目录一、spark概述二、Spark的运行模式1)Standalone(本章讲解)2)Mesos3)YARN(推荐)4)k8s(新模式)三、Standalone 模式运行机制1)Standalone Client 模式2)Standalo
Spark基础概念和原理讲解可以参考我上篇博文:大数据Hadoop之——计算引擎Spark
独立模式,自己独立一套集群(master/client/slave),Spark 原生的简单集群管理器, 自带完整的服务, 可单独部署到一个集群中,无需依赖任何其他资源管理系统, 使用 Standalone 可以很方便地搭建一个集群,一般在公司内部没有搭建其他资源管理框架的时候才会使用。缺点:资源不利于充分利用
一个强大的分布式资源管理框架,它允许多种不同的框架部署在其上,包括 yarn,由于mesos这种方式目前应用的比较少,这里没有记录mesos的部署方式。
统一的资源管理机制, 在上面可以运行多套计算框架, 如map reduce、stORM,spark、flink 等, 根据 driver 在集群中的位置不同,分为 yarn client 和 yarn cluster,其实本质就是drive不同。企业里用得最多的一种模式。这种模式环境部署,已经在大数据Hadoop之——计算引擎Spark博文中讲过,这里就不重复了。
K8S 是 Spark 上全新的集群管理和调度系统。由于在实际生产环境下使用的绝大多数的集群管理器是 ON YARN模式,因此我们目前最主要还是关注ON YARN模式,ON K8S模式了解就行,有兴趣的小伙伴可以试试,工作模式如下图所示:

Spark 的运行模式取决于传递给 SparkContext 的 MASTER 环境变量的值, 个别模式还需要辅助的程序接口来配合使用,目前支持的 Master 字符串及 URL 包括:
--deploy-mode:是否将驱动程序(driver)部署在工作节点(cluster)上,或作为外部客户机(client)本地部署(默认值:client)。
| Master URL | 含义 |
|---|---|
| local | 在本地运行,只有一个工作进程,无并行计算能力 |
| local[K] | 在本地运行,有 K 个工作进程,通常设置 K 为机器的CPU 核心数量 |
| local[*] | 在本地运行,工作进程数量等于机器的 CPU 核心数量。 |
| spark://HOST:PORT | 以 Standalone 模式运行,这是 Spark 自身提供的集群运行模式,默认端口号: 7077 |
| mesos://HOST:PORT | 在 Mesos 集群上运行,Driver 进程和 Worker 进程运行在 Mesos 集群上,部署模式必须使用固定值:--deploy-mode cluster |
| yarn | 在yarn集群上运行,依赖于hadoop集群,yarn资源调度框架,将应用提交给yarn,在ApplactionMaster(相当于Stand alone模式中的Master)中运行driver,在集群上调度资源,开启excutor执行任务。 |
| k8s | 在k8s集群上运行 |
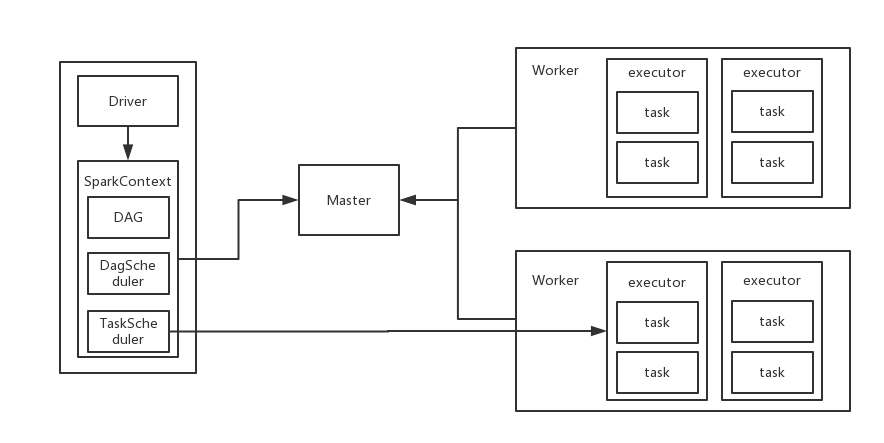
Standalone 集群有四个重要组成部分, 分别是:


【 注意】Standalone的两种模式下(client/Cluster),Master在接到Driver注册Spark应用程序的请求后,会获取其所管理的剩余资源能够启动一个Executor的所有Worker,然后在这些Worker之间分发Executor,此时的分发只考虑Worker上的资源是否足够使用,直到当前应用程序所需的所有Executor都分配完毕,Executor反向注册完毕后,Driver开始执行main程序。
| 机器IP | 机器名 | 节点类型 |
|---|---|---|
| 192.168.0.113 | hadoop-node1 | Master/Worker |
| 192.168.0.114 | hadoop-node2 | Worker |
| 192.168.0.115 | hadoop-node3 | Worker |
之前安装Hadoop集群的时候已经安装过了,这里就略过了,不清楚的可以参考我之前的文章:大数据Hadoop原理介绍+安装+实战操作(hdfs+YARN+mapReduce)

这里需要注意版本,我的hadoop版本是3.3.1,这里spark就下载最新版本的3.2.0,而Spark3.2.0依赖的Scala的2.13,所以后面用到Scala编程时注意Scala的版本。
$ cd /opt/bigdata/hadoop/software
# 下载
$ wget https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz
# 解压
$ tar -zxvf spark-3.2.0-bin-hadoop3.2.tgz -C /opt/bigdata/hadoop/server/
# 修改安装目录名称
$ cp -r /opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2 /opt/bigdata/hadoop/server/spark-standalone-3.2.0-bin-hadoop3.2
配置slaves文件
$ cd /opt/bigdata/hadoop/server/spark-standalone-3.2.0-bin-hadoop3.2/conf
$ cp workers.template workers
# slaves文件内容如下:
hadoop-node1
hadoop-node2
hadoop-node3
hadoop-node1即是master,也是worker
配置spark-env.sh
$ cd /opt/bigdata/hadoop/server/spark-standalone-3.2.0-bin-hadoop3.2/conf
# 创建data目录(所有节点都得创建这个目录)
$ mkdir -p /opt/bigdata/hadoop/data/spark-standalone
# copy一份环境变量文件
$ cp spark-env.sh.template spark-env.sh
# 加入以下内容:
export SPARK_MASTER_HOST=hadoop-node1
export SPARK_LOCAL_DIRS=/opt/bigdata/hadoop/data/spark-standalone
配置spark-defaults.conf
这里不做修改,如果需要修改,自行修改就行,默认端口7077
$ cp spark-defaults.conf.template spark-defaults.conf
$ cat spark-defaults.conf

$ scp -r spark-standalone-3.2.0-bin-hadoop3.2 hadoop-node2:/opt/bigdata/hadoop/server/
$ scp -r spark-standalone-3.2.0-bin-hadoop3.2 hadoop-node3:/opt/bigdata/hadoop/server/
$ cd /opt/bigdata/hadoop/server/spark-standalone-3.2.0-bin-hadoop3.2/sbin
$ ./start-master.sh
# 查看进程端口,spark master WEB ui 默认端口为8080
$ ss -tNLP|grep :8080
# 如果端口冲突,修改start-master.sh脚本里的端口即可
$ grep SPARK_MASTER_WEBUI_PORT start-master.sh

访问spark master web ui:http://hadoop-node1:8080

$ cd /opt/bigdata/hadoop/server/spark-standalone-3.2.0-bin-hadoop3.2/sbin
$ ./start-worker.sh spark://hadoop-node1:7077

spark-submit 详细参数说明
| 参数名 | 参数说明 |
|---|---|
| --master | master 的地址,提交任务到哪里执行,例如 spark://host:port, yarn, local |
| --deploy-mode | 在本地 (client) 启动 driver 或在 cluster 上启动,默认是 client |
| --class | 应用程序的主类,仅针对 java 或 scala 应用 |
| --name | 应用程序的名称 |
| --jars | 用逗号分隔的本地 jar 包,设置后,这些 jar 将包含在 driver 和 executor 的 classpath 下 |
| --packages | 包含在driver 和executor 的 classpath 中的 jar 的 Maven 坐标 |
| --exclude-packages | 为了避免冲突 而指定不包含的 package |
| --repositories | 远程 repository |
| --conf PROP=VALUE | 指定 spark 配置属性的值, 例如 -conf spark.executor.extraJavaoptions="-XX:MaxPermSize=256m" |
| --properties-file | 加载的配置文件,默认为 conf/spark-defaults.conf |
| --driver-memory | Driver内存,默认 1G |
| --driver-java-options | 传给 driver 的额外的 Java 选项 |
| --driver-library-path | 传给 driver 的额外的库路径 |
| --driver-class-path | 传给 driver 的额外的类路径 |
| --driver-cores | Driver 的核数,默认是1。在 yarn 或者 standalone 下使用 |
| --executor-memory | 每个 executor 的内存,默认是1G |
| --total-executor-cores | 所有 executor 总共的核数。仅仅在 mesos 或者 standalone 下使用 |
| --num-executors | 启动的 executor 数量。默认为2。在 yarn 下使用 |
| --executor-core | 每个 executor 的核数。在yarn或者standalone下使用 |
$ cd /opt/bigdata/hadoop/server/spark-standalone-3.2.0-bin-hadoop3.2/bin
$ ./spark-submit
--class org.apache.spark.examples.SparkPi
--master spark://hadoop-node1:7077
--deploy-mode client
--driver-memory 1G
--executor-memory 1G
--total-executor-cores 2
--executor-cores 1
/opt/bigdata/hadoop/server/spark-standalone-3.2.0-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.2.0.jar 10
这种模式运行结果,直接在客户端显示出来了。

$ cd /opt/bigdata/hadoop/server/spark-standalone-3.2.0-bin-hadoop3.2/bin
$ ./spark-submit
--class org.apache.spark.examples.SparkPi
--master spark://hadoop-node1:7077
--deploy-mode cluster
--driver-memory 1G
--executor-memory 1G
--total-executor-cores 2
--executor-cores 1
/opt/bigdata/hadoop/server/spark-standalone-3.2.0-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.2.0.jar 10
这种模式基本上没什么输出信息,需要登录web页面查看

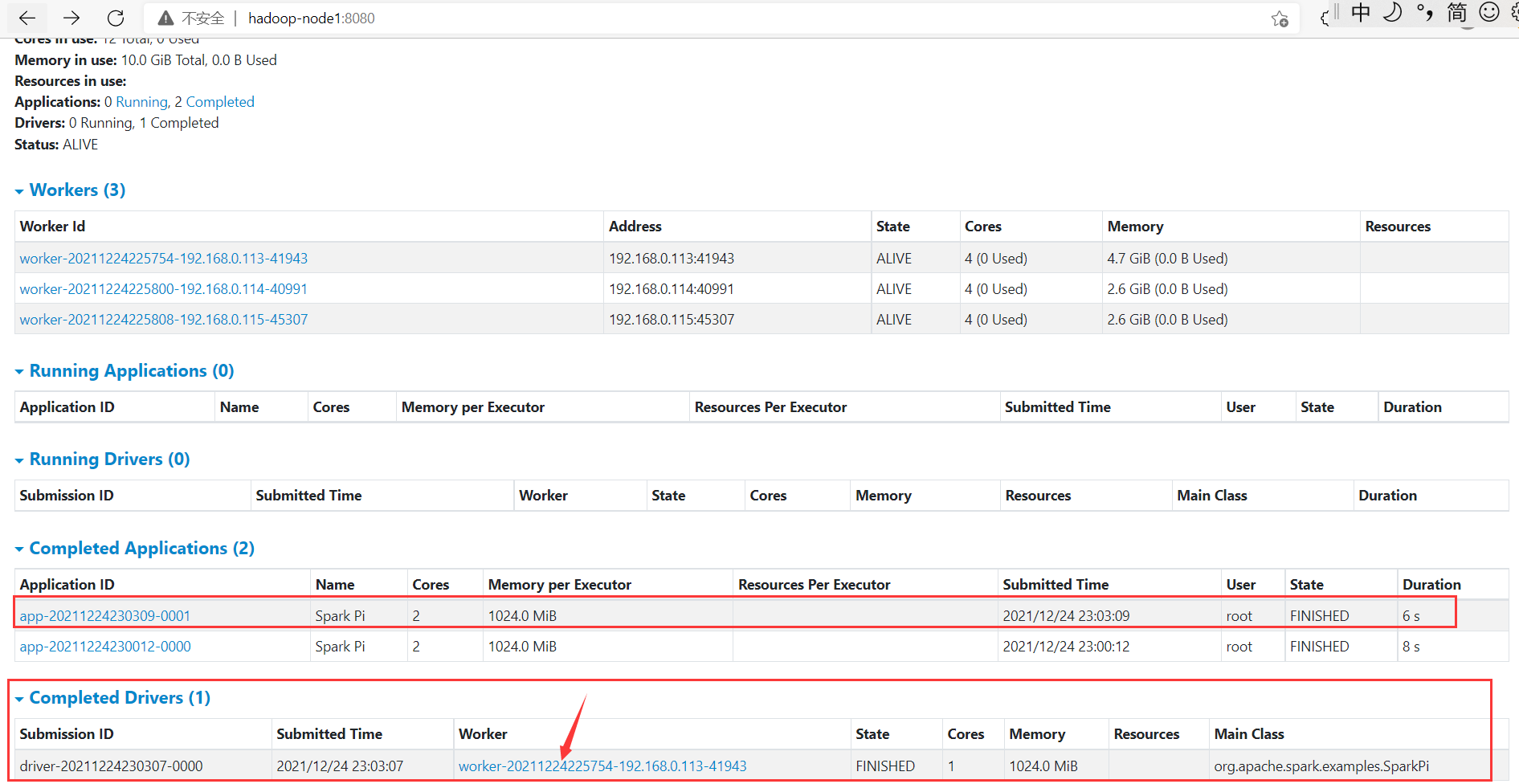
查看driver日志信息
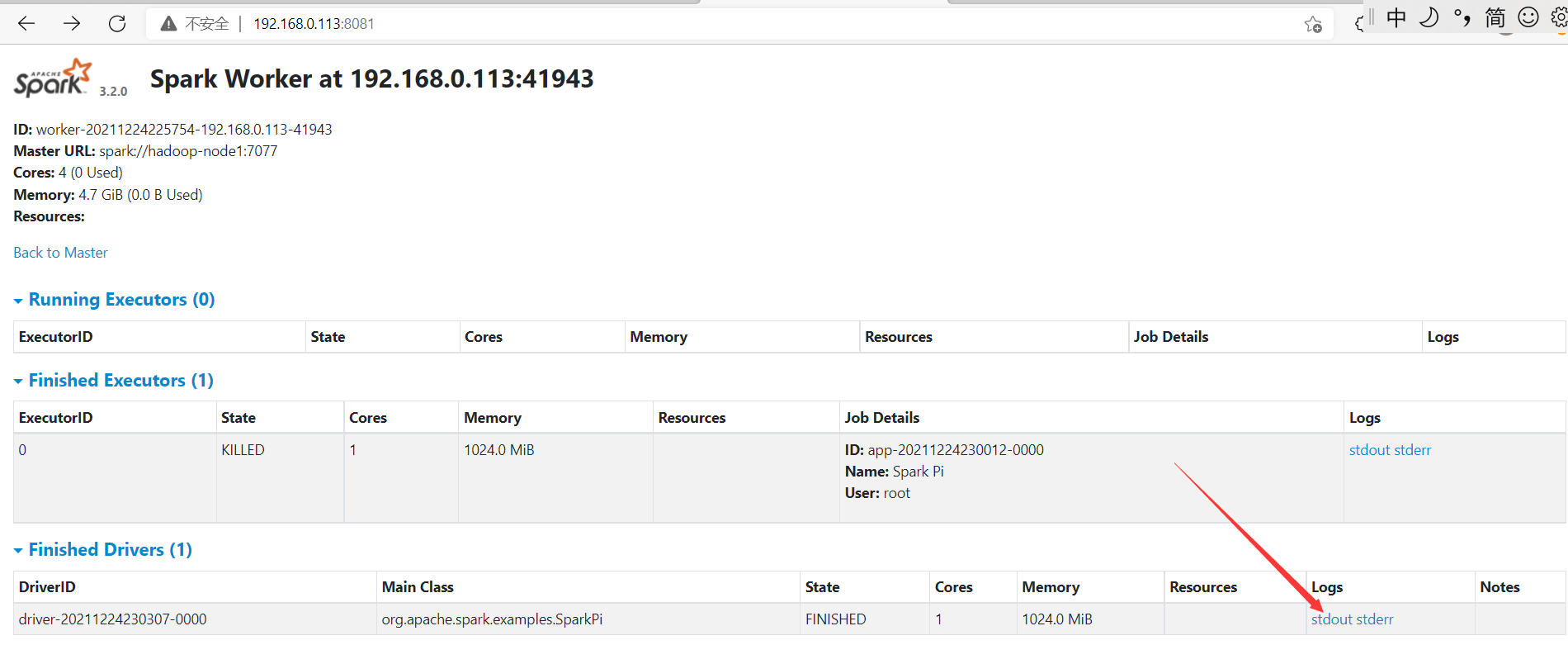
最终在driver日志里查看运行结果了。

【温馨提示】目前企业里用的最多的模式还是on yarn模式,Standalone模式了解就行。
原文地址:https://www.cnblogs.com/liugp/arcHive/2022/04/16/16153043.html
--结束END--
本文标题: 大数据Hadoop之——Spark集群部署(Standalone)
本文链接: https://www.lsjlt.com/news/9267.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-16
2024-05-16
2024-05-16
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
2024-05-15
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0