Python 官方文档:入门教程 => 点击学习
目录python实现对网易云音乐的数据进行一个数据清洗和可视化分析对音乐数据进行数据清洗与可视化分析对音乐数据进行数据清洗与可视化分析歌词文本分析总结Python实现对网易云音乐的数据进行一个数据清洗和可视化分析 对
关于数据的清洗,实际上在上一一篇文章关于抓取数据的过程中已经做了一部分,后面我又做了一下用户数据的抓取
歌曲评论:
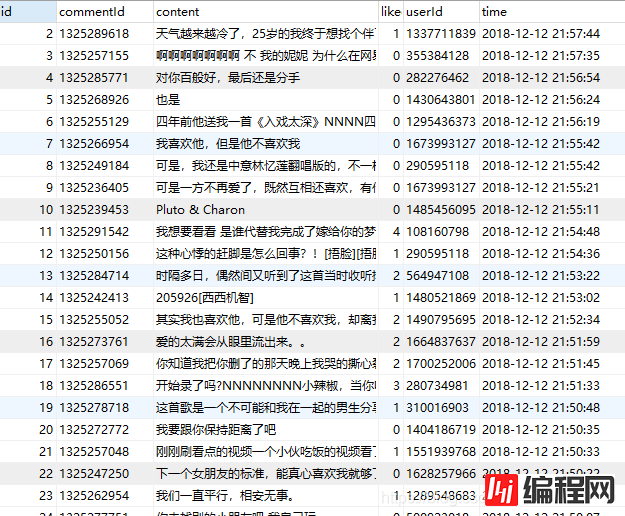
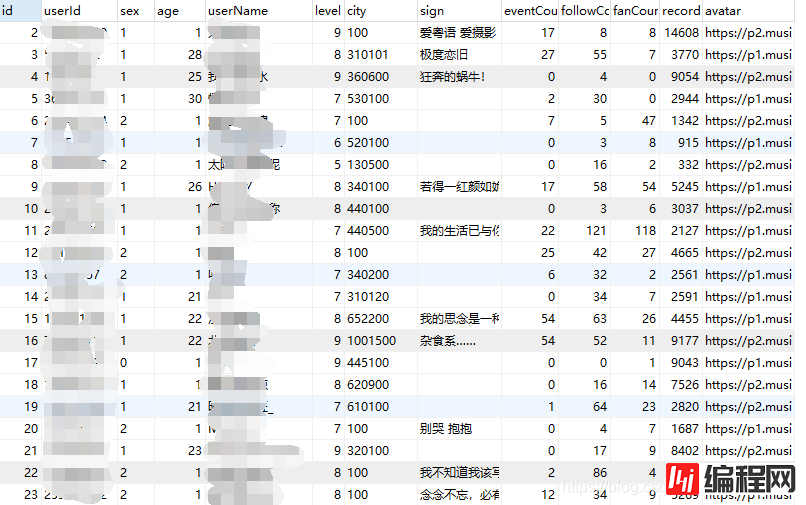
包括后台返回的空用户信息、重复数据的去重等。除此之外,还要进行一些清洗:用户年龄错误、用户城市编码转换等。
关于数据的去重,评论部分可以以sommentId为数据库索引,利用数据库来自动去重;用户信息部分以用户ID为数据库索引实现自动去重。
api返回的用户年龄一般是时间戳的形式(以毫秒计)、有时候也会返回一个负值或者一个大于当前时间的值,暂时没有找到这两种值代表的含义,故而一律按0来处理。
API返回的用户信息中,城市分为province和city两个字段,本此分析中只保存了city字段。实际上字段值是一个城市code码,具体对照在这里下载。
利用Python的数据处理库pandas进行数据处理,利用可视化库pyecharts进行数据可视化。
分别查看下面分析结果。
import pandas as pd
import pyMysql
from pyecharts import Bar,Pie,Line,Scatter,Map
TABLE_COMMENTS = '****'
TABLE_USERS = '****'
DATABASE = '****'
conn = pymysql.connect(host='localhost', user='****', passwd='****', db=DATABASE, charset='utf8mb4')
sql_users = 'SELECT id,gender,age,city FROM '+TABLE_USERS
sql_comments = 'SELECT id,time FROM '+TABLE_COMMENTS
comments = pd.read_sql(sql_comments, con=conn)
users = pd.read_sql(sql_users, con=conn)
# 评论时间(按天)分布分析
comments_day = comments['time'].dt.date
data = comments_day.id.groupby(comments_day['time']).count()
line = Line('评论时间(按天)分布')
line.use_theme('dark')
line.add(
'',
data.index.values,
data.values,
is_fill=True,
)
line.render(r'./评论时间(按天)分布.html')
# 评论时间(按小时)分布分析
comments_hour = comments['time'].dt.hour
data = comments_hour.id.groupby(comments_hour['time']).count()
line = Line('评论时间(按小时)分布')
line.use_theme('dark')
line.add(
'',
data.index.values,
data.values,
is_fill=True,
)
line.render(r'./评论时间(按小时)分布.html')
# 评论时间(按周)分布分析
comments_week = comments['time'].dt.dayofweek
data = comments_week.id.groupby(comments_week['time']).count()
line = Line('评论时间(按周)分布')
line.use_theme('dark')
line.add(
'',
data.index.values,
data.values,
is_fill=True,
)
line.render(r'./评论时间(按周)分布.html')
# 用户年龄分布分析
age = users[users['age']>0] # 清洗掉年龄小于1的数据
age = age.id.groupby(age['age']).count() # 以年龄值对数据分组
Bar = Bar('用户年龄分布')
Bar.use_theme('dark')
Bar.add(
'',
age.index.values,
age.values,
is_fill=True,
)
Bar.render(r'./用户年龄分布图.html') # 生成渲染的html文件
# 用户地区分布分析
# 城市code编码转换
def city_group(cityCode):
city_map = {
'11': '北京',
'12': '天津',
'31': '上海',
'50': '重庆',
'5e': '重庆',
'81': '香港',
'82': '澳门',
'13': '河北',
'14': '山西',
'15': '内蒙古',
'21': '辽宁',
'22': '吉林',
'23': '黑龙江',
'32': '江苏',
'33': '浙江',
'34': '安徽',
'35': '福建',
'36': '江西',
'37': '山东',
'41': '河南',
'42': '湖北',
'43': '湖南',
'44': '广东',
'45': '广西',
'46': '海南',
'51': '四川',
'52': '贵州',
'53': '云南',
'54': '西藏',
'61': '陕西',
'62': '甘肃',
'63': '青海',
'64': '宁夏',
'65': '新疆',
'71': '台湾',
'10': '其他',
}
return city_map[cityCode[:2]]
city = users['city'].apply(city_group)
city = city.id.groupby(city['city']).count()
map_ = Map('用户地区分布图')
map_.add(
'',
city.index.values,
city.values,
maptype='china',
is_visualmap=True,
visual_text_color='#000',
is_label_show=True,
)
map_.render(r'./用户地区分布图.html')
可视化结果
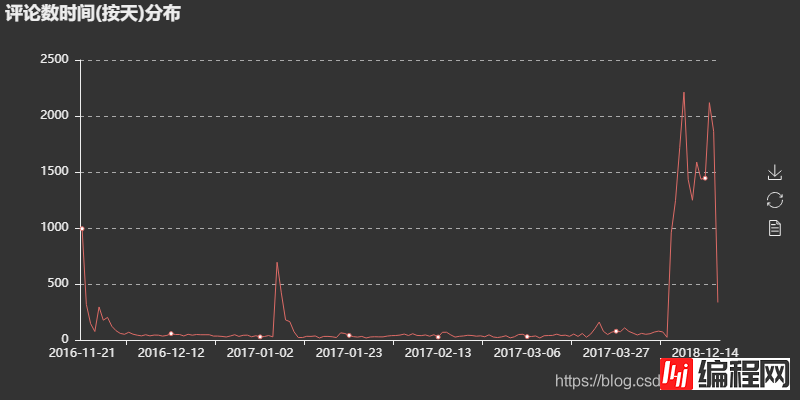
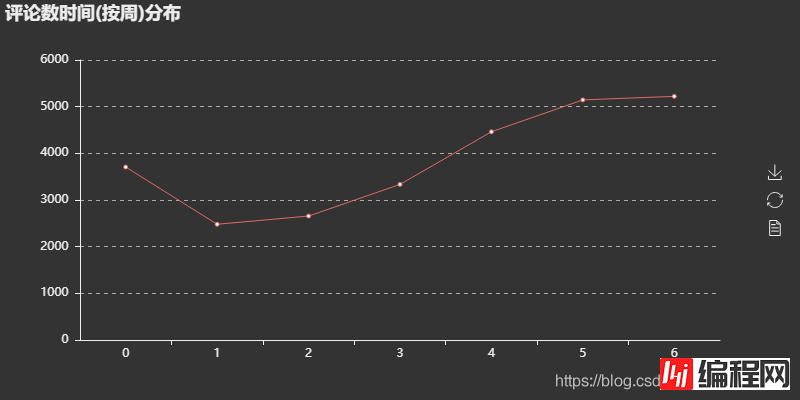
评论时间按周分布图可以看出,评论数在一周当中前面较少,后面逐渐增多,这可以解释为往后接近周末,大家有更多时间来听听歌、刷刷歌评,而一旦周末过完,评论量马上下降(周日到周一的下降过渡),大家又回归到工作当中。
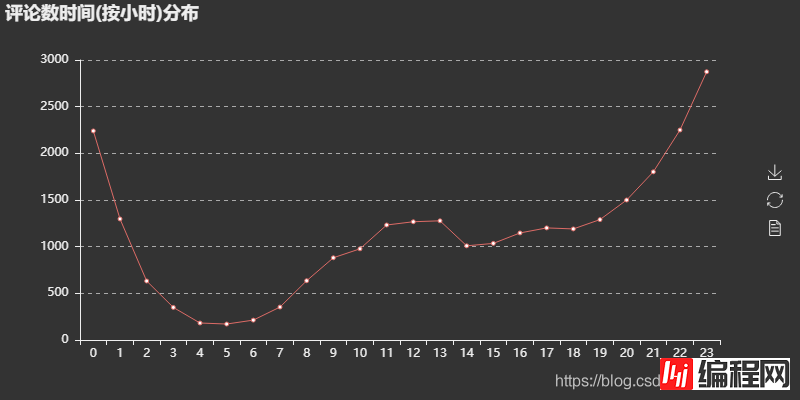
评论时间按小时分布图可以看出,评论数在一天当中有两个小高峰:11点-13点和22点-0点。这可以解释为用户在中午午饭时间和晚上下班(课)在家时间有更多的时间来听歌刷评论,符合用户的日常。至于为什么早上没有出现一个小高峰,大概是早上大家都在抢时间上班(学),没有多少时间去刷评论。
https://blog.csdn.net/u011371360
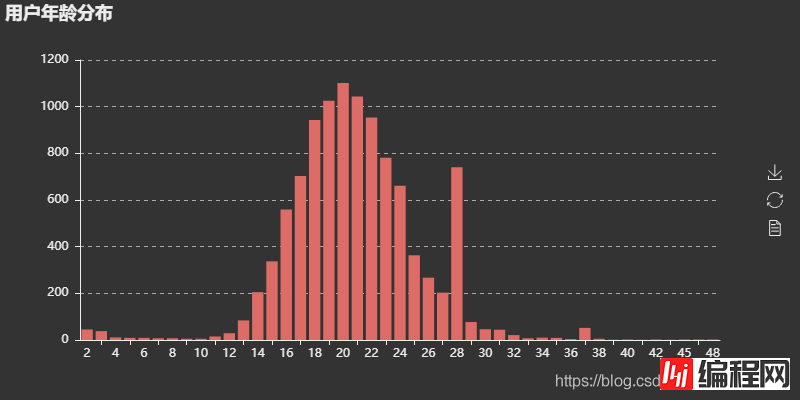
用户年龄分布图可以看出,用户大多集中在14-30岁之间,以20岁左右居多,除去虚假年龄之外,这个年龄分布也符合网易云用户的年龄段。图中可以看出28岁有个高峰,猜测可能是包含了一些异常数据,有兴趣的化可以做进一步分析。
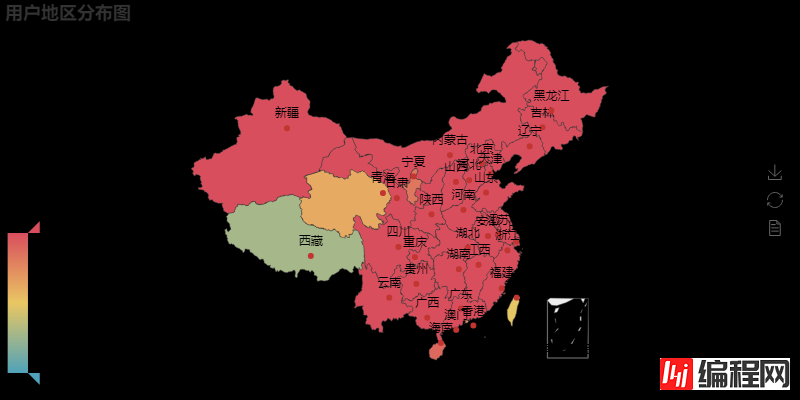
用户地区分布图可以看出,用户涵盖了全国各大省份,因为中间数据(坑)的缺失,并没有展现出哪个省份特别突出的情况。对别的歌评(完全数据)的可视化分析,可以看出明显的地区分布差异。
此次分析只是对某一首歌曲评论时间、用户年龄/地区分布进行的,实际上抓取到的信息不仅仅在于此,可以做进一步分析(比如利用评论内容进行文本内容分析等),这部分,未来会进一步分析。当然也可以根据自己情况对不同歌曲进行分析。
情感分析采用Python的文本分析库snowNLP,代码如下:
import numpy as np
import pymysql
from snownlp import SnowNLP
from pyecharts import Bar
TABLE_COMMENTS = '****'
DATABASE = '****'
SONGNAME = '****'
def getText():
conn = pymysql.connect(host='localhost', user='root', passwd='root', db=DATABASE, charset='utf8')
sql = 'SELECT id,content FROM '+TABLE_COMMENTS
text = pd.read_sql(sql%(SONGNAME), con=conn)
return text
def getSemi(text):
text['content'] = text['content'].apply(lambda x:round(SnowNLP(x).sentiments, 2))
semiscore = text.id.groupby(text['content']).count()
bar = Bar('评论情感得分')
bar.use_theme('dark')
bar.add(
'',
y_axis = semiscore.values,
x_axis = semiscore.index.values,
is_fill=True,
)
bar.render(r'情感得分分析.html')
text['content'] = text['content'].apply(lambda x:1 if x>0.5 else -1)
semilabel = text.id.groupby(text['content']).count()
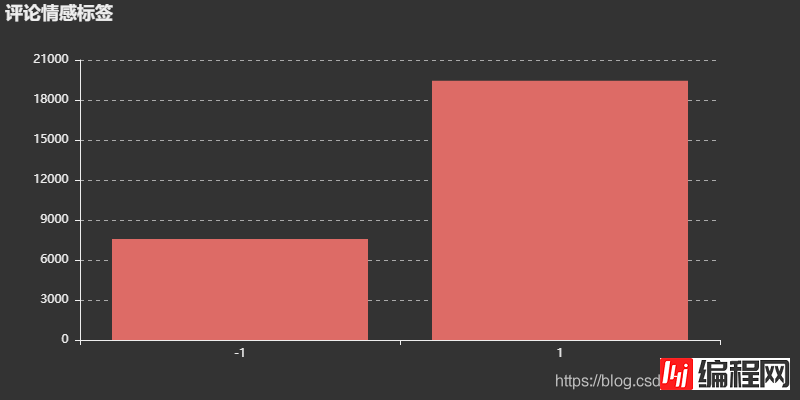
bar = Bar('评论情感标签')
bar.use_theme('dark')
bar.add(
'',
y_axis = semilabel.values,
x_axis = semilabel.index.values,
is_fill=True,
)
bar.render(r'情感标签分析.html')
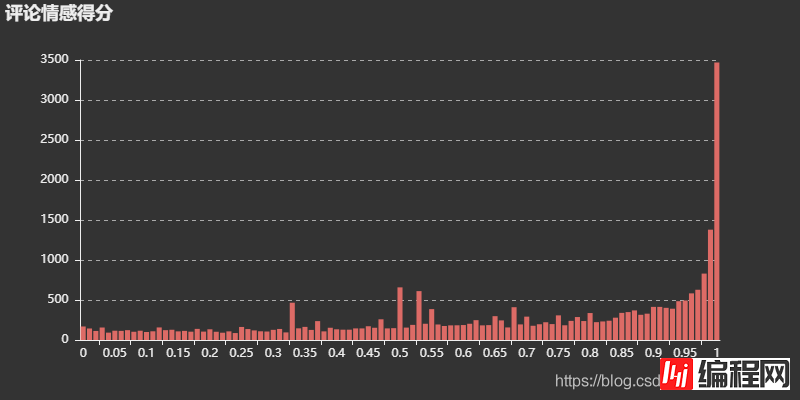
结果:
词云生成采用jieba分词库分词,Wordcloud生成词云,代码如下:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.rcParams['axes.unicode_minus'] = False
def getWordcloud(text):
text = ''.join(str(s) for s in text['content'] if s)
word_list = jieba.cut(text, cut_all=False)
stopwords = [line.strip() for line in open(r'./StopWords.txt', 'r').readlines()] # 导入停用词
clean_list = [seg for seg in word_list if seg not in stopwords] #去除停用词
clean_text = ''.join(clean_list)
# 生成词云
cloud = WordCloud(
font_path = r'C:/windows/Fonts/msyh.ttc',
background_color = 'white',
max_words = 800,
max_font_size = 64
)
word_cloud = cloud.generate(clean_text)
# 绘制词云
plt.figure(figsize=(12, 12))
plt.imshow(word_cloud)
plt.axis('off')
plt.show()
if __name__ == '__main__':
text = getText()
getSemi(text)
getWordcloud(text)
本篇文章就到这里了,希望能给你带来帮助,也希望您能够多多关注编程网的更多内容!
--结束END--
本文标题: 用Python实现网易云音乐的数据进行数据清洗和可视化分析
本文链接: https://www.lsjlt.com/news/11222.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0