Python 官方文档:入门教程 => 点击学习
东方财富网地址如下: Http://quote.eastmoney.com/center/gridlist.html#hs_a_board 我们通过点击该网站的下一页发现,网页内容
东方财富网地址如下:
Http://quote.eastmoney.com/center/gridlist.html#hs_a_board
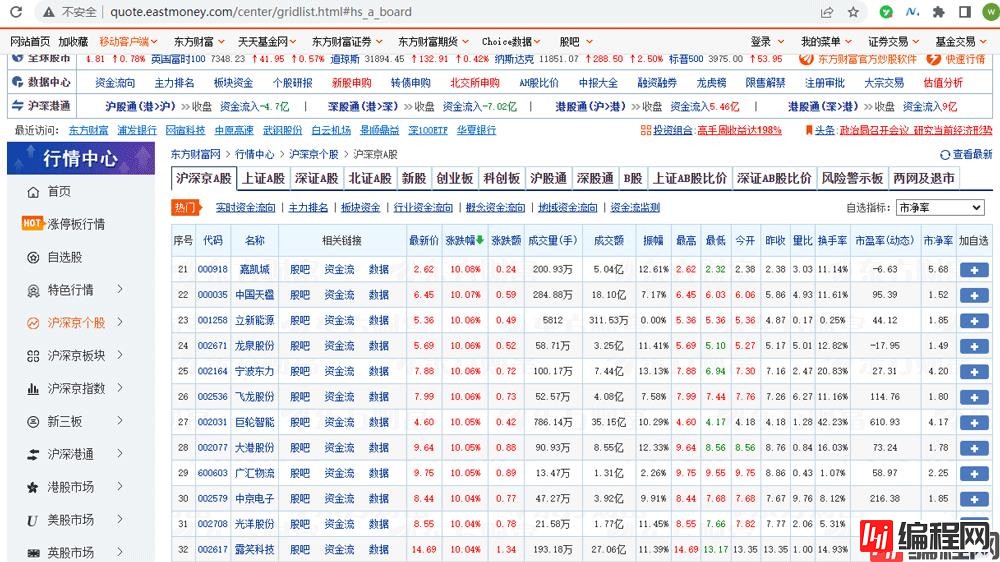
我们通过点击该网站的下一页发现,网页内容有变化,但是网站的 URL 却不变,也就是说这里使用了 ajax 技术,动态从服务器拉取数据,这种方式的好处是可以在不重新加载整幅网页的情况下更新部分数据,减轻网络负荷,加快页面加载速度。
我们通过 F12 来查看网络请求情况,可以很容易的发现,网页上的数据都是通过如下地址请求的
http://38.push2.eastmoney.com/api/Qt/clist/get?cb=Jquery112409036039385296142_1658838397275&pn=3&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|WEB&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1658838404848
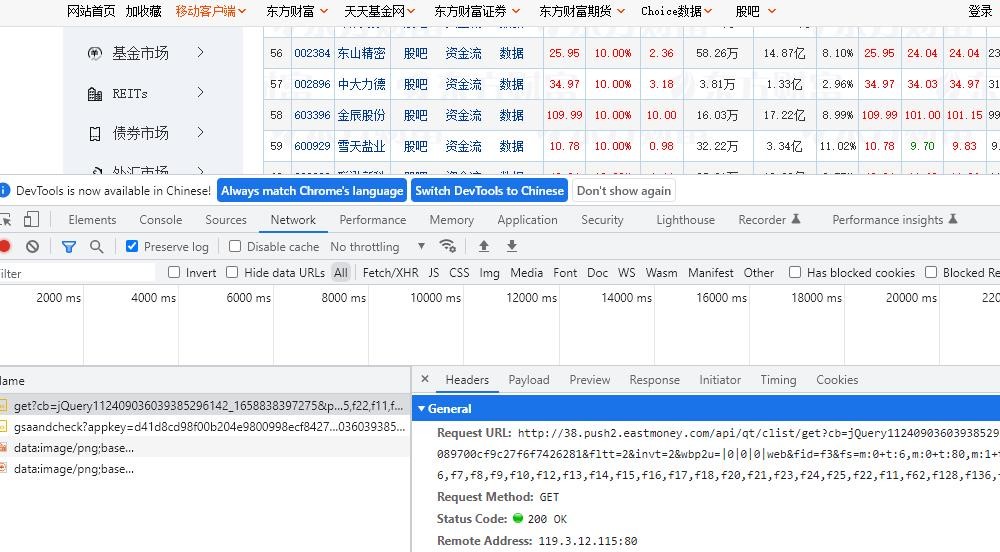
接下来我们多请求几次,来观察该地址的变化情况,发现其中的pn参数代表这页数,于是,我们可以通过修改&pn=后面的数字来访问不同页面对应的数据
import requests
JSON_url = "http://48.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112402508937289440778_1658838703304&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1658838703305"
res = requests.get(json_url)数据处理 接下来我们观察返回的数据,可以看出数据并不是标准的 json 数据
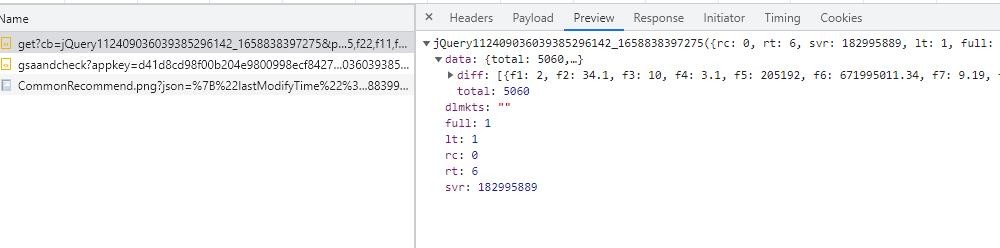
于是我们先进行 json 化:
result = res.text.split("jQuery112402508937289440778_1658838703304")[1].split("(")[1].split(");")[0]
result_json = json.loads(result)
result_jsonOutput:
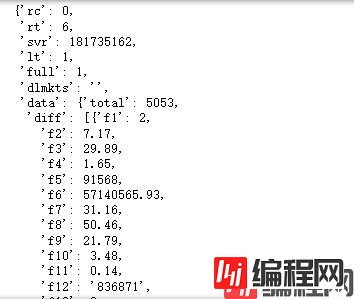
返回各参数对应含义:
先准备一个存储函数
def save_data(data, date):
if not os.path.exists(r'stock_data_%s.csv' % date):
with open("stock_data_%s.csv" % date, "a+", encoding='utf-8') as f:
f.write("股票代码,股票名称,最新价,涨跌幅,涨跌额,成交量(手),成交额,振幅,换手率,市盈率,量比,最高,最低,今开,昨收,市净率\n")
for i in data:
Code = i["f12"]
Name = i["f14"]
Close = i['f2']
ChangePercent = i["f3"]
Change = i['f4']
Volume = i['f5']
Amount = i['f6']
Amplitude = i['f7']
TurnoverRate = i['f8']
PERation = i['f9']
VolumeRate = i['f10']
Hign = i['f15']
Low = i['f16']
Open = i['f17']
PreviousClose = i['f18']
PB = i['f22']
row = '{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{}'.fORMat(
Code,Name,Close,ChangePercent,Change,Volume,Amount,Amplitude,
TurnoverRate,PERation,VolumeRate,Hign,Low,Open,PreviousClose,PB)
f.write(row)
f.write('\n')
else:
...然后再把前面处理好的 json 数据传入:
stock_data = result_json['data']['diff']
save_data(stock_data, '2022-07-28')这样我们就得到了第一页的股票数据:

最后我们只需要循环抓取所有网页即可:
for i in range(1, 5):
print("抓取网页%s" % str(i))
url = "http://48.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112402508937289440778_1658838703304&pn=%s&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1658838703305" % str(i)
res = requests.get(json_url)
result = res.text.split("jQuery112402508937289440778_1658838703304")[1].split("(")[1].split(");")[0]
result_json = json.loads(result)
stock_data = result_json['data']['diff']
save_data(stock_data, '2022-07-28')这样我们就完成了整个股票数据的抓取,
到此这篇关于利用python 爬取股票实时数据详情的文章就介绍到这了,更多相关 Python 爬取股票数据内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: 利用Python 爬取股票实时数据详情
本文链接: https://www.lsjlt.com/news/119915.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0