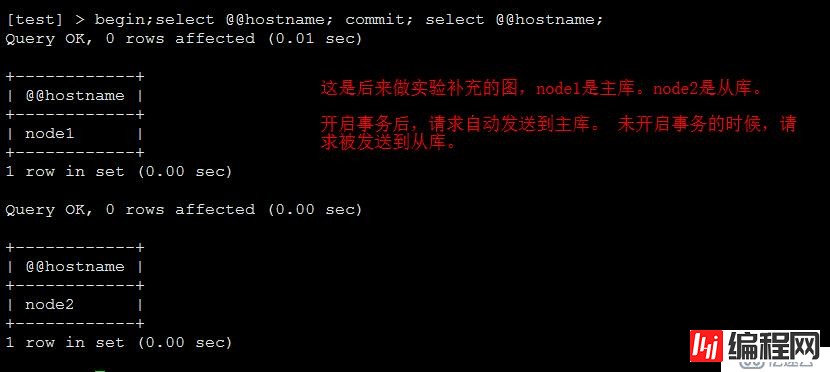
注意begin;select @@hostname;commit;这种的select会在主库上执行。此外,执行存储过程或者函数时候也是会自动在主库去执行的。
执行SQL > begin;select@@hostname; commit; insert into t2 select 3; select @@hostname; 对应的在/var/log/maxscale/maxscale.log记录如下:
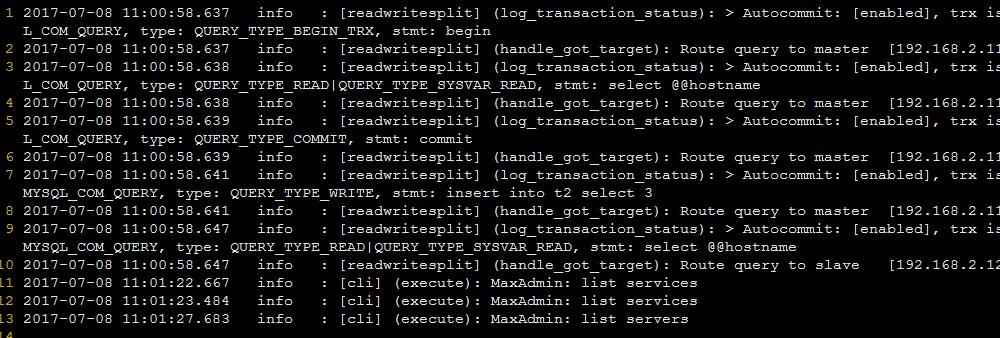
很明显的可以看:开启事务、插入等操作会被转发到主库去处理。而单纯的select则会被转发到某个从库去处理。
maxscale不能对master进行故障切换,可以配合使用MHA来进行。MHA的故障切换后,maxscale可以自动识别哪台机器是master。然后自动将求发送到新的主从结构中。
maxscale的延迟检测:
和pt-heartbeat的原理类似。maxscale会对master和slave上replication_heartbeat表的master_timestamp时间戳进行对比,相减得出差异。这个差异就是MySQL主从同步的延迟值。
select * frommaxscale_schema.replication_heartbeat;

从库故障或延迟过大会被自动剔除:
我们可以在192.168.2.12上stop slave; 稍等片刻,再执行查询操作的话,会发现请求不会被转发到192.168.2.12的mysql上,maxscale里面自动将这个机器踢下线了。如下图:
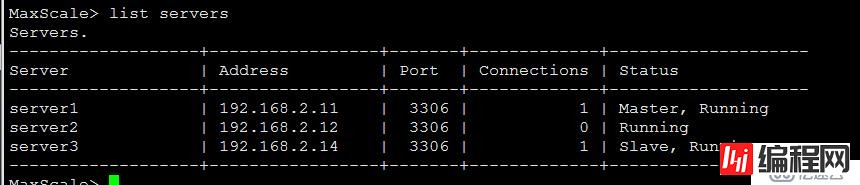
192.168.2.12 出现延迟,则在maxscale日志显示如下:
192.168.2.12 的3306端口不通(可能mysqld挂掉或者服务器宕机),则在maxscale日志显示如下:

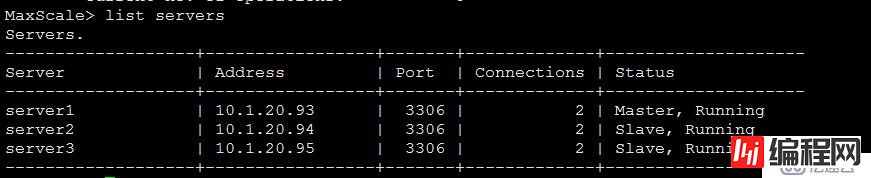
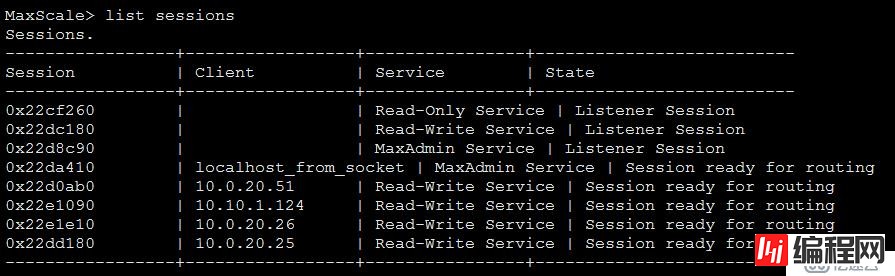
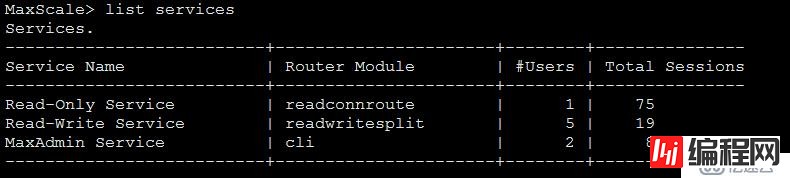
其他后补充进笔记的,管理maxscale的一些命令:
maxadmin -S /tmp/maxadmin.sock

--结束END--
本文标题: 基于maxscale的读写分离部署笔记
本文链接: https://www.lsjlt.com/news/35862.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-16
2024-05-16
2024-05-16
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0