文档版本:8.0 来源:buffer pool 上一篇:如何减少和处理死锁 本篇主要介绍InnoDB的缓冲池。 缓冲池(Buffer Pool)是InnoDB在内存中缓存表和索引数据的区域。通过缓冲池,那些被频繁使用的数据就能直接在内
文档版本:8.0
来源:buffer pool
上一篇:如何减少和处理死锁
本篇主要介绍InnoDB的缓冲池。
缓冲池(Buffer Pool)是InnoDB在内存中缓存表和索引数据的区域。通过缓冲池,那些被频繁使用的数据就能直接在内存中访问,从而加快业务处理。在Mysql专用服务器上,最多能有80%的物理内存被用作缓冲池。
为了高效地进行大量读操作,缓冲池被切分成页,每页可以装入多行记录;为了高效进行缓存管理,缓冲池用页的链表实现,通过最近最少使用(LRU)的变种算法,低频使用的数据将会从缓存中淘汰。
作为mysql调优的一个重要方面,我们应该学会如何通过缓冲池让高频数据保持在内存中。
通过LRU的变种算法,缓冲池被当作一个列表管理。当需要向池中添加新页时,最近最少被使用的页面将被移出,从而腾出空间,新页则加入到列表的中间位置。这个中点将列表划分为了两个子表:
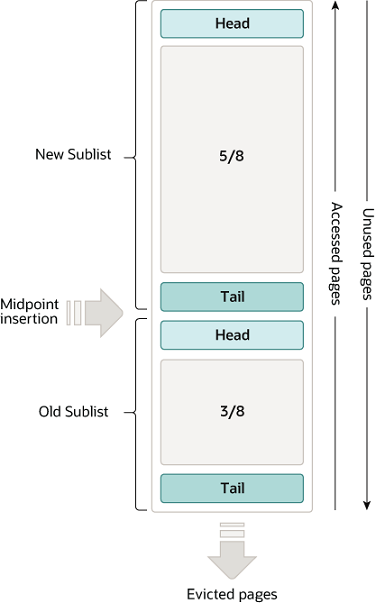
这个算法使频繁访问的页面维持在新表,较少访问的页面维持在老表,老子表中的页面都是被驱逐的候选对象。
当脏页(即在缓冲池里的这段时间被更新的页面)被驱逐时,脏页中的内容将被刷回磁盘,相邻的页面也可能被刷回。
以下是算法的默认设定:
和linux内核的read-ahead机制类似,InnoDB会异步读取一组新页到缓冲池,这组页面是引擎认为可能即将用到的。
具体的预测策略有两种:1.线性预读,直接读取相邻的下一组页面;2.随机预读,将同组内剩余页面全部预读出来。
这里所谓的一组页在InnoDB中叫做“区”:extend,段、预读、双写等InnoDB的特性在读、写、分配、释放等I/O操作的基本单位都是区。
默认情况下,通过用户查询读取的页直接移入新表,意味着存活时间更长。例如, mysqldump触发的扫表,或不带WHERE条件的SELECT语句,会将大量数据带进缓冲池,相应地逐出等量老数据,然而这些新数据可能不会再次使用。类似的,后台预读线程装载进缓冲池的页面,被首次访问时也将移到新表顶部。这些操作都会导致热点数据被迫移动到老表成为驱逐目标。如何去优化这种现象,详见 Section 15.8.3.3, “Making the Buffer Pool Scan Resistant”, 以及 Section 15.8.3.4, “Configuring InnoDB Buffer Pool Prefetching (Read-Ahead)”。
为什么InnoDB在设计缓冲池时没有使用标准的LRU算法,最重要的原因就是尽量去减少上述提到的扫表、预读这些操作所带来的影响。通过中间点插入,用完即扔的页面能够更快的被驱逐,能够一定程度上保护热点数据。
此外,InnoDB还提供了其他辅助策略,如:innodb_old_blocks_time,使进入缓冲池的对象必须等待一段时间(默认为1秒),才允许通过外界访问“年轻化”。
InnoDB标准监视器输出在BUFFER POOL AND MEMORY部分包含了若干有关缓冲池LRU算法操作的字段。详见Monitoring the Buffer Pool Using the InnoDB Standard Monitor。
--结束END--
本文标题: 缓冲池 - MySQL 8.0官方文档笔记(五)
本文链接: https://www.lsjlt.com/news/8549.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0