Python 官方文档:入门教程 => 点击学习
整个数据获取的信息是通过房源平台获取的,通过下载网页元素并进行数据提取分析完成整个过程 导入相关的网页下载、数据解析、数据处理库 from fake_useragent impor
整个数据获取的信息是通过房源平台获取的,通过下载网页元素并进行数据提取分析完成整个过程
导入相关的网页下载、数据解析、数据处理库
from fake_useragent import UserAgent # 身份信息生成库
from bs4 import BeautifulSoup # 网页元素解析库
import numpy as np # 科学计算库
import requests # 网页下载库
from requests.exceptions import RequestException # 网络请求异常库
import pandas as pd # 数据处理库
然后,在开始之前初始化一个身份信息生成的对象,用于后面随机生成网页下载时的身份信息。
user_agent = UserAgent()
编写一个网页下载函数get_html_txt,从相应的url地址下载网页的html文本。
def get_html_txt(url, page_index):
'''
获取网页html文本信息
:param url: 爬取地址
:param page_index:当前页数
:return:
'''
try:
headers = {
'user-agent': user_agent.random
}
response = requests.request("GET", url, headers=headers, timeout=10)
html_txt = response.text
return html_txt
except RequestException as e:
print('获取第{0}页网页元素失败!'.fORMat(page_index))
return ''
编写网页元素处理函数catch_html_data,用于解析网页元素,并将解析后的数据元素保存到csv文件中。
def catch_html_data(url, page_index):
'''
处理网页元素数据
:param url: 爬虫地址
:param page_index:
:return:
'''
# 下载网页元素
html_txt = str(get_html_txt(url, page_index))
if html_txt.strip() != '':
# 初始化网页元素对象
beautifulSoup = BeautifulSoup(html_txt, 'lxml')
# 解析房源列表
h_list = beautifulSoup.select('.resblock-list-wrapper li')
# 遍历当前房源的详细信息
for n in range(len(h_list)):
h_detail = h_list[n]
# 提取房源名称
h_detail_name = h_detail.select('.resblock-name a.name')
h_detail_name = [m.get_text() for m in h_detail_name]
h_detail_name = ' '.join(map(str, h_detail_name))
# 提取房源类型
h_detail_type = h_detail.select('.resblock-name span.resblock-type')
h_detail_type = [m.get_text() for m in h_detail_type]
h_detail_type = ' '.join(map(str, h_detail_type))
# 提取房源销售状态
h_detail_status = h_detail.select('.resblock-name span.sale-status')
h_detail_status = [m.get_text() for m in h_detail_status]
h_detail_status = ' '.join(map(str, h_detail_status))
# 提取房源单价信息
h_detail_price = h_detail.select('.resblock-price .main-price .number')
h_detail_price = [m.get_text() for m in h_detail_price]
h_detail_price = ' '.join(map(str, h_detail_price))
# 提取房源总价信息
h_detail_total_price = h_detail.select('.resblock-price .second')
h_detail_total_price = [m.get_text() for m in h_detail_total_price]
h_detail_total_price = ' '.join(map(str, h_detail_total_price))
h_info = [h_detail_name, h_detail_type, h_detail_status, h_detail_price, h_detail_total_price]
h_info = np.array(h_info)
h_info = h_info.reshape(-1, 5)
h_info = pd.DataFrame(h_info, columns=['房源名称', '房源类型', '房源状态', '房源均价', '房源总价'])
h_info.to_csv('北京房源信息.csv', mode='a+', index=False, header=False)
print('第{0}页房源信息数据存储成功!'.format(page_index))
else:
print('网页元素解析失败!')
编写多线程处理函数,初始化网络网页下载地址,并使用多线程启动调用业务处理函数catch_html_data,启动线程完成整个业务流程。
import threading # 导入线程处理模块
def thread_catch():
'''
线程处理函数
:return:
'''
for num in range(1, 50, 3):
url_pre = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num))
url_cur = "Https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 1))
url_aft = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 2))
thread_pre = threading.Thread(target=catch_html_data, args=(url_pre, num))
thread_cur = threading.Thread(target=catch_html_data, args=(url_cur, num + 1))
thread_aft = threading.Thread(target=catch_html_data, args=(url_aft, num + 2))
thread_pre.start()
thread_cur.start()
thread_aft.start()
thread_catch()
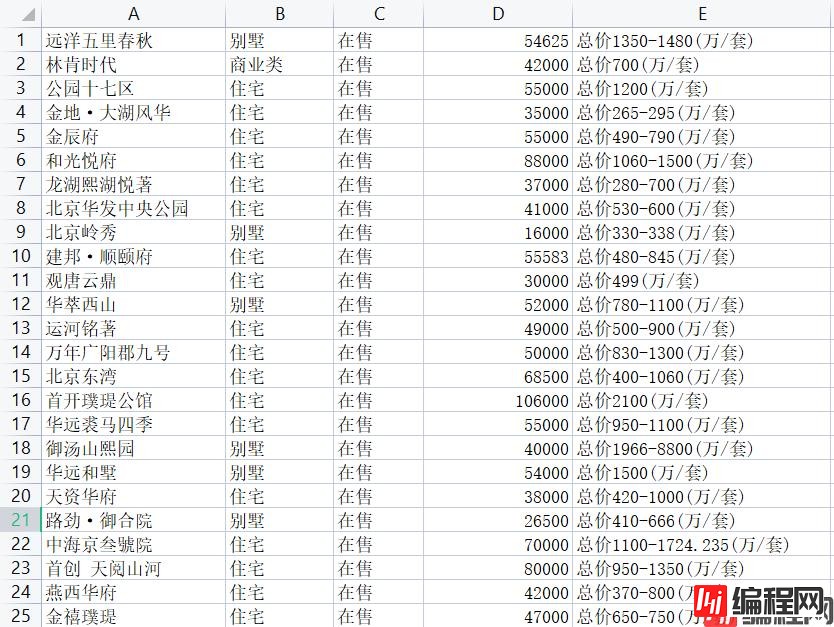
数据存储结果展示效果
以上就是基于python实现最新房价信息的获取的详细内容,更多关于Python获取房价信息的资料请关注编程网其它相关文章!
--结束END--
本文标题: 基于Python实现最新房价信息的获取
本文链接: https://www.lsjlt.com/news/117380.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0