Python 官方文档:入门教程 => 点击学习
目录概述一、概念1、原理二、静态类部类单例模式生产雪花ID代码1、代码2、测试结果3、为什么说41位时间戳最长只能有69年概述 在生成表主键ID时,我们可以考虑主键自增 或者 UUI
在生成表主键ID时,我们可以考虑主键自增 或者 UUID,但它们都有很明显的缺点
主键自增:1、自增ID容易被爬虫遍历数据。2、分表分库会有ID冲突。
UUID: 1、太长,并且有索引碎片,索引多占用空间的问题 2、无序。
雪花算法就很适合在分布式场景下生成唯一ID,它既可以保证唯一又可以排序。为了提高生产雪花ID的效率,
在这里面数据的运算都采用的是位运算
SnowFlake算法生成ID的结果是一个64bit大小的整数,它的结构如下图:
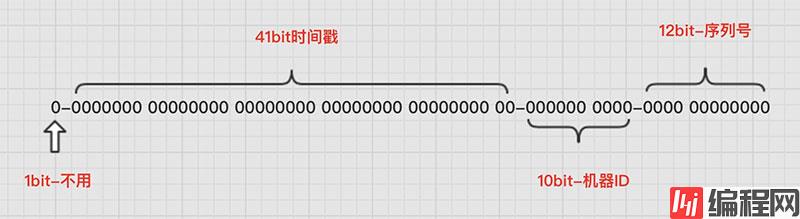
算法描述:
1bit 因为二进制中最高位是符号位,1表示负数,0表示正数。生成的ID都是正整数,所以最高位固定为0。
41bit-时间戳 精确到毫秒级,41位的长度可以使用69年。时间位还有一个很重要的作用是可以根据时间进行排序。
10bit-工作机器id 10位的机器标识,10位的长度最多支持部署1024个节点。
12bit-序列号 序列号即一系列的自增id,可以支持同一节点同一毫秒生成多个ID序号。
12位(bit)可以表示的最大正整数是
说明 由于在Java中64bit的整数是long类型,所以在Java中SnowFlake算法生成的id就是long来存储的。
下面生成雪花ID的代码可以用于线上分布式项目中来生成分布式主键ID,因为设计采用的静态内部类的单例模式,通过加synchronized锁来保证在
同一个服务器线程安全。至于不同服务器其实是不相关的,因为它们的机器码是不一致的,所以就算同一时刻两台服务器都产生了雪花ID,那也不会一样的。
public class SnowIdUtils {
private static class SnowFlake {
private static final SnowIdUtils.SnowFlake SNOW_FLAKE = new SnowIdUtils.SnowFlake();
private final long START_TIMESTAMP = 1557489395327L;
private final long SEQUENCE_BIT = 12;
private final long MacHINE_BIT = 10;
private final long TIMESTAMP_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final long MAX_SEQUENCE = ~(-1L << SEQUENCE_BIT);
private final long MAX_MACHINE_ID = ~(-1L << MACHINE_BIT);
private long machineIdPart;
private long sequence = 0L;
private long lastStamp = -1L;
private SnowFlake() {
//模拟这里获得本机机器编码
long localIp = 4321;
//localIp & MAX_MACHINE_ID最大不会超过1023,在左位移12位
machineIdPart = (localIp & MAX_MACHINE_ID) << SEQUENCE_BIT;
}
public synchronized long nextId() {
long currentStamp = timeGen();
//避免机器时钟回拨
while (currentStamp < lastStamp) {
// //服务器时钟被调整了,ID生成器停止服务.
throw new RuntimeException(String.fORMat("时钟已经回拨. Refusing to generate id for %d milliseconds", lastStamp - currentStamp));
}
if (currentStamp == lastStamp) {
// 每次+1
sequence = (sequence + 1) & MAX_SEQUENCE;
// 毫秒内序列溢出
if (sequence == 0) {
// 阻塞到下一个毫秒,获得新的时间戳
currentStamp = getNextMill();
}
} else {
//不同毫秒内,序列号置0
sequence = 0L;
}
lastStamp = currentStamp;
//时间戳部分+机器标识部分+序列号部分
return (currentStamp - START_TIMESTAMP) << TIMESTAMP_LEFT | machineIdPart | sequence;
}
private long getNextMill() {
long mill = timeGen();
//
while (mill <= lastStamp) {
mill = timeGen();
}
return mill;
}
protected long timeGen() {
return System.currentTimeMillis();
}
}
public static long uniqueLong() {
return SnowIdUtils.SnowFlake.SNOW_FLAKE.nextId();
}
public static String uniqueLongHex() {
return String.format("%016x", uniqueLong());
}
public static void main(String[] args) throws InterruptedException {
//计时开始时间
long start = System.currentTimeMillis();
//让100个线程同时进行
final CountDownLatch latch = new CountDownLatch(100);
//判断生成的20万条记录是否有重复记录
final Map<Long, Integer> map = new ConcurrentHashMap();
for (int i = 0; i < 100; i++) {
//创建100个线程
new Thread(() -> {
for (int s = 0; s < 2000; s++) {
long snowID = SnowIdUtils.uniqueLong();
log.info("生成雪花ID={}",snowID);
Integer put = map.put(snowID, 1);
if (put != null) {
throw new RuntimeException("主键重复");
}
}
latch.countDown();
}).start();
}
//让上面100个线程执行结束后,在走下面输出信息
latch.await();
log.info("生成20万条雪花ID总用时={}", System.currentTimeMillis() - start);
}
}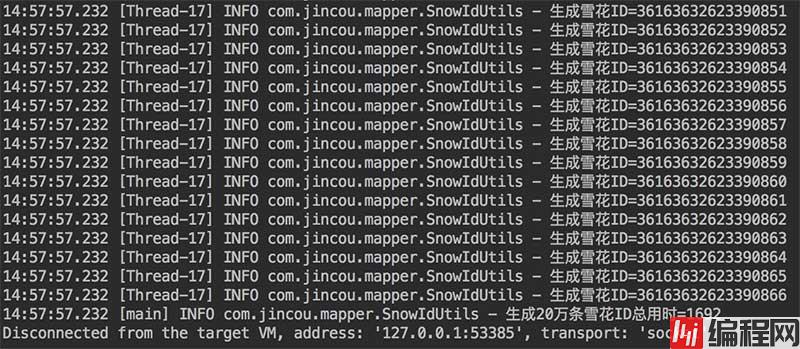
从图中我们可以得出
1、在100个线程并发下,生成20万条雪花ID的时间大概在1.6秒左右,所有所性能还是蛮ok的。
2、生成20万条雪花ID并没有一条相同的ID,因为有一条就会抛出异常了。
我们思考41的二进制,最大值也就41位都是1,也就是也就是说41位可以表示

我们可以通过代码泡一下就知道了。
public static void main(String[] args) {
//41位二进制最小值
String minTimeStampStr = "00000000000000000000000000000000000000000";
//41位二进制最大值
String maxTimeStampStr = "11111111111111111111111111111111111111111";
//转10进制
long minTimeStamp = new BigInteger(minTimeStampStr, 2).longValue();
long maxTimeStamp = new BigInteger(maxTimeStampStr, 2).longValue();
//一年总共多少毫秒
long oneYearMills = 1L * 1000 * 60 * 60 * 24 * 365;
//算出最大可以多少年
System.out.println((maxTimeStamp - minTimeStamp) / oneYearMills);
}运行结果

所以说雪花算法生成的ID,只能保证69年内不会重复,如果超过69年的话,那就考虑换个服务器部署吧,并且要保证该服务器的ID和之前都没有重复过。
以上就是java算法之静态内部类实现雪花算法的详细内容,更多关于java算法的资料请关注编程网其它相关文章!
--结束END--
本文标题: java算法之静态内部类实现雪花算法
本文链接: https://www.lsjlt.com/news/125623.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0