SET FOREIGN_KEY_CHECKS=0; -- ---------------------------- -- Table structure&nbs
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for queryreptycode
-- ----------------------------
DROP TABLE IF EXISTS `queryreptycode`;
CREATE TABLE `queryreptycode` (
`id` int(11) NOT NULL,
`code` varchar(50) DEFAULT NULL,
`codeRepty` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of queryreptycode
-- ----------------------------
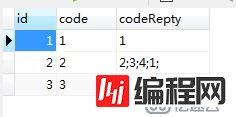
INSERT INTO `queryreptycode` VALUES ('1', '1', '1');
INSERT INTO `queryreptycode` VALUES ('2', '2', '2;3;4;1;');
INSERT INTO `queryreptycode` VALUES ('3', '3', '1;');数据为:
select DISTINCT Q1.id,Q1.code,Q1.codeRepty from queryreptycode as Q1 INNER JOINqueryreptycode as Q2
where INSTR(Q1.`code`,'%'+Q2.codeRepty+'%')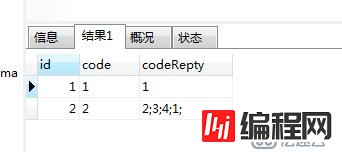
原理:
函数INSTR会告诉用户,其中的一个字符串(参数)是否在另一个字符串(也是参数)当中。
其具体的语法格式如下:
INSTR(string,substring[,start[,occurrence]])
其中:
string 待查询的字符串
substring 正在搜索的字符串
start 说明开始搜索的字符位置。默认值是1,就是说,搜索将从字符串的第一个字符开始。如果,参数为负 则表示搜索的位置从右边开始计算,而不是默认的从左边开始
occurrence 指定试图搜索的子串的第几次出现,默认值是1,意 味着希望其首次出现
该函数反馈一索引顺序值,在该位置发现了要搜索的子串。下面的例子指出了INSTR函数的使用情况:
INSTR(‘AAABAABA’,’B’)=4
INSTR(‘AAABAABA’,’B’,1,2)=7
--结束END--
本文标题: sql 一个字段是否包含另一个字段
本文链接: http://www.lsjlt.com/news/48430.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-06-02
2024-06-02
2024-06-02
2024-06-02
2024-06-02
2024-06-02
2024-06-02
2024-06-02
2024-06-02
2024-06-02
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0