文章目录 写在前面实验描述实验内容遇到问题 写在后面 写在前面 本期内容:基于requests+Mysql爬取猫眼热门电影数据做可视化分析 实验需求 anaconda丨PyCharmp
本期内容:基于requests+Mysql爬取猫眼热门电影数据做可视化分析
实验需求
项目下载地址:https://download.csdn.net/download/m0_68111267/88737727
学习网络爬虫相关技术,熟悉爬虫基本库requests的使用;学习数据库技术,熟悉mysql数据库的基本操作。本文博主将用requests库抓取猫眼热门电影的数据,将数据保存在mysql数据库中,然后再用tkinter做可视化分析。
1. 分析猫眼热门电影的网页信息
我们先进入要抓取数据的网页:http://maoyan.com/board/4?offset=0
然后分别进入不同页码,分析热门电影每一页的网址信息:

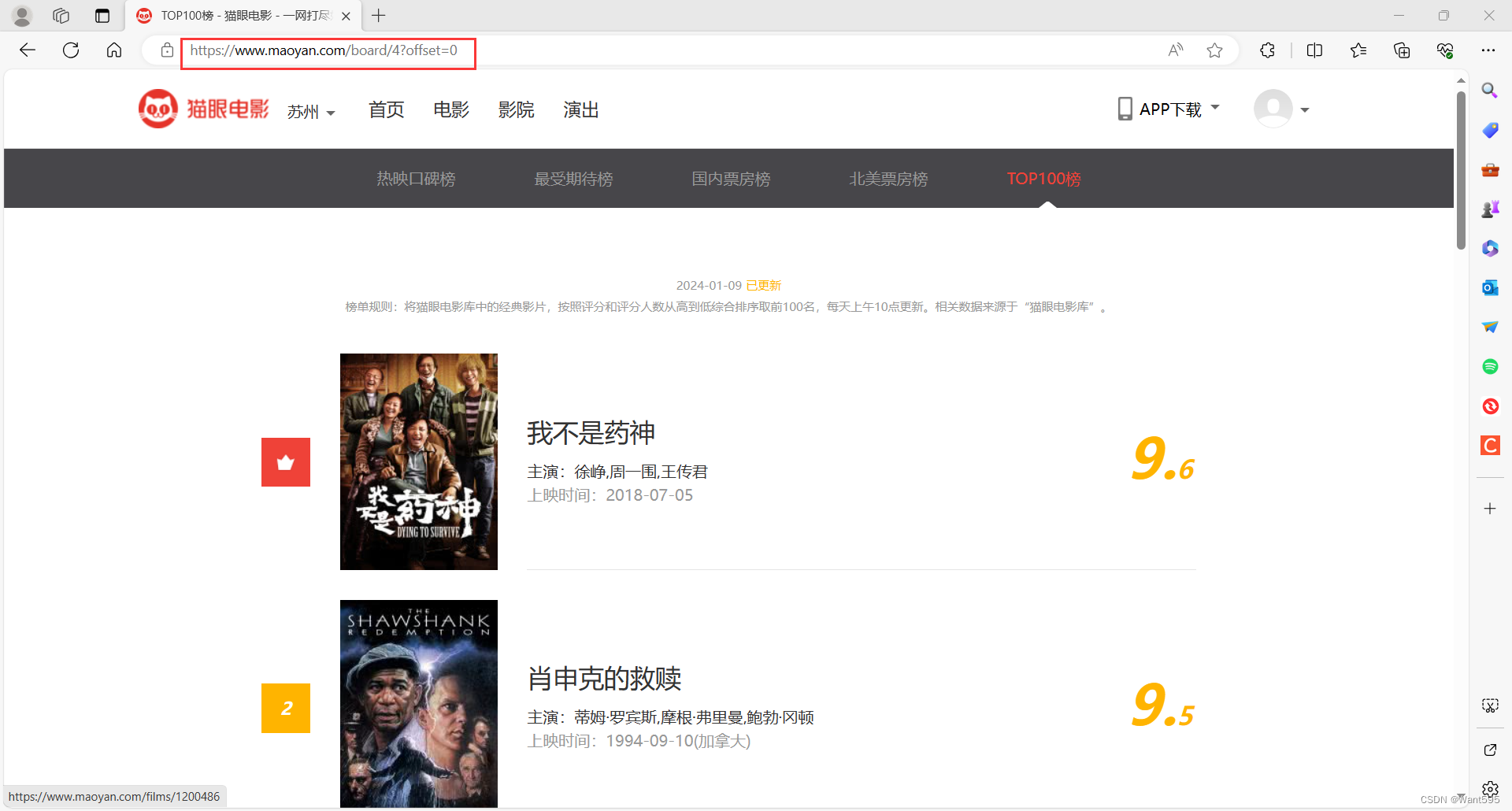
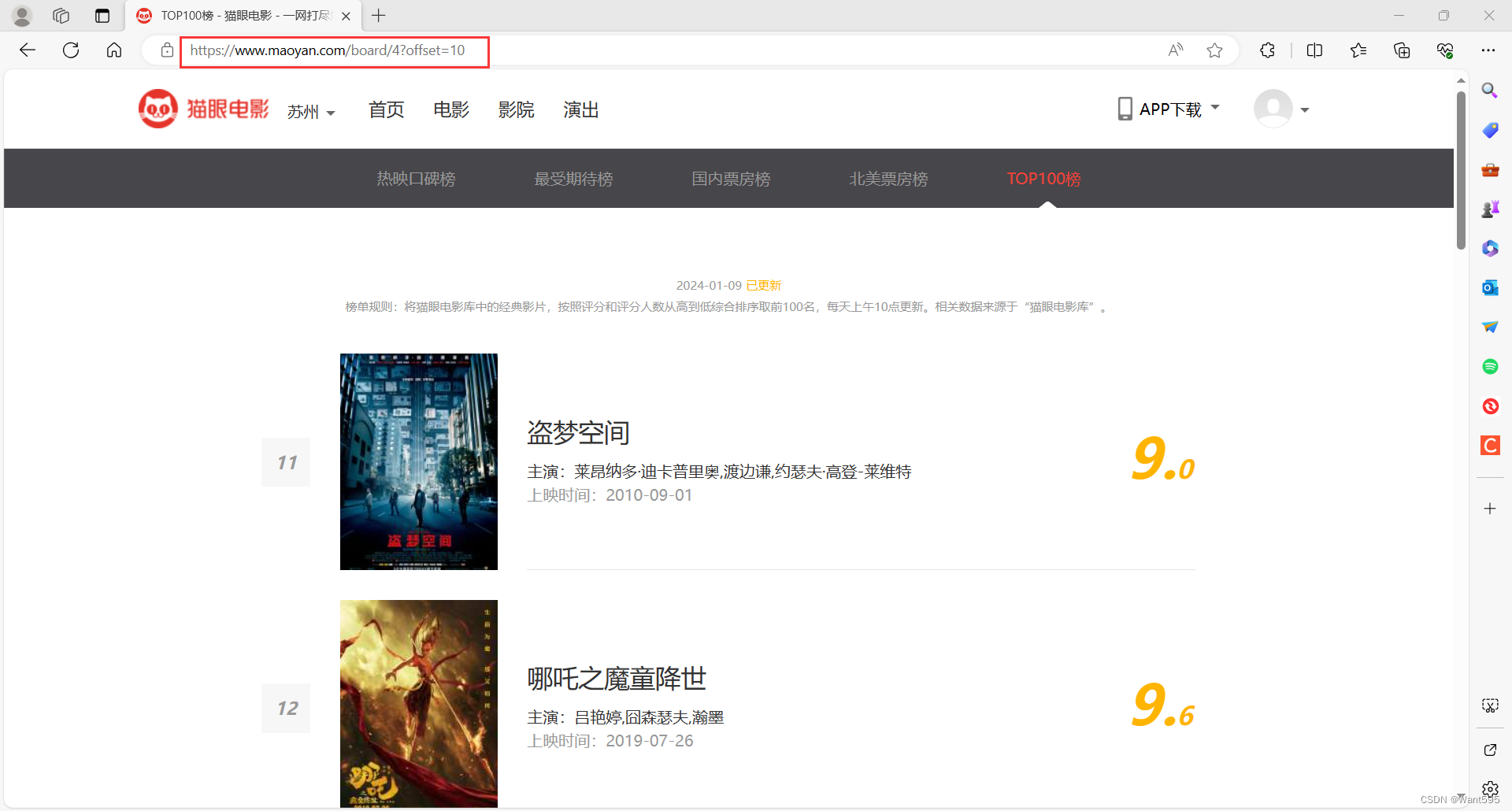
这里不难发现,其实每页的网址是有规律的,0、10、20……网址的最后每次会增加10,也就是说我们要爬取的网址应该是:
Http://films.com/board/4?offset=0 http://films.com/board/4?offset=10 http://films.com/board/4?offset=20 …… http://films.com/board/4?offset=902. 创建mysql数据库
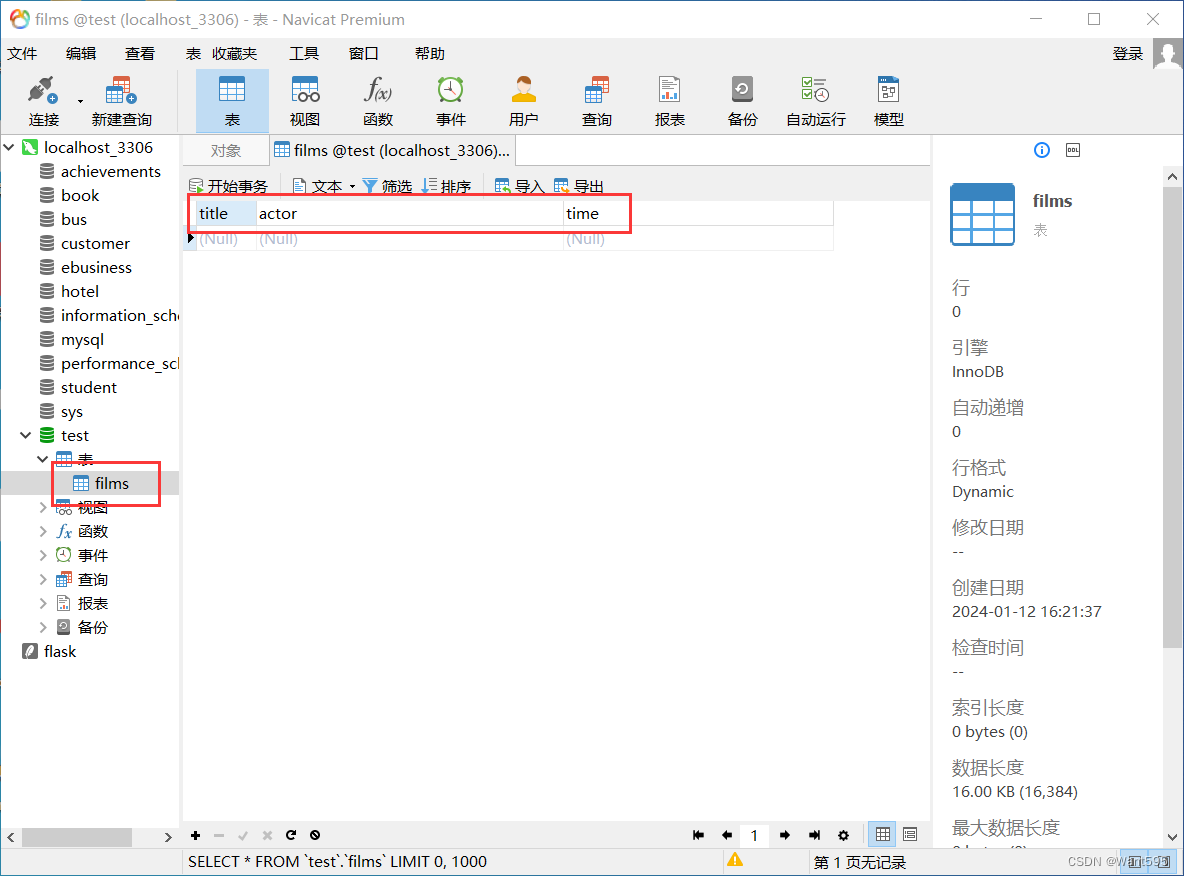
编写"db.py"文件,运行该文件可以连接到mysql数据库并创建本项目需要的电影表:
程序设计
import loggingimport pymysqllogger = logging.getLogger("db_log.txt")fORMatter = logging.Formatter('%(asctime)s %(levelname)s %(message)s')file_handler = logging.FileHandler("db_log.txt")file_handler.setFormatter(formatter)logger.setLevel(logging.INFO)logger.addHandler(file_handler)class DBHelper: def __init__(self, host="localhost", user="root", passWord="123456", db="test", port=3306): self.host = host self.user = user self.password = password self.db = db self.port = port self.conn = None self.cur = None def connectDataBase(self): try: self.conn = pymysql.connect(host="localhost", user="root", password="123456", db="test", port=3306) except: logger.error("connectDataBase Error") return False self.cur = self.conn.cursor() return True def execute(self, sql, params=None): if not self.connectDataBase(): return False try: if self.conn and self.cur: self.cur.execute(sql, params) self.conn.commit() except: logger.error(str(sql)) return False return True def fetchCount(self, sql, params=None): if not self.connectDataBase(): return False self.execute(sql, params) return self.cur.fetchone() def myClose(self): if self.cur: self.cur.close() if self.conn: self.conn.close() return Trueif __name__ == '__main__': dbhelper = DBHelper() sql = 'create table films(title varchar(50), actor varchar(200), time varchar(100));' result = dbhelper.execute(sql, None) if result: print("创建成功") else: print("创建失败,详情见日志文件") dbhelper.myClose() logger.removeHandler(file_handler)程序分析
这段代码是一个封装了数据库操作的工具类 DBHelper。具体分析如下:
该工具类使用了 logging 模块来记录日志信息。首先创建了一个 logger 对象,并设置了记录日志格式和保存日志文件的对象。然后设置日志级别为 INFO,并将 file_handler 添加到 logger 中。
DBHelper 类的构造函数中,初始化了数据库的连接信息(host、user、password、db、port)和连接对象 conn、游标对象 cur。这些连接信息是硬编码的,可以根据实际情况进行修改。
connectDataBase() 方法用于连接数据库。首先尝试使用 pymysql.connect() 方法连接数据库,如果连接失败,则记录错误日志并返回 False。如果连接成功,则返回 True。
execute() 方法用于执行 SQL 语句。该方法首先调用 connectDataBase() 方法来确保数据库连接。然后使用游标对象的 execute() 方法执行 SQL 语句,并提交事务。如果执行过程中出现异常,则记录错误日志并返回 False。如果执行成功,则返回 True。
fetchCount() 方法用于执行查询操作,并返回结果。该方法首先调用 execute() 方法执行 SQL 语句。然后使用游标对象的 fetchone() 方法获取查询结果的第一条记录。如果执行过程中出现异常,则返回 False。如果执行成功,则返回查询结果。
myClose() 方法用于关闭连接和游标。该方法首先判断游标和连接是否存在,如果存在则关闭它们,并返回 True。
在主程序中,首先创建了一个 DBHelper 对象 dbhelper。然后使用 execute() 方法执行了一个创建表的 SQL 语句,并将执行结果存储在 result 变量中。根据执行结果,打印出相应的消息。最后使用 myClose() 方法关闭连接和游标,并将 file_handler 从 logger 中移除。
总的来说,这段代码封装了数据库操作的工具类 DBHelper,通过调用该类的方法,可以实现连接数据库、执行 SQL 语句、获取查询结果等操作。使用 logging 模块记录日志信息,方便调试和错误追踪。该工具类可以在其他代码中被引用,简化了数据库操作的代码编写。
运行结果
3. 尝试抓取热门电影的数据
编写文件"test.py",尝试抓取热门电影的信息:
程序设计
import requestsfrom lxml import etreefrom requests_html import UserAgenturl = "https://www.maoyan.com/board/4?offset=0"ua_headers = { "User-Agent": UserAgent().random}reponse = requests.get(url, headers=ua_headers)tree = etree.HTML(reponse.text)titles = tree.xpath('/html/body/div[4]/div/div/div[1]/dl/dd/div/div/div[1]/p[1]/a/text()')actors = tree.xpath('/html/body/div[4]/div/div/div[1]/dl/dd/div/div/div[1]/p[2]/text()')times = tree.xpath('/html/body/div[4]/div/div/div[1]/dl/dd/div/div/div[1]/p[3]/text()')items = []for i in range(len(titles)): title = titles[i].strip() actor = actors[i].strip() time = times[i].strip() items.append({ 'title': title, 'actor': actor[3:], 'time': time[5:] })for i in items: print(i)程序分析
这段代码是一个简单的爬虫程序,用于从猫眼电影网站上爬取电影的标题、演员和上映时间信息。
首先,导入需要的模块:requests用于发送HTTP请求,lxml用于解析HTML文档,requests_html中的UserAgent类用于生成随机的User-Agent头。然后,定义了要爬取的URL和设置了User-Agent头。使用requests.get()方法发送GET请求,将响应保存在response变量中。接下来,使用etree.HTML()方法将响应的文本内容解析为一个可用于XPath解析的HTML文档树tree。
随后,使用XPath表达式定位到电影标题、演员和上映时间元素,并使用tree.xpath()方法提取出相应的文本内容,保存在titles、actors和times变量中。接下来,使用一个循环遍历这些信息,并通过strip()方法去除首尾的空白字符。然后,将标题、演员和上映时间组合成一个字典,并添加到items列表中。最后,打印出items列表,即爬取到的电影信息。
运行结果

4. 抓取热门电影数据并可视化分析
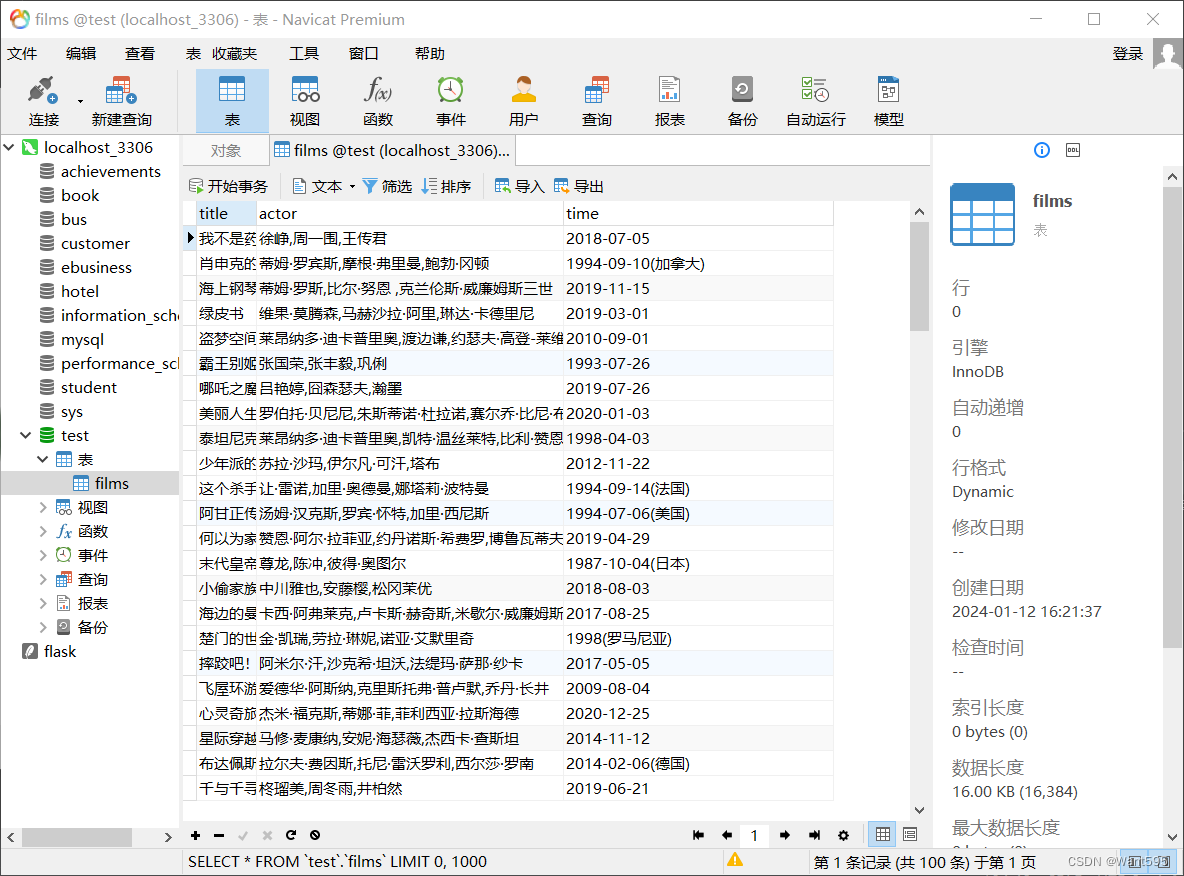
编写文件"films.py",抓取猫眼热门电影的信息,将抓取到的信息先保存到前面创建的mysql数据库中,然后再从数据库中读出来做可视化分析:
程序设计
import requestsimport dbfrom lxml import etreefrom multiprocessing import Pool, Managerimport functoolsimport matplotlib.pyplot as pltfrom requests_html import UserAgentimport loggingplt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题# 获取logger的实例logger = logging.getLogger("films_log.txt")# 指定logger的输出格式formatter = logging.Formatter('%(asctime)s %(levelname)s %(message)s')# 文件日志,终端日志file_handler = logging.FileHandler("films_log.txt")file_handler.setFormatter(formatter)# 设置默认的级别logger.setLevel(logging.INFO)logger.addHandler(file_handler)……完整代码请下载后查看哦~程序分析
该代码实现了一个爬取猫眼电影网站热门电影信息的功能。具体实现过程如下:
导入需要的库,包括requests、db、lxml、multiprocessing、functools和matplotlib.pyplot等。
设置logger,用于记录日志信息,并将日志输出到文件films_log.txt中。
编写函数get_one_page,用于发起HTTP请求,获取网页的响应结果。
编写函数write_to_sql,用于将电影信息写入数据库。
编写函数parse_one_page,用于解析网页内容,提取电影信息。
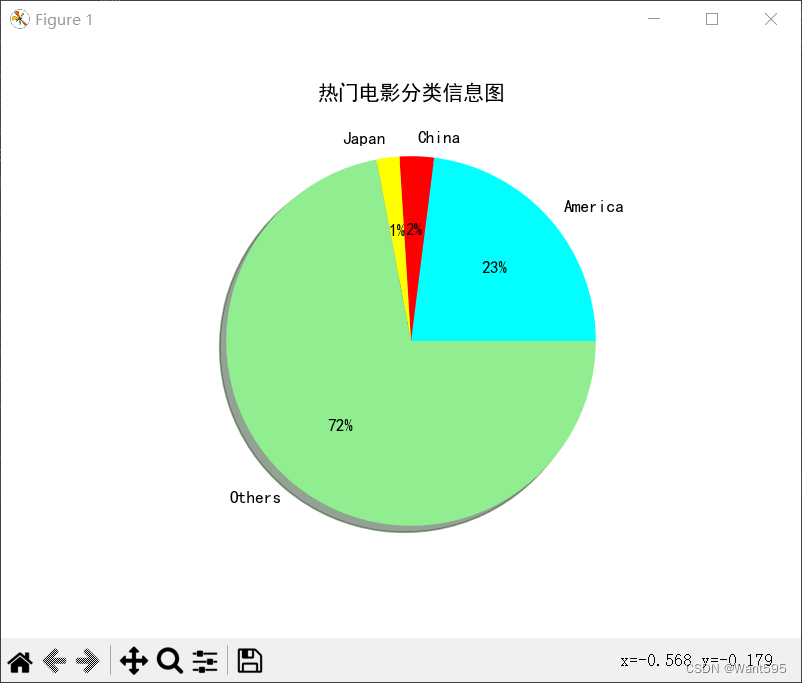
编写函数analysisCounry,用于从数据库中查询每个国家的电影数量,并绘制饼状图进行统计分析。
编写函数CrawlMovieInfo,用于抓取电影信息。该函数接收锁和偏移量作为参数,通过调用get_one_page和parse_one_page函数获取电影信息,并调用write_to_sql函数将信息写入数据库。
在主函数中,创建Manager对象和Lock对象,用于实现多进程间的共享和同步。使用functools.partial函数创建部分应用于CrawlMovieInfo函数的函数partial_CrawlMovieInfo,并创建进程池pool。
使用进程池的map方法将partial_CrawlMovieInfo函数应用于10个偏移量的列表,实现并发地抓取电影信息。
关闭进程池,等待所有进程完成。
移除文件日志处理器,调用analysisCounry函数进行数据分析和可视化。
运行结果
注:如遇到以下问题,完成安全验证就好喽
我是一只有趣的兔子,感谢你的喜欢!
来源地址:https://blog.csdn.net/m0_68111267/article/details/135569457
--结束END--
本文标题: 网络爬虫丨基于requests+mysql爬取猫眼热门电影数据做可视化分析
本文链接: https://www.lsjlt.com/news/556160.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0