整体描述:将本地文件的数据整理之后导入到HBase中在HBase中创建表数据格式mapReduce程序map程序package com.hadoop.mapreduce.test.map; im
整体描述:将本地文件的数据整理之后导入到HBase中
在HBase中创建表

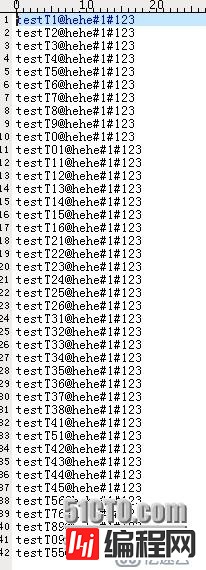
数据格式
map程序
package com.hadoop.mapreduce.test.map;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountHBaseMapper extends Mapper<Object, Text, Text, Text>{
public Text keyValue = new Text();
public Text valueValue = new Text();
//数据类型为:key@addressValue#ageValue#sexValue
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String lineValue = value.toString();
if(lineValue != null){
String[] valuesArray = lineValue.split("@");
context.write(new Text(valuesArray[0]), new Text(valuesArray[1]));
}
}
}Reduce程序
package com.hadoop.mapreduce.test.reduce;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
public class WordCountHBaseReduce extends TableReducer<Text, Text, NullWritable>{
@Override
protected void reduce(Text key, Iterable<Text> value, Context out)
throws IOException, InterruptedException {
String keyValue = key.toString();
Iterator<Text> valueIterator = value.iterator();
while(valueIterator.hasNext()){
Text valueV = valueIterator.next();
String[] valueArray = valueV.toString().split("#");
Put putRow = new Put(keyValue.getBytes());
putRow.add("address".getBytes(), "baseAddress".getBytes(),
valueArray[0].getBytes());
putRow.add("sex".getBytes(), "baseSex".getBytes(),
valueArray[1].getBytes());
putRow.add("age".getBytes(), "baseAge".getBytes(),
valueArray[2].getBytes());
out.write(NullWritable.get(), putRow);
}
}
}主程序
package com.hadoop.mapreduce.test;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFORMat;
import com.hadoop.mapreduce.test.map.WordCountHBaseMapper;
import com.hadoop.mapreduce.test.reduce.WordCountHBaseReduce;
public class WordCountHBase {
public static void main(String args[]) throws IOException,
InterruptedException, ClassNotFoundException{
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.ZooKeeper.quorum", "192.168.192.137");
Job job = Job.getInstance(conf, "MapReduceHbaseJob");
//各种class
job.setjarByClass(WordCountHBase.class);
job.setMapperClass(WordCountHBaseMapper.class);
TableMapReduceUtil.initTableReducerJob("userInfo3",
WordCountHBaseReduce.class, job);
FileInputFormat.addInputPath(job, new Path(args[0]));
job.setMapOutpuTKEyClass(Text.class);
job.setMapOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}结果:

注:如果运行的client没有hbase,需要在hadoop里面的lib中加入hbase的lib
--结束END--
本文标题: MapReduce将文本数据导入到HBase中
本文链接: https://www.lsjlt.com/news/37084.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0