摘要在讨论某个数据库时,存储 ( Storage ) 和计算 ( Query Engine ) 通常是讨论的热点,也是爱好者们了解某个数据库不可或缺的部分。每个数据库都有其独有的存储、计算方式,今天就和图图
在讨论某个数据库时,存储 ( Storage ) 和计算 ( Query Engine ) 通常是讨论的热点,也是爱好者们了解某个数据库不可或缺的部分。每个数据库都有其独有的存储、计算方式,今天就和图图来学习下图数据库 Nebula Graph 的存储部分。
Nebula 的 Storage 包含两个部分, 一是 meta 相关的存储, 我们称之为 Meta Service ,另一个是 data 相关的存储, 我们称之为 Storage Service。 这两个服务是两个独立的进程,数据也完全隔离,当然部署也是分别部署, 不过两者整体架构相差不大,本文最后会提到这点。 如果没有特殊说明,本文中 Storage Service 代指 data 的存储服务。接下来,大家就随我一起看一下 Storage Service 的整个架构。 Let's Go~
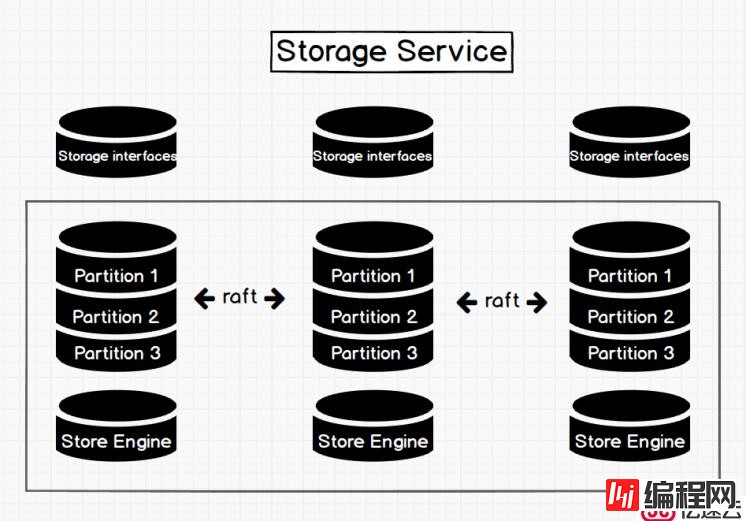 图一 storage service 架构图
图一 storage service 架构图
如图1 所示,Storage Service 共有三层,最底层是 Store Engine,它是一个单机版 local store engine,提供了对本地数据的 get / put / scan / delete 操作,相关的接口放在 KVStore / KVEngine.h 里面,用户完全可以根据自己的需求定制开发相关 local store plugin,目前 Nebula 提供了基于 RocksDB 实现的 Store Engine。
在 local store engine 之上,便是我们的 Consensus 层,实现了 Multi Group Raft,每一个 Partition 都对应了一组 Raft Group,这里的 Partition 便是我们的数据分片。目前 Nebula 的分片策略采用了 静态 Hash 的方式,具体按照什么方式进行 Hash,在下一个章节 schema 里会提及。用户在创建 SPACE 时需指定 Partition 数,Partition 数量一旦设置便不可更改,一般来讲,Partition 数目要能满足业务将来的扩容需求。
在 Consensus 层上面也就是 Storage Service 的最上层,便是我们的 Storage interfaces,这一层定义了一系列和图相关的 api。 这些 API 请求会在这一层被翻译成一组针对相应 Partition 的 kv 操作。正是这一层的存在,使得我们的存储服务变成了真正的图存储,否则,Storage Service 只是一个 kv 存储罢了。而 Nebula 没把 kv 作为一个服务单独提出,其最主要的原因便是图查询过程中会涉及到大量计算,这些计算往往需要使用图的 schema,而 kv 层是没有数据 schema 概念,这样设计会比较容易实现计算下推。
图存储的主要数据是点和边,但 Nebula 存储的数据是一张属性图,也就是说除了点和边以外,Nebula 还存储了它们对应的属性,以便更高效地使用属性过滤。
对于点来说,我们使用不同的 Tag 表示不同类型的点,同一个 VertexID 可以关联多个 Tag,而每一个 Tag 都有自己对应的属性。对应到 kv 存储里面,我们使用 vertexID + TagID 来表示 key, 我们把相关的属性编码后放在 value 里面,具体 key 的 fORMat 如图2 所示:
 图二 Vertex Key Format
图二 Vertex Key Format
Type : 1 个字节,用来表示 key 类型,当前的类型有 data, index, system 等
Part ID : 3 个字节,用来表示数据分片 Partition,此字段主要用于 Partition 重新分布(balance) 时方便根据前缀扫描整个 Partition 数据
Vertex ID : 4 个字节, 用来表示点的 ID
Tag ID : 4 个字节, 用来表示关联的某个 tag
在一个图中,每一条逻辑意义上的边,在 Nebula Graph 中会建模成两个独立的 key-value,分别称为 out-key 和in-key。out-key 与这条边所对应的起点存储在同一个 partition 上,in-key 与这条边所对应的终点存储在同一个partition 上。通常来说,out-key 和 in-key 会分布在两个不同的 Partition 中。
两个点之间可能存在多种类型的边,Nebula 用 Edge Type 来表示边类型。而同一类型的边可能存在多条,比如,定义一个 edge type "转账",用户 A 可能多次转账给 B, 所以 Nebula 又增加了一个 Rank 字段来做区分,表示 A 到 B 之间多次转账记录。 Edge key 的 format 如图3 所示:
 图三 Edge Key Format
图三 Edge Key Format
Type : 1 个字节,用来表示 key 的类型,当前的类型有 data, index, system 等。
Part ID : 3 个字节,用来表示数据分片 Partition,此字段主要用于 Partition 重新分布(balance) 时方便根据前缀扫描整个 Partition 数据
Vertex ID : 4 个字节, 出边里面用来表示源点的 ID, 入边里面表示目标点的 ID。
Edge Type : 4 个字节, 用来表示这条边的类型,如果大于 0 表示出边,小于 0 表示入边。
Rank : 4 个字节,用来处理同一种类型的边存在多条的情况。用户可以根据自己的需求进行设置,这个字段可_存放交易时间_、交易流水号、或_某个排序权重_
Vertex ID : 4 个字节, 出边里面用来表示目标点的 ID, 入边里面表示源点的 ID。
Timestamp : 8 个字节,对用户不可见,未来实现分布式做事务的时候使用。
针对 Edge Type 的值,若如果大于 0 表示出边,则对应的 edge key format 如图4 所示;若 Edge Type 的值小于 0,则对应的 edge key format 如图5 所示
 图4 出边的 Key Format
图4 出边的 Key Format  图5 入边的 Key Format
图5 入边的 Key Format
对于点或边的属性信息,有对应的一组 kv pairs,Nebula 将它们编码后存在对应的 value 里。由于 Nebula 使用强类型 schema,所以在解码之前,需要先去 Meta Service 中取具体的 schema 信息。另外,为了支持在线变更 schema,在编码属性时,会加入对应的 schema 版本信息,具体的编解码细节在这里不作展开,后续会有专门的文章讲解这块内容。
OK,到这里我们基本上了解了 Nebula 是如何存储数据的,那数据是如何进行分片呢?很简单,对 Vertex ID 取模 即可。通过对 Vertex ID 取模,同一个点的所有_出边_,_入边_以及这个点上所有关联的 _Tag 信息_都会被分到同一个 Partition,这种方式大大地提升了查询效率。对于在线图查询来讲,最常见的操作便是从一个点开始向外 BFS(广度优先)拓展,于是拿一个点的出边或者入边是最基本的操作,而这个操作的性能也决定了整个遍历的性能。BFS 中可能会出现按照某些属性进行剪枝的情况,Nebula 通过将属性与点边存在一起,来保证整个操作的高效。当前许多的图数据库通过 Graph 500 或者 Twitter 的数据集试来验证自己的高效性,这并没有代表性,因为这些数据集没有属性,而实际的场景中大部分情况都是属性图,并且实际中的 BFS 也需要进行大量的剪枝操作。
为什么要自己做 KVStore,这是我们无数次被问起的问题。理由很简单,当前开源的 KVStore 都很难满足我们的要求:
性能,性能,性能:Nebula 的需求很直接:高性能 pure kv;
以 library 的形式提供:对于强 schema 的 Nebula 来讲,计算下推需要 schema 信息,而计算下推实现的好坏,是 Nebula 是否高效的关键;
数据强一致:这是分布式系统决定的;
使用 c++实现:这由团队的技术特点决定;
基于上述要求,Nebula 实现了自己的 KVStore。当然,对于性能完全不敏感且不太希望搬迁数据的用户来说,Nebula 也提供了整个KVStore 层的 plugin,直接将 Storage Service 搭建在第三方的 KVStore 上面,目前官方提供的是 HBase 的 plugin。
Nebula KVStore 主要采用 RocksDB 作为本地的存储引擎,对于多硬盘机器,为了充分利用多硬盘的并发能力,Nebula 支持自己管理多块盘,用户只需配置多个不同的数据目录即可。分布式 KVStore 的管理由 Meta Service 来统一调度,它记录了所有 Partition 的分布情况,以及当前机器的状态,当用户增减机器时,只需要通过 console 输入相应的指令,Meta Service 便能够生成整个 balance plan 并执行。(之所以没有采用完全自动 balance 的方式,主要是为了减少数据搬迁对于线上服务的影响,balance 的时机由用户自己控制。)
为了方便对于 WAL 进行定制,Nebula KVStore 实现了自己的 WAL 模块,每个 partition 都有自己的 WAL,这样在追数据时,不需要进行 wal split 操作, 更加高效。 另外,为了实现一些特殊的操作,专门定义了 Command Log 这个类别,这些 log 只为了使用 Raft 来通知所有 replica 执行某一个特定操作,并没有真正的数据。除了 Command Log 外,Nebula 还提供了一类日志来实现针对某个 Partition 的 atomic operation,例如 CAS,read-modify-write, 它充分利用了Raft 串行的特性。
关于多图空间(space)的支持:一个 Nebula KVStore 集群可以支持多个 space,每个 space 可设置自己的 partition 数和 replica 数。不同 space 在物理上是完全隔离的,而且在同一个集群上的不同 space 可支持不同的 store engine 及分片策略。
作为一个分布式系统,KVStore 的 replication,scale out 等功能需 Raft 的支持。当前,市面上讲 Raft 的文章非常多,具体原理性的内容,这里不再赘述,本文主要说一些 Nebula Raft 的一些特点以及工程实现。
由于 Raft 的日志不允许空洞,几乎所有的实现都会采用 Multi Raft Group 来缓解这个问题,因此 partition 的数目几乎决定了整个 Raft Group 的性能。但这也并不是说 Partition 的数目越多越好:每一个 Raft Group 内部都要存储一系列的状态信息,并且每一个 Raft Group 有自己的 WAL 文件,因此 Partition 数目太多会增加开销。此外,当 Partition 太多时, 如果负载没有足够高,batch 操作是没有意义的。比如,一个有 1w tps 的线上系统单机,它的单机 partition 的数目超过 1w,可能每个 Partition 每秒的 tps 只有 1,这样 batch 操作就失去了意义,还增加了 CPU 开销。 实现 Multi Raft Group 的最关键之处有两点,** 第一是共享 Transport 层**,因为每一个 Raft Group 内部都需要向对应的 peer 发送消息,如果不能共享 Transport 层,连接的开销巨大;第二是线程模型,Mutli Raft Group 一定要共享一组线程池,否则会造成系统的线程数目过多,导致大量的 context switch 开销。
对于每个 Partition来说,由于串行写 WAL,为了提高吞吐,做 batch 是十分必要的。一般来讲,batch 并没有什么特别的地方,但是 Nebula 利用每个 part 串行的特点,做了一些特殊类型的 WAL,带来了一些工程上的挑战。
举个例子,Nebula 利用 WAL 实现了无锁的 CAS 操作,而每个 CAS 操作需要之前的 WAL 全部 commit 之后才能执行,所以对于一个 batch,如果中间夹杂了几条 CAS 类型的 WAL, 我们还需要把这个 batch 分成粒度更小的几个 group,group 之间保证串行。还有,command 类型的 WAL 需要它后面的 WAL 在其 commit 之后才能执行,所以整个 batch 划分 group 的操作工程实现上比较有特色。焦作国医胃肠医院正规吗_卫生局认证 焦作老品牌:https://www.jianshu.com/p/3c43af3bb611
Learner 这个角色的存在主要是为了 应对扩容 时,新机器需要"追"相当长一段时间的数据,而这段时间有可能会发生意外。如果直接以 follower 的身份开始追数据,就会使得整个集群的 HA 能力下降。 Nebula 里面 learner 的实现就是采用了上面提到的 command wal,leader 在写 wal 时如果碰到 add learner 的 command, 就会将 learner 加入自己的 peers,并把它标记为 learner,这样在统计多数派的时候,就不会算上 learner,但是日志还是会照常发送给它们。当然 learner 也不会主动发起选举。
Transfer leadership 这个操作对于 balance 来讲至关重要,当我们把某个 Paritition 从一台机器挪到另一台机器时,首先便会检查 source 是不是 leader,如果是的话,需要先把他挪到另外的 peer 上面;在搬迁数据完毕之后,通常还要把 leader 进行一次 balance,这样每台机器承担的负载也能保证均衡。
实现 transfer leadership, 需要注意的是 leader 放弃自己的 leadership,和 follower 开始进行 leader election 的时机。对于 leader 来讲,当 transfer leadership command 在 commit 的时候,它放弃 leadership;而对于 follower 来讲,当收到此 command 的时候就要开始进行 leader election, 这套实现要和 Raft 本身的 leader election 走一套路径,否则很容易出现一些难以处理的 corner case。
为了避免脑裂,当一个 Raft Group 的成员发生变化时,需要有一个中间状态, 这个状态下 old group 的多数派与 new group 的多数派总是有 overlap,这样就防止了 old group 或者新 group 单方面做出决定,这就是论文中提到的 joint consensus 。为了更加简化,Diego Ongaro 在自己的博士论文中提出每次增减一个 peer 的方式,以保证 old group 的多数派总是与 new group 的多数派有 overlap。 Nebula 的实现也采用了这个方式,只不过 add member 与 remove member 的实现有所区别,具体实现方式本文不作讨论,有兴趣的同学可以参考 Raft Part class 里面 addPeer / removePeer 的实现。
Snapshot 如何与 Raft 流程结合起来,论文中并没有细讲,但是这一部分我认为是一个 Raft 实现里最容易出错的地方,因为这里会产生大量的 corner case。
举一个例子,当 leader 发送 snapshot 过程中,如果 leader 发生了变化,该怎么办? 这个时候,有可能 follower 只接到了一半的 snapshot 数据。 所以需要有一个 Partition 数据清理过程,由于多个 Partition 共享一份存储,因此如何清理数据又是一个很麻烦的问题。另外,snapshot 过程中,会产生大量的 IO,为了性能考虑,我们不希望这个过程与正常的 Raft 共用一个 IO threadPool,并且整个过程中,还需要使用大量的内存,如何优化内存的使用,对于性能十分关键。由于篇幅原因,我们并不会在本文对这些问题展开讲述,有兴趣的同学可以参考 SnapshotManager 的实现。
在 KVStore 的接口之上,Nebula 封装有图语义接口,主要的接口如下:
getNeighbors : 查询一批点的出边或者入边,返回边以及对应的属性,并且需要支持条件过滤;
Insert vertex/edge : 插入一条点或者边及其属性;
getProps : 获取一个点或者一条边的属性;
这一层会将图语义的接口转化成 kv 操作。为了提高遍历的性能,还要做并发操作。
在 KVStore 的接口上,Nebula 也同时封装了一套 meta 相关的接口。Meta Service 不但提供了图 schema 的增删查改的功能,还提供了集群的管理功能以及用户鉴权相关的功能。Meta Service 支持单独部署,也支持使用多副本来保证数据的安全。
这篇文章给大家大致介绍了 Nebula Storage 层的整体设计, 由于篇幅原因, 很多细节没有展开讲, 欢迎大家到我们的微信群里提问,加入 Nebula Graph 交流群,请联系 Nebula Graph 官方小助手微信号:NebulaGraphbot。
--结束END--
本文标题: Nebula 架构剖析系列(一)图数据库的存储设计
本文链接: https://www.lsjlt.com/news/50587.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-14
2024-05-13
2024-05-13
2024-05-13
2024-05-13
2024-05-12
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0