possible_keys、key、key_len都为null,可见在表上是没有可用索引的计算区分度,越接近1区分度越好,应该放到联合索引的左侧建好联合索引之后的explain:翻页越多,速度越慢,进一步优
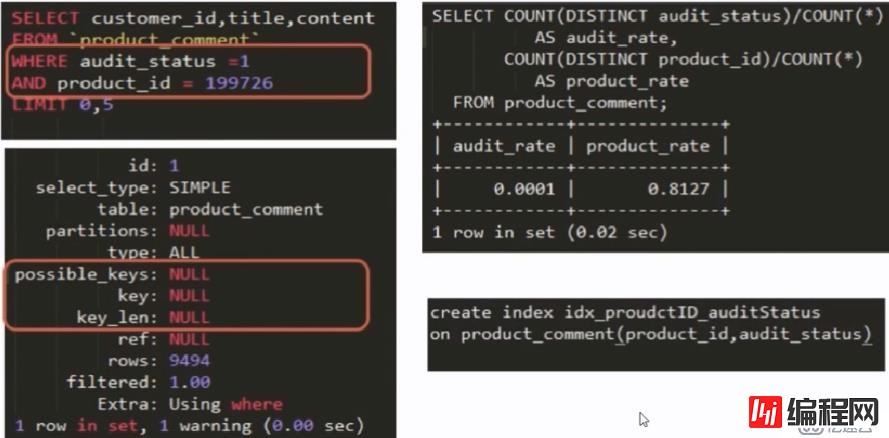
possible_keys、key、key_len都为null,可见在表上是没有可用索引的
计算区分度,越接近1区分度越好,应该放到联合索引的左侧
建好联合索引之后的explain:

翻页越多,速度越慢,进一步优化:
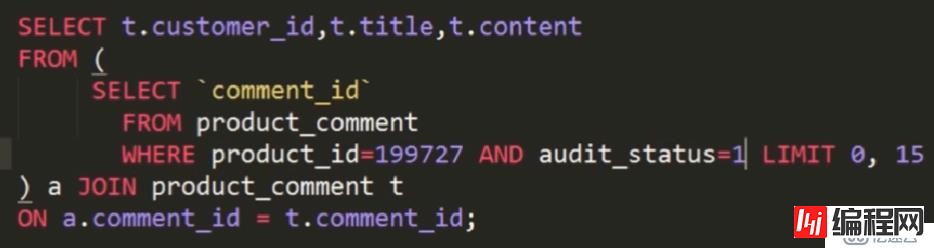
优化的前提:comment_id是商品评论表的主键,且有覆盖索引
原理:
利用覆盖索引,取出主键comment_id,再进行排序,取出所需数据,之后再同评论表通过主键来排序,取出其他字段。这种方式的数据开销是:索引的io + 索引分页后的结果,也就是这15行数据对应表的io,比优化前的io节省很多。优点在于:每次翻页消耗的资源和时间基本相同。
适应场景:
当查询和排序字段,也就是where子句和order by子句涉及的字段有对应覆盖索引的情况下。并且中间结果集很大的时候也适应这种情况
--结束END--
本文标题: 优化评论分页查询
本文链接: https://www.lsjlt.com/news/41042.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-16
2024-05-16
2024-05-16
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0