Python 官方文档:入门教程 => 点击学习
目录1. Series 对象的创建1.1 创建一个空的 Series 对象1.2 通过列表创建一个 Series 对象1.3 通过元组创建一个 Series 对象1.4 通过字典创建
包的引入:
import numpy as np
import pandas as pds = pd.Series()
print(s)
print(type(s))
需要传入一个列表序列
l = [1, 2, 3, 4]
s = pd.Series(l)
print(s)
print('-'*20)
print(type(s))
需要传入一个元组序列
t = (1, 2, 3)
s = pd.Series(t)
print(s)
print('-'*20)
print(type(s))
需要传入一个字典
m = {'zs': 12, 'ls': 23, 'ww': 22}
s = pd.Series(m)
print(s)
print('-'*20)
print(type(s))
需要传入一个 ndarray
ndarr = np.array([1, 2, 3])
s = pd.Series(ndarr)
print(s)
print('-'*20)
print(type(s))
index:用于设置 Series 对象的索引
age = [12, 23, 22, 34]
name = ['zs', 'ls', 'ww', 'zl']
s = pd.Series(age, index=name)
print(s)
print('-'*20)
print(type(s))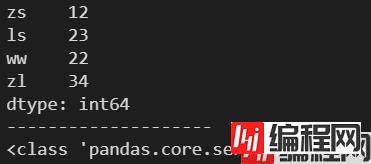
num = 999
s = pd.Series(num, index=[1, 2, 3, 4])
print(s)
print('-'*20)
print(type(s))
ndarr = np.arange(0, 10, 2)
s = pd.Series(5, index=ndarr)
print(s)
print('-'*20)
print(type(s))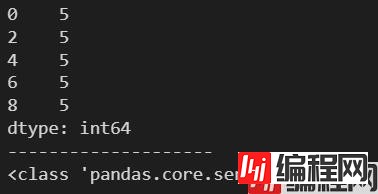
l = [11, 22, 33, 44]
s = pd.Series(l)
print(s)
print('-'*20)
ndarr = s.values
print(ndarr)
print('-'*20)
print(type(ndarr))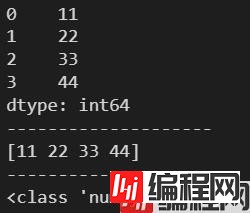
d = {'zs': 12, 'ls': 23, 'ww': 35}
s = pd.Series(d)
print(s)
print('-'*20)
idx = s.index
print(idx)
print('-'*20)
print(type(idx))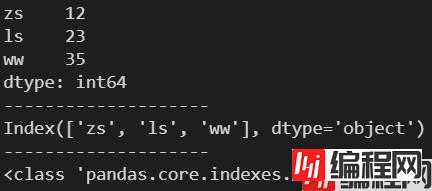
d = {'zs': 12, 'ls': 23, 'ww': 35}
s = pd.Series(d)
print(s)
print('-'*20)
print(s.dtype)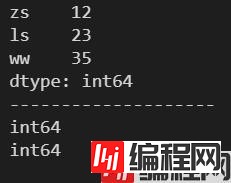
d = {'zs': 12, 'ls': 23, 'ww': 35}
s = pd.Series(d)
print(s)
print('-'*20)
print(s.size)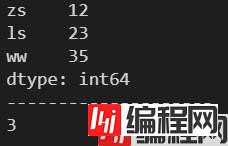
d = {'zs': 12, 'ls': 23, 'ww': 35}
s1 = pd.Series(d)
print(s1)
print('-'*20)
print(s1.ndim)
l = [[1, 1], [2, 2], [3, 3]]
s2 = pd.Series(l)
print(s2)
print('-'*20)
print(s2.ndim)
d = {'zs': 12, 'ls': 23, 'ww': 35}
s1 = pd.Series(d)
print(s1)
print('-'*20)
print(s1.shape)
print()
l = [[1, 1], [2, 2], [3, 3]]
s2 = pd.Series(l)
print(s2)
print('-'*20)
print(s2.shape)
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
print(s.mean())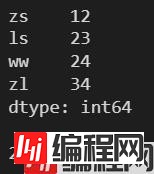
l1 = [12, 23, 24, 34]
s1 = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s1)
print()
print(s1.max())
print(s1.min())
print()
l2 = ['ac', 'ca', 'cd', 'ab']
s2 = pd.Series(l2)
print(s2)
print()
print(s2.max())
print(s2.min())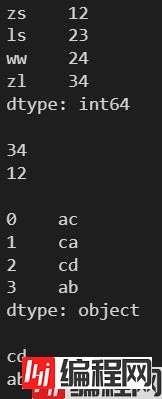
l1 = [12, 23, 24, 34]
s1 = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s1)
print()
# argmax() -- 最大值的数字索引
# idxmax() -- 最大值的标签索引
# 两个都不支持字符串类型的数据
print(s1.max(), s1.argmax(), s1.idxmax())
print(s1.min(), s1.argmin(), s1.idxmin())
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
print(s.median())
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
print(s.value_counts())
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
print(s.mode())
print()
l = [12, 23, 24, 34, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl', 'zq'])
print(s)
print()
print(s.mode())
四分位数:把数值从小到大排列并分成四等分,处于三个分割点位置的数值就是四分位数。
需要传入一个列表,列表中的元素为要获取的数的对应位置
l = [1, 1, 2, 2, 3, 3, 4, 4]
s = pd.Series(l)
print(s)
print()
print(s.quantile([0, .25, .50, .75, 1]))
总体标准差是反映研究总体内个体之间差异程度的一种统计指标。
总体标准差计算公式:
由于总体标准差计算出来会偏小,所以采用 ( n − d d o f ) (n-ddof) (n−ddof)的方式适当扩大标准差,即样本标准差。
样本标准差计算公式:
l = [1, 1, 2, 2, 3, 3, 4, 4]
s = pd.Series(l)
print(s)
print()
# 总体标准差
print(s.std())
print()
print(s.std(ddof=1))
print()
# 样本标准差
print(s.std(ddof=2))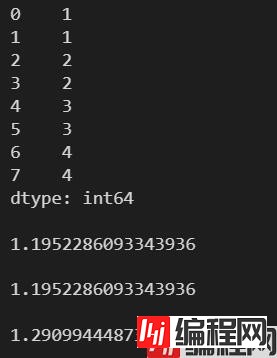
l = [1, 1, 2, 2, 3, 3, 4, 4]
s = pd.Series(l)
print(s)
print()
print(s.describe())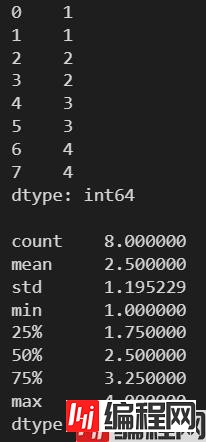
ascending:True为升序(默认),False为降序 3.10.1 升序
l = [4, 2, 1, 3]
s = pd.Series(l)
print(s)
print()
s = s.sort_values()
print(s)
l = [4, 2, 1, 3]
s = pd.Series(l)
print(s)
print()
s = s.sort_values(ascending=False)
print(s)
ascending:True为升序(默认),False为降序
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
s = s.sort_index()
print(s)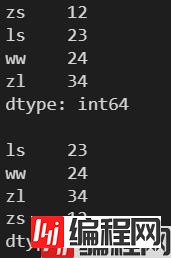
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
s = s.sort_index()
print(s)
需要传入一个函数参数
# x 为当前遍历到的元素
def func(x):
if (x%2==0): return x+1
else: return x
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
# 调用 apply 方法,会将 Series 中的每个元素带入 func 函数中进行处理
s = s.apply(func)
print(s)
对象的前 x 个元素 需要传入一个数 x ,表示查看前 x 个元素,默认为前5个
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
# head(x) 查看 Series 对象的前 x 个元素
print(s.head(2))
需要传入一个数 x ,表示查看后 x 个元素,默认为后5个
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
# tail(x) 查看 Series 对象的后 x 个元素
print(s.tail(2))
l = [12, 23, 24, 34]
s = pd.Series(l)
print(s)
print()
print(s[0])
print()
print(s[1:-2])
print()
print(s[::2])
print()
print(s[::-1])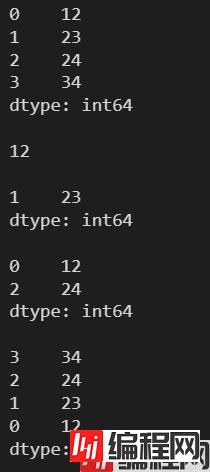
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
print(s[0])
print()
print(s[1:-2])
print()
print(s[::2])
print()
print(s[::-1])
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
print(s['zs'])
print()
# 自定义标签索引进行切片包含开始与结束位置
print(s['ls':'zl'])
print()
print(s['zs':'zl':2])
print()
# 注意切边范围的方向与步长的方向
print(s['zl':'zs':-1])
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
idx = (s%2==0)
print(idx)
print()
# 索引掩码(也是一个数组)
# 索引掩码个数与原数组的个数一致,数组每个元素都与索引掩码中的元素一一对应
# 数组每个元素都对应着索引掩码中的一个True或False
# 只有索引掩码中为True所对应元素组中的元素才会被选中
print(s[idx])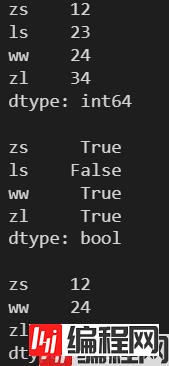
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
# 选出指定索引对应的元素
print(s[['zs', 'ww']])
print()
print(s[[1, 2]])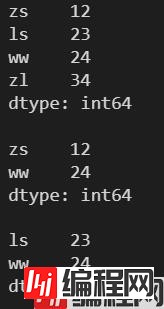
传入要删除元素的标签索引
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
s.pop('ww')
print(s)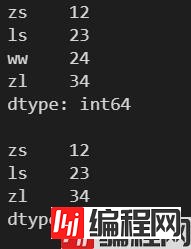
传入要删除元素的标签索引
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
# drop() 会返回一个删除元素后的新数组,不会对原数组进行修改
s = s.drop('zs')
print(s)
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
s['zs'] = 22
print(s)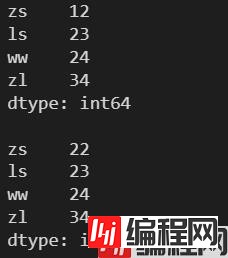
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
s[1] = 22
print(s)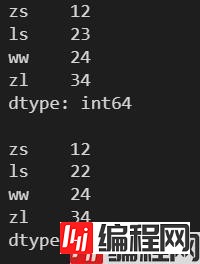
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
s['ll'] = 22
print(s)
需要传入一个要添加到原 Series 对象的 Series 对象
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
# 可以添加已经存在的索引及其值
s2 = pd.Series([11, 13], index=['zs', 'wd'])
# append() 不会对原数组进行修改
s = s.append(s2)
print(s)
print()
print(s['zs'])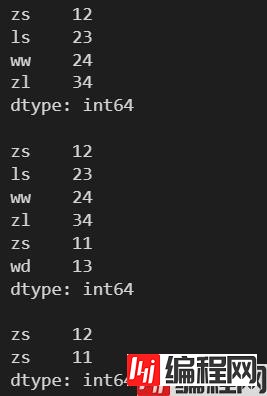
到此这篇关于Pandas中Series的属性,方法,常用操作使用案例的文章就介绍到这了,更多相关Pandas中Series属性内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Pandas中Series的属性,方法,常用操作使用案例
本文链接: https://www.lsjlt.com/news/119660.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作






0