前言 某大型国有银行一套关键系统10g升级到11g,老K负责升级后第一天早上的运行保障;在升级前甲方客户已经先后做了各种测试,以保证升级后不会存在任何性能
前言 某大型国有银行一套关键系统10g升级到11g,老K负责升级后第一天早上的运行保障;在升级前甲方客户已经先后做了各种测试,以保证升级后不会存在任何性能问题。然而,事与愿违,老K刚到现场,客户应用团队就已经反馈到客户说批量慢了一段时间,根据应用日志与现场负责协助升级的友商DBA的核查,初步定位问题为升级后使用的存储变慢导致的导出缓慢,拖慢了批量的执行时间。对于这一结论,客户在调动存储相关工程师进行核查的同时,还存在疑惑,于是老K便开始参与这一问题的追查;现在问题就可以描述为:oracle从10g升级到11g后,导入操作变慢。
因为是升级前后导入的效率变化,于是老K首先将生产系统分别在10g和11g的环境下导入的日志来进行对比,主要核对导入的时间点后再进一步查看相关时间点数据库的状态。然而,在看过两个日志后,老K就有了自己的疑惑,于是,我就启动自己的虚拟机,开始自己的验证探索之旅。
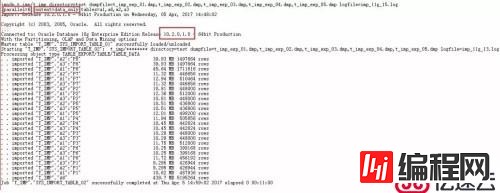

上面两图是我在自己的虚拟机上直接测试导入得到的导入日志文件,细心的你在看完下图之后,是否也发现了一些疑惑呢?老K提示:
老K提示:
1.导入时启用了并行(并行为6,大于表的个数)
2.导入时使用了content=data_only(说明数据库中原来已经有了表的定义)
3.导入的表中存在分区表(A1,A2,A3共计24个分区)和非分区表(A6)
02分析中。。。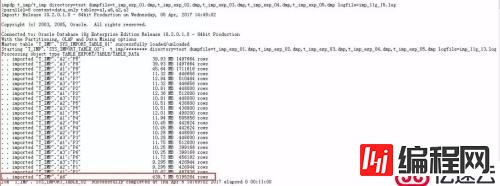
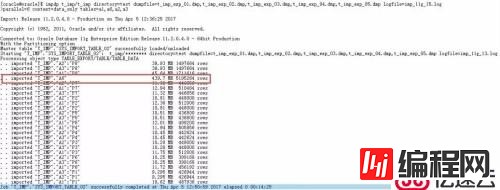
如图所示,表A6比较大,有超过500万条记录(而且这里老K还在A6表上建了索引,在导入时还需要维护A6表的索引,其他表则没有索引),而其他所有的表占用空间加起来也不过300M大小而已。在10g的日志中,A6表的日志记录写在了最后一行,而在11g的日志中则出现在了第四行。
正常来说,使用数据泵导入/导出多个表时,会在导入/导出完成时在日志中打出相应表的信息,如果这里A6表作为一个大表,却相较于其他表先完成导入操作,我们就可以怀疑分区表和非分区表同时导入时,11g数据泵的机制是存在问题的,特别是在对比了10g的导入情况后。
03猜测&验证上面梳理出疑惑,我们应该怎么去验证呢?如果我们是正在执行导入/导出的操作,我们可以attach到导入/导出任务中进行实时观察;而如果是导入/导出已经完成了,那我们就需要从数据库的历史性能视图中去寻找答案了(这里我们主要针对11g数据库进行验证)。
首先,我们先来通过v$active_session_history视图来查看导入的整体情况:

这里使用v$active_session_history视图来核查,每秒做一次采样发现,导入期间,数据库确实启动了6个并行进程(worker),其中DW00进程采样次数最多,但是各进程的最早采样到的时间和最后采样到的时间相差无几,都是从12:36左右到12:51;显然,这个过程中有部分worker进程是空闲的;
那么,是不是分区表导入存在问题呢?
我们先来分析分区表(以A1为例)的导入过程:
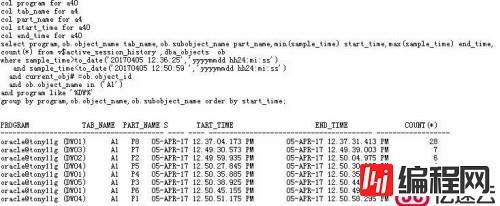
通过上面结果,我们能看到一个特征,就A1表而言,其各个分区的导入散落在不同的DW进程上,但是从采样的最大最小时间上看,没有重合时间区域,也就是说,在目前DATAPUMP启动了6个并行来导入4个表的时候,看起来分区表A1表并没有做到多个分区并行导入,同样我们核查A2、A3表的导入情况:


得出结论如下:导入时,虽然并行度是6,只导入4个表(含分区表)的情况下,所有的表的多个分区间没有并行地导入,至少有个两个DW进程是空闲的(实时attach到导入进程监控时更是一目了然)。
此类情况是不是与我们以往的经验相违背呢?
知识点:
1.数据泵导入时,并行主要是通过多个进程分别导入不同的表来提高导入速度的,而不同的分区作为不同的segment一般也被当做不同的表来处理;
2.数据泵导入时,默认使用的是insert append的方式,也就是说在导入时会持有对象的表锁;
本次的导入好像就是与第一条有所不符,导入时在存在空闲进程的情况下,同一个表的不同分区并没有做到并行,那是为什么呢?我们需要注意到我们在前面提到的几个导入特征,其中一个就是,我们使用了content=data_only; 使用这个参数就意味着,当前数据库中已经有了该分区表的定义,只是将数据导入到已存在的表中去,在数据库中已经存在分区表的定义而需要向其中导入数据时,则可能会遇到的一种情况是,数据库中分区表的定义与DUMP文件中分区表的定义不一致(比如分区键不一致),导致DUMP文件中的分区无法与数据库中的已有分区一一对应,而无法做到一一对应就意味着,如果启动多个WORKER同时导入一个表的不同分区,不同WORKER就有可能会同时向一个目标分区中执行insert append操作,前面提到,insert append操作会持有行锁,这样最后会出现导入worker间的互相阻塞的情况,而且有可能形成死锁,所以oracle较新的版本中,在导入已存在分区表时(使用了参数content=data_only等),同一表的多个分区是顺序导入的(虽然有可能是通过不同的worker来执行)。
04疑问&解答那么10g数据库的导入是不是也是这样呢?我们用同样方法来测试观察,可以发现10g数据库的导入也是如此,那么客户在10g、11g环境中导入的数据、表的定义、导入命令,都没有变化,看起来并行+metadata_only并不是问题所在,那么真正的问题在哪里呢?我再次回到最开始的问题:
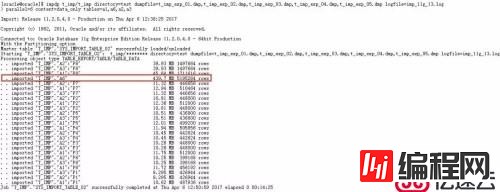
在10g的日志中,A6表的日志记录写在了最后一行,而在11g的日志中则出现在了第四行,也就是说,在10g中,A6表是最后完成的,而在11g中A6表却在A1、A2、A3表的大部分分区完成前已经完成了,是A1、A2、A3表的导入进程在等待什么吗?
还是要回到v$active_session_history视图上来:
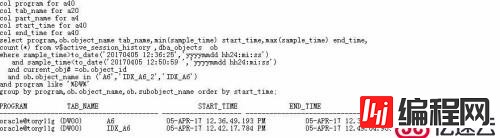
可以看到,A6导入时间大约从12:36持续到12:49,包含索引维护
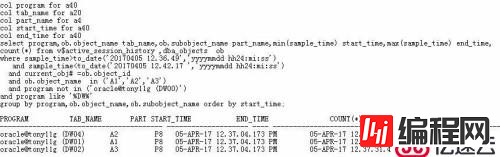
而在此期间其他活动的会话中,各分区表只导入了一个分区(即各表导入的第一个分区),而且各WORKER在导入完第一个分区后(12:37:32~12:42:17)并没有异常等待,而是处于空闲状态。
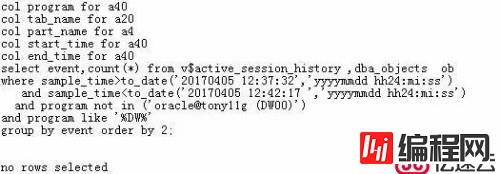
我们再回顾一下各个表的导入情况:




可以看到,各个表在导完第一个分区后,出现长时间的停顿,一直等到非分区表导入完,才继续后续的分区导入;
结合各worker的状态及各表导入的时间状态以及前面的结论我们可以确认一点:
在分区表和非分区表同时导入,而且是数据库中表定义已经存在(使用content=metadata_only等参数)时,分区表需要逐个导入无法使用并行,而在所有分区表分别导完第一个分区后,需要等待所有的非分区表导入完成,才能继续后面的分区表的分区导入,进而影响导入进度。
而以上问题在10g数据泵中不存在,宇宙行客户所遇到的问题正是这个问题,升级后多花费的时间也基本上就是单个非分区表导入的时间。以上问题已经提交的ORACLE官方并确认为11g导入的调度机制问题,目前正在开发解决中。
05我们遇到了什么
看看我们遇到了什么问题吧:
1.在10g中,我们使用并行导入分区表和非分区表,并且目标库中已经有了表的定义,于是我们加上了content=data_only参数;
2.导入的过程中,分区表的各个分区逐个导入,在并行进程足够多的时候各个表之间实现并行导入;
3.升级到11g以后,各分区表仅仅导入第一个分区,然后开始等待;
4.非分区表导入完成后,各分区表继续完成导入。
而现在我们知道了,多花费的时间就是第三步的时间,在10g环境先,非分区表可以与分区表并行导入,而到了11g环境中,非分区表只能与分区表导入的第一个分区并行导入;假设,我们需要导入的是一个超大的非分区表和3个分区表,每个分区表3个分区,各分区大小一致,如果单独导所有的分区表需要1个小时,单独导所有非分区表需要1个小时,启用4个并行,在10g的环境里,理想情况下只需要1个小时即可导入完成(以导入最慢的非分区表导入完成,即整体导入完),而在11g的环境中,则需要1个小时+3/4个小时(即105分钟)。
我们可以做什么:
当我们需要追求导入的效率时:
1.导入分区表时尽量避免使用content=data_only或table_exists_action=appen/truncate的方式,如果已有表的数据量不大,而且dump中表的结构也与已存表的结构一致,我们不妨先存留已有表的数据,再使用table_exists_action=replace的方式;
2.如果导入分区表无法避免使用content=data_only或table_exists_action=appen/truncate,那么我们建议分区表和非分区表分开导入。
--结束END--
本文标题: 风险预警·11g容易被忽略的导入性能问题
本文链接: https://www.lsjlt.com/news/43113.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-14
2024-05-14
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0