Python 官方文档:入门教程 => 点击学习
目录前言CSV 和文本文件1 参数解析1.1 基础1.2 列、索引、名称1.3 常规解析配置1.4 NA 和缺失数据处理1.5 日期时间处理1.6 迭代1.7 引用、压缩和文件格式1
前面我们介绍了 pandas 的基础语法操作,下面我们开始介绍 pandas 的数据读写操作。
pandas 的 io api 是一组顶层的 reader 函数,比如 pandas.read_csv(),会返回一个 pandas 对象。
而相应的 writer 函数是对象方法,如 DataFrame.to_csv()。
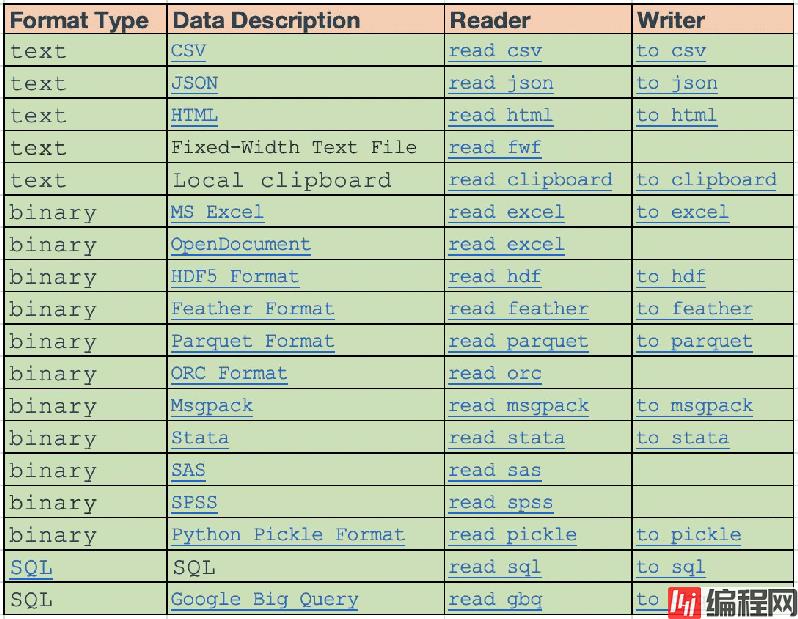
下面列出了所有的 reader 和 writer 函数
注意:后面会用到 StringIO,请确保导入
读取文本文件的主要函数是 read_csv()
read_csv() 接受以下常用参数:
filepath_or_buffer: 变量
可以是文件路径、文件 URL 或任何带有 read() 函数的对象
sep: str,默认 ,,对于 read_table 是 \t
delimiter: str, 默认为 None
sep 的替代参数,功能一致
header: int 或 list, 默认为 'infer'
用作列名的行号,默认行为是对列名进行推断:
names: array-like, 默认为 None
需要设置的列名列表,如果文件中不包含标题行,则应显式传递 header=None,且此列表中不允许有重复值。
index_col: int, str, sequence of int/str, False, 默认为 None
usecols: 列表或函数, 默认为 None
In [1]: import pandas as pd
In [2]: from io import StringIO
In [3]: data = "col1,col2,col3\na,b,1\na,b,2\nc,d,3"
In [4]: pd.read_csv(StringIO(data))
Out[4]:
col1 col2 col3
0 a b 1
1 a b 2
2 c d 3
In [5]: pd.read_csv(StringIO(data), usecols=lambda x: x.upper() in ["COL1", "COL3"])
Out[5]:
col1 col3
0 a 1
1 a 2
2 c 3
使用此参数可以大大加快解析时间并降低内存使用
squeeze: boolean, 默认为 False
prefix: str, 默认为 None
mangle_dupe_cols: boolean, 默认为 True
dtype: 类型名或类型字典(column -> type), 默认为 None
数据或列的数据类型。例如。
{'a':np.float64,'b':np.int32}
engine: {'c', 'python'}
converters: dict, 默认为 None
true_values: list, 默认为 None
false_values: list, 默认为 None
skipinitialspace: boolean, 默认为 False
skiprows: 整数或整数列表, 默认为 None
In [6]: data = "col1,col2,col3\na,b,1\na,b,2\nc,d,3"
In [7]: pd.read_csv(StringIO(data))
Out[7]:
col1 col2 col3
0 a b 1
1 a b 2
2 c d 3
In [8]: pd.read_csv(StringIO(data), skiprows=lambda x: x % 2 != 0)
Out[8]:
col1 col2 col3
0 a b 2
skipfooter: int, 默认为 0
nrows: int, 默认为 None
memory_map: boolean, 默认为 False
na_values: Scalar, str, list-like, dict, 默认为 None
keep_default_na: boolean, 默认为 True
解析数据时是否包含默认的 NaN 值。根据是否传入 na_values,其行为如下
keep_default_na=True, 且指定了 na_values, na_values 将会与默认的 NaN 一起被解析
keep_default_na=True, 且未指定 na_values, 只解析默认的 NaN
keep_default_na=False, 且指定了 na_values, 只解析 na_values 指定的 NaN
keep_default_na=False, 且未指定 na_values, 字符串不会被解析为 NaN
注意:如果 na_filter=False,那么 keep_default_na 和 na_values 参数将被忽略
na_filter: boolean, 默认为 True
skip_blank_lines: boolean, 默认为 True
parse_dates: 布尔值、列表或嵌套列表、字典, 默认为 False.
infer_datetime_fORMat: 布尔值, 默认为 False
date_parser: 函数, 默认为 None
用于将字符串序列转换为日期时间实例数组的函数。默认使用 dateutil.parser.parser 进行转换,pandas 将尝试以三种不同的方式调用 date_parser
dayfirst: 布尔值, 默认为 False
cache_dates: 布尔值, 默认为 True
iterator: boolean, 默认为 False
compression: {'infer', 'gzip', 'bz2', 'zip', 'xz', None, dict}, 默认为 'infer'
compression={'method': 'gzip', 'compresslevel': 1, 'mtime': 1}
thousandsstr, 默认为 None
decimal: str, 默认为 '.'
float_precision: string, 默认为 None
quotechar: str (长度为 1)
comment: str, 默认为 None
encoding: str, 默认为 None
设置编码格式
error_bad_linesboolean, 默认为 True
warn_bad_linesboolean, 默认为 True
如果 error_bad_lines=False 且 warn_bad_lines=True,每个坏行都会输出一个警告
您可以指示整个 DataFrame 或各列的数据类型
In [9]: import numpy as np
In [10]: data = "a,b,c,d\n1,2,3,4\n5,6,7,8\n9,10,11"
In [11]: print(data)
a,b,c,d
1,2,3,4
5,6,7,8
9,10,11
In [12]: df = pd.read_csv(StringIO(data), dtype=object)
In [13]: df
Out[13]:
a b c d
0 1 2 3 4
1 5 6 7 8
2 9 10 11 NaN
In [14]: df["a"][0]
Out[14]: '1'
In [15]: df = pd.read_csv(StringIO(data), dtype={"b": object, "c": np.float64, "d": "Int64"})
In [16]: df.dtypes
Out[16]:
a int64
b object
c float64
d Int64
dtype: object
你可以使用 read_csv() 的 converters 参数,统一某列的数据类型
In [17]: data = "col_1\n1\n2\n'A'\n4.22"
In [18]: df = pd.read_csv(StringIO(data), converters={"col_1": str})
In [19]: df
Out[19]:
col_1
0 1
1 2
2 'A'
3 4.22
In [20]: df["col_1"].apply(type).value_counts()
Out[20]:
<class 'str'> 4
Name: col_1, dtype: int64
或者,您可以在读取数据后使用 to_numeric() 函数强制转换类型
In [21]: df2 = pd.read_csv(StringIO(data))
In [22]: df2["col_1"] = pd.to_numeric(df2["col_1"], errors="coerce")
In [23]: df2
Out[23]:
col_1
0 1.00
1 2.00
2 NaN
3 4.22
In [24]: df2["col_1"].apply(type).value_counts()
Out[24]:
<class 'float'> 4
Name: col_1, dtype: int64
它将所有有效的数值转换为浮点数,而将无效的解析为 NaN
最后,如何处理包含混合类型的列取决于你的具体需要。在上面的例子中,如果您只想要将异常的数据转换为 NaN,那么 to_numeric() 可能是您的最佳选择。
然而,如果您想要强制转换所有数据,而无论类型如何,那么使用 read_csv() 的 converters 参数会更好
注意
在某些情况下,读取包含混合类型列的异常数据将导致数据集不一致。
如果您依赖 pandas 来推断列的类型,解析引擎将继续推断数据块的类型,而不是一次推断整个数据集。
In [25]: col_1 = list(range(500000)) + ["a", "b"] + list(range(500000))
In [26]: df = pd.DataFrame({"col_1": col_1})
In [27]: df.to_csv("foo.csv")
In [28]: mixed_df = pd.read_csv("foo.csv")
In [29]: mixed_df["col_1"].apply(type).value_counts()
Out[29]:
<class 'int'> 737858
<class 'str'> 262144
Name: col_1, dtype: int64
In [30]: mixed_df["col_1"].dtype
Out[30]: dtype('O')
这就导致 mixed_df 对于列的某些块包含 int 类型,而对于其他块则包含 str,这是由于读取的数据是混合类型。
以上就是Python pandas数据读写操作IO工具CSV的详细内容,更多关于Python pandas数据读写的资料请关注编程网其它相关文章!
--结束END--
本文标题: Python数据处理pandas读写操作IO工具CSV解析
本文链接: https://www.lsjlt.com/news/126035.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0