Python 官方文档:入门教程 => 点击学习
目录清理重复的文件清理重复文件的优化1清理重复文件的优化2清理重复文件的优化3批量修改文件名清理重复的文件 已知条件: 什么都不知道,只需要知道它是文件就可以了 实现方法: 可以从指
已知条件:
什么都不知道,只需要知道它是文件就可以了
实现方法:
可以从指定路径(或最上层路径)开始读取,利用 glob 读取每个文件夹,读到文件,记录名称和大小,每一次检测之前是否读取过相同名称的文件,如果存在,判断大小是否相同,如果相同,我们就认为这是重复文件,将其删除。
代码示例如下:
# coding:utf-8
import glob
import os.path
data = {} # 定义一个空的字典,暂时将文件名存进来
def clear(path):
result = glob.glob(path) # 将 path 路径传入,赋值给 result
for _data in result: # for 循环判断是否是文件夹
if glob.os.path.isdir(_data): # 若是文件夹,继续将该文件夹的路径传给 clear() 函数继续递归查找
_path = glob.os.path.join(_data, '*')
clear(_path)
else: # 若是文件,则将文件名提取出来
name = glob.os.path.split(_data)[-1]
if 'zip' in name: # 因为目前我们测试的 path 下有 ".zip" 文件,所以这里跳过 '.zip' 压缩文件的读取否则会报错
continue
f = open(_data, 'r') # 判断文件名之前先将内容读取出来,若是不可读模式
content = f.read() # 将读取内容赋值给 content
if name in data: # 判断文件名是否已存在 data 这个临时存储文件名的字典内,如果存在则进行执行删除动作
_content_dict = data[name]
if _content_dict == content:
print('文件 \"{}\" 被删除...'.fORMat(_data)) # 调试
os.remove(_data)
else:
data[name] = content
if __name__ == '__main__':
path = glob.os.path.join(glob.os.getcwd(), 'test_file')
clear(path)
PS:这里需要注意一下,如果path的路径是根目录的话,会出现超级意外的结果,建议还是建立一个单独的文件夹路径来测试吧。(这个坑踩的我很心痛....)
运行结果如下:
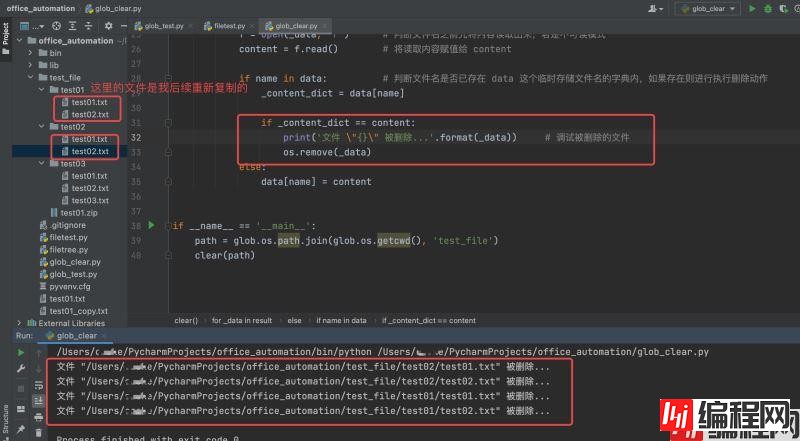
解决不同路径下相同文件名不同内容问题
其实在这里大家能够想到一个问题,可能会存在这样一种情况,在不同的文件夹下存在着相同文件名,但是文件的内容却是不相同的。如果利用上面的脚本执行针对文件夹下相同文件名的文件进行删除的话,其实是一种不严谨的操作。
由此也就引出了我们接下来针对上文脚本优化的需求。
这里我们先看一下实际情况的 data 的值应该是怎样的:data = {'name': {'path/name': 'content', 'path2/name': 'content'}}
通过这种二级路径与内容删除的重复文件才是一种比较合理的方式。
示例代码如下:
# coding:utf-8
import glob
import os.path
data = {} # 定义一个空的字典,暂时将文件名存进来
def clear(path):
result = glob.glob(path) # 将 path 路径传入,赋值给 result
for _data in result: # for 循环判断是否是文件夹
if glob.os.path.isdir(_data): # 若是文件夹,继续将该文件夹的路径传给 clear() 函数继续递归查找
_path = glob.os.path.join(_data, '*')
clear(_path)
else: # 若是文件,则将文件名提取出来
name = glob.os.path.split(_data)[-1]
if 'zip' in name: # 因为目前我们测试的 path 下有 ".zip" 文件,所以这里跳过 '.zip' 压缩文件的读取否则会报错
continue
f = open(_data, 'r') # 判断文件名之前先将内容读取出来,若是不可读模式
content = f.read() # 将读取内容赋值给 content
if name in data: # 判断文件名是否已存在 data 这个临时存储文件名的字典内,如果存在则进行执行删除动作
# 如果不存在,则将读取到的二级路径与内容存储至 data 这个空字典内
sub_name = data[name] # 定义 sub_name 用以获取二级路径
is_delete = False # is_delete 用以记录删除状态;如果没有删除,还需要将二级路径添加至 data
for k, v in sub_name.items(): # 再次循环判断二级路径下的文件;k 为路径,v 为文件内容
print('二级路径为 \"{}\" ,'.format(k), name, '内容为 \'{}\' '.format(v)) # 调试打印输出二级路径下文件的循环
if v == content: # 如果文件名与内容相同,则执行删除动作
print('文件 \"{}\" 被删除...'.format(_data)) # 调试被删除的文件
os.remove(_data) # 删除重复文件后,变更 is_delete 状态为True
is_delete = True
if not is_delete: # 如果没有删除则将 content 读取到的内容赋值给 data[name][_data]
data[name][_data] = content
else:
data[name] = {
_data: content
}
if __name__ == '__main__':
path = glob.os.path.join(glob.os.getcwd(), 'test_file')
clear(path)
print(data)
运行结果如下:
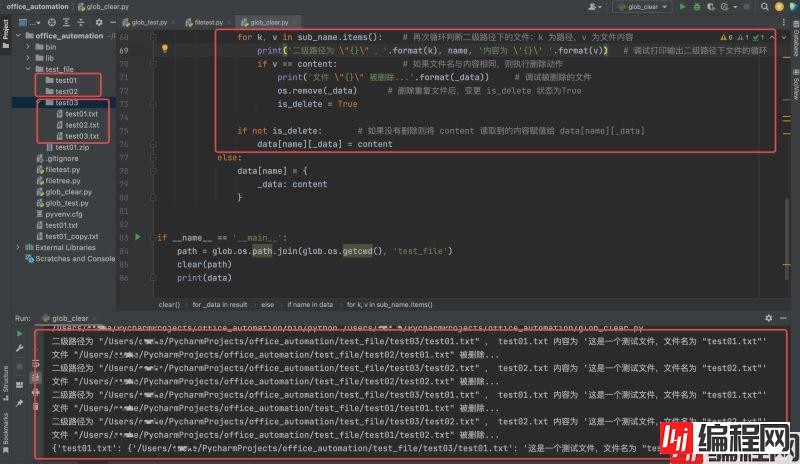
利用 hashlib模块解决读取文件过大问题
现在还有一个问题,从调试的打印输出内容可以看出,因为用以测试的 test_file 路径下的文件都比较小,所以运行起来没有太大的问题;试想一下,如果是一些比较大的文件,经过读取并存入字典的时候,就极大可能会造成内存不足等情况,所以这样直接存储内容的方法是显然不合适的。
其实也是可以解决这个问题的, 就是利用到之前学习的加密模块 ,通过 hashlib 模块将内容加密成md5 的形式, md5只是一个很短的字符串,只要原始内容不变, md5 的值就不会变(该方法也经常被用于运维环境的文件安全检测)。
所以代码中的读取文件内容的 content 就需要变更一下了:
代码示例如下:
# coding:utf-8
import glob
import hashlib
import os.path
data = {} # 定义一个空的字典,暂时将文件名存进来
#data = {'name': {'path/name': 'content', 'path2/name': 'content'}}
def clear(path):
result = glob.glob(path) # 将 path 路径传入,赋值给 result
for _data in result: # for 循环判断是否是文件夹
if glob.os.path.isdir(_data): # 若是文件夹,继续将该文件夹的路径传给 clear() 函数继续递归查找
_path = glob.os.path.join(_data, '*')
clear(_path)
else: # 若是文件,则将文件名提取出来
name = glob.os.path.split(_data)[-1]
if 'zip' in name: # 因为目前我们测试的 path 下有 ".zip" 文件,所以这里跳过 '.zip' 压缩文件的读取否则会报错
continue
f = open(_data, 'r') # 判断文件名之前先将内容读取出来,若是不可读模式
content = f.read() # 将读取内容赋值给 content
hash_content_obj = hashlib.md5(content.encode('utf-8')) # 将读取到的文件内容通过 md5 加密形式进行实例化
hash_content = hash_content_obj.hexdigest() # hash_content_obj 16进制字符串赋值给 hash_content
# 到这里,其实 data 存储的就是 hash_content
if name in data: # 判断文件名是否已存在 data 这个临时存储文件名的字典内,如果存在则进行执行删除动作
# 如果不存在,则将读取到的二级路径与内容存储至 data 这个空字典内
sub_name = data[name] # 定义 sub_name 用以获取二级路径
is_delete = False # is_delete 用以记录删除状态;如果没有删除,还需要将二级路径添加至 data
for k, v in sub_name.items(): # 再次循环判断二级路径下的文件;k 为路径,v 为文件内容
print('二级路径为 \"{}\" ,'.format(k), name, '内容为 \'{}\' '.format(v)) # 调试打印输出二级路径下文件的循环
if v == hash_content: # 如果文件名与内容相同,则执行删除动作
print('文件 \"{}\" 被删除...'.format(_data)) # 调试被删除的文件
os.remove(_data) # 删除重复文件后,变更 is_delete 状态为True
is_delete = True
if not is_delete: # 如果没有删除则将 content 读取到的内容赋值给 data[name][_data]
data[name][_data] = hash_content
else:
data[name] = {
_data: hash_content
}
if __name__ == '__main__':
path = glob.os.path.join(glob.os.getcwd(), 'test_file')
clear(path)
print(data)
运行结果如下:
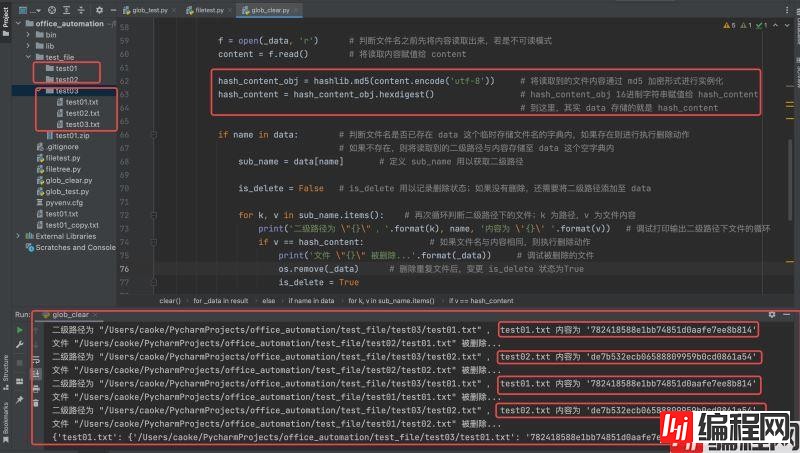
解决读取到不可读的 “zip” 文件报错问题
在上文中,当我们遇到读取到不可读的 “zip” 压缩文件时,利用的是 continue 的方式跳过。 其实这里说的 “zip” 不可读取其实不太严谨,因为可以采用二进制读取的方式来进行读取,但是在上文脚本中,针对读取的内容已经进行了 “encode” 编码,所以用 rb 这种二进制读取的方式还需要继续进行优化。
示例代码如下:
# coding:utf-8
import glob
import hashlib
#data = {'name': {'path/name': 'content', 'path2/name': 'content'}}
import os.path
data = {} # 定义一个空的字典,暂时将文件名存进来
def clear(path):
result = glob.glob(path) # 将 path 路径传入,赋值给 result
for _data in result: # for 循环判断是否是文件夹
if glob.os.path.isdir(_data): # 若是文件夹,继续将该文件夹的路径传给 clear() 函数继续递归查找
_path = glob.os.path.join(_data, '*')
clear(_path)
else: # 若是文件,则将文件名提取出来
name = glob.os.path.split(_data)[-1]
is_byte = False # 添加一个 byte类型读取的开关(如果文件中有中文,还需要设置一下编码格式,并且将打开的文件关闭)
if 'zip' in name: # 因为目前我们测试的 path 下有 ".zip" 文件,所以这里跳过 '.zip' 压缩文件的读取否则会报错
is_byte = True
f = open(_data, 'rb')
else:
f = open(_data, 'r', encoding='utf-8') # 判断文件名之前先将内容读取出来,若是不可读模式
content = f.read() # 将读取内容赋值给 content
f.close()
if is_byte:
hash_content_obj = hashlib.md5(content) # 将读取到的文件内容通过 md5 加密形式进行实例化
else:
hash_content_obj = hashlib.md5(content.encode('utf-8'))
hash_content = hash_content_obj.hexdigest() # hash_content_obj 16进制字符串赋值给 hash_content
# 到这里,其实 data 存储的就是 hash_content
if name in data: # 判断文件名是否已存在 data 这个临时存储文件名的字典内,如果存在则进行执行删除动作
# 如果不存在,则将读取到的二级路径与内容存储至 data 这个空字典内
sub_name = data[name] # 定义 sub_name 用以获取二级路径
is_delete = False # is_delete 用以记录删除状态;如果没有删除,还需要将二级路径添加至 data
for k, v in sub_name.items(): # 再次循环判断二级路径下的文件;k 为路径,v 为文件内容
print('二级路径为 \"{}\" ,'.format(k), name, '内容为 \'{}\' '.format(v)) # 调试打印输出二级路径下文件的循环
if v == hash_content: # 如果文件名与内容相同,则执行删除动作
print('文件 \"{}\" 被删除...'.format(_data)) # 调试被删除的文件
os.remove(_data) # 删除重复文件后,变更 is_delete 状态为True
is_delete = True
if not is_delete: # 如果没有删除则将 content 读取到的内容赋值给 data[name][_data]
data[name][_data] = hash_content
else:
data[name] = {
_data: hash_content
}
if __name__ == '__main__':
path = glob.os.path.join(glob.os.getcwd(), 'test_file')
clear(path)
for k, v in data.items():
for _k, v in v.items():
print('文件路径为 \"{}\" ,'.format(_k), '内容为 \'{}\' '.format(v))
运行结果如下:
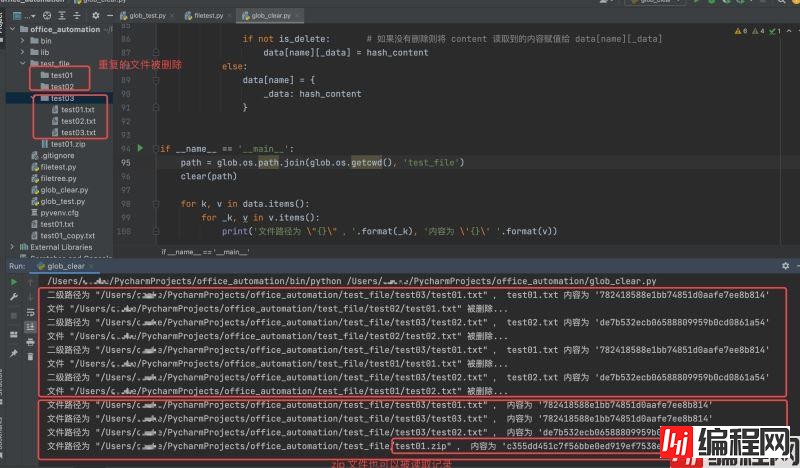
其实也很简单,依然是使用我们最近学习的 shutil 与 glob 模块(参考上一章节的文件查找与递归实现的方式)。
已知条件:
知道文件名需要被修改的指定字符串(即需要被修改的文件名)
实现方法:
通过循环,将指定的目标字符串加入或修改文件名称中含有的字符串
代码示例如下:
# coding:utf-8
import glob
import os.path
import shutil
'''
利用for循环及递归这样的方式,通过 glob 去读取到 test_file 下所有的内容
通过循环按照循环的每一个索引,把每一个文件添加上索引标
'''
def filename_update(path):
result = glob.glob(path)
for index, data in enumerate(result): # for 循环枚举:如果是文件夹则进行递归,如果是文件则加上索引值
if glob.os.path.isdir(data):
_path = glob.os.path.join(data, '*')
filename_update(_path)
else:
path_list = glob.os.path.split(data)
name = path_list[-1]
new_name = '{}_{}'.format(index, name)
new_data = glob.os.path.join(path_list[0], new_name)
shutil.move(data, new_data)
if __name__ == '__main__':
path = glob.os.path.join(glob.os.getcwd(), 'test_file')
filename_update(path)
运行结果如下:
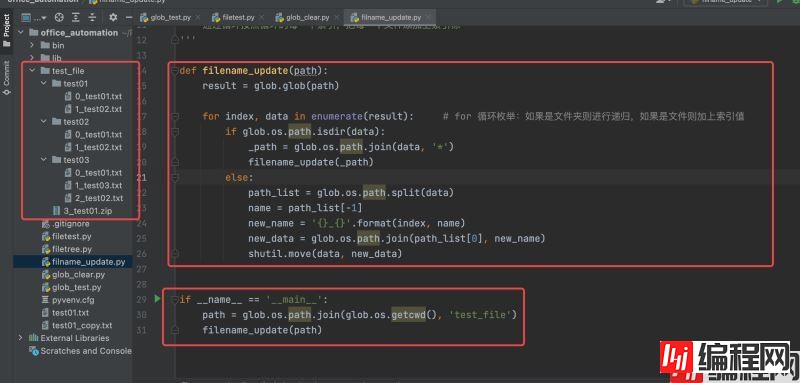
可能这里大家有注意到 "test_file" 文件加下没有 "0_*"开头的索引,其实并不是没有索引,而是我们的脚本中只重命名了文件,文件夹被过滤掉了。
到此这篇关于python自动化办公之清理重复文件详解的文章就介绍到这了,更多相关Python清理重复文件内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python自动化办公之清理重复文件详解
本文链接: https://www.lsjlt.com/news/117887.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0