Python 官方文档:入门教程 => 点击学习
目录一、解析网站1.1 获取音频地址1.2 解析专栏网页1.3 整理亿下思路二、编写爬取代码一、解析网站 1.1 获取音频地址 在喜马拉雅网站上,随便点开一个音频,打开“开发者工具”
在喜马拉雅网站上,随便点开一个音频,打开“开发者工具”,再点击播放按钮,可以看到出现了多个请求:
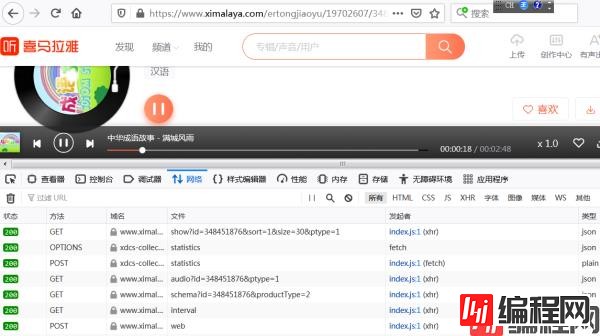
经过排查,发现可疑url:

查看它的响应信息,发现音频地址就在里面:
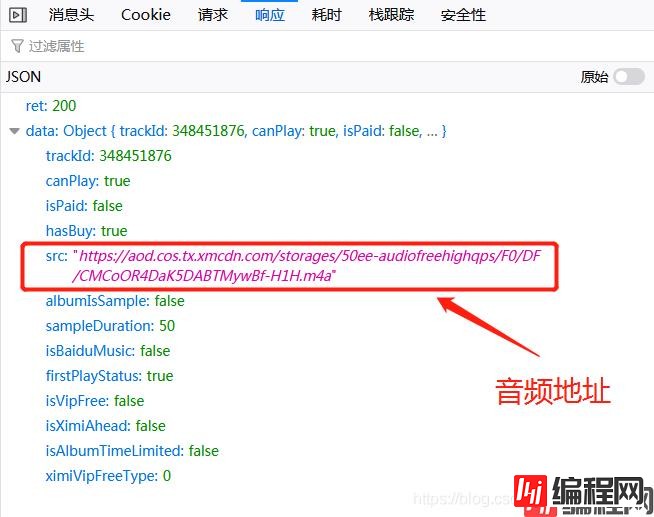
接下来,解析这个返回音频地址的url:
发现url中的id参数就决定了返回的音频地址,而id参数是音频的id号。
我们已经知道了获取音频url的网址,接下来要获取一个专栏内的音频id和名称,打开一个专栏,发现:
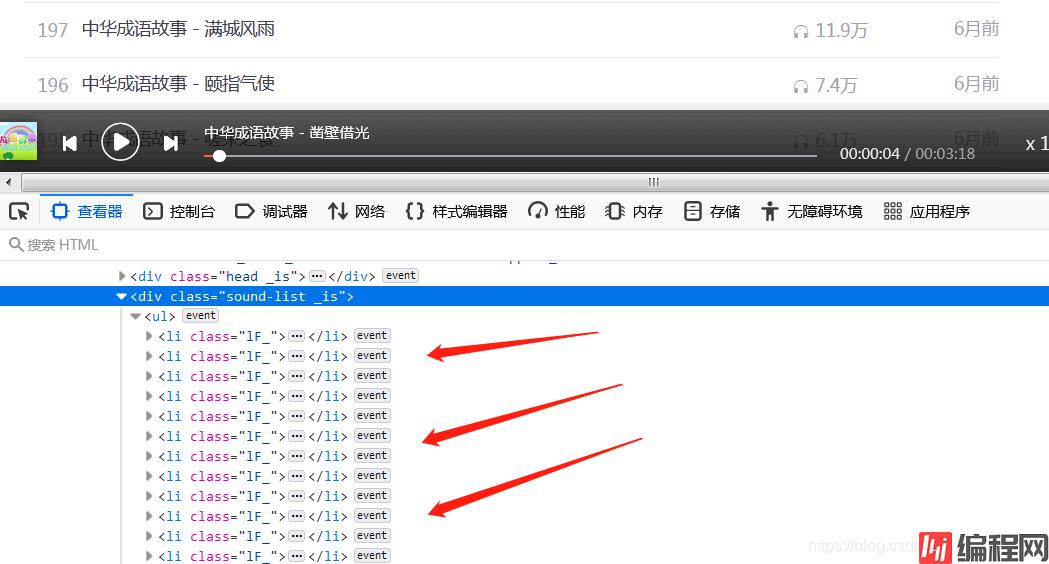
所有的音频存放在class为1F_的li标签中,再来解析li标签:
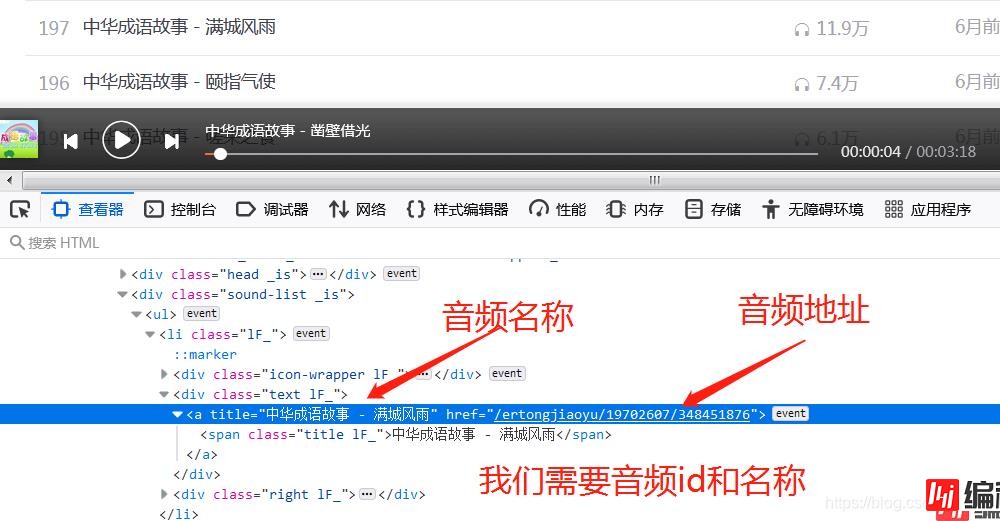
在li标签中的第一个a标签存储着我们所有需要的数据,妙~啊!
思路:
1.获取专栏内的li标签
2.获取li标签里的第一个a标签
3.读取a标签的title和href属性
4.将href解析成音频id
5.将id带入url请求音频源地址
6.提取音频源地址
7.请求音频源地址
8.保存音频(文件名为a的title属性)
思路整理完了,开始编写代码。
代码奉上——
import requests
from fake_useragent import UserAgent as ua
from bs4 import BeautifulSoup as bs
# 专栏地址
music_list_url = 'Https://www.ximalaya.com/ertongjiaoyu/19702607/'
# 获取音频地址的url
get_link_url = "https://www.ximalaya.com/revision/play/v1/audio"
# UA伪装
headers = {
"User-Agent": ua().random
}
# 参数
params = {
"id": None, # id先设为None
"ptype": "1",
}
# 获取专栏html源码
music_list_r = requests.get(music_list_url, headers=headers)
# 解析 获取所有li标签
soup = bs(music_list_r.text, "lxml")
li = soup.find_all("li", {"class": "lF_"})
# for循序遍历处理
for i in li:
a = i.find("a") # 找到a标签
# 获取href属性
# split("/")将字符串以"/"作为分隔符 从右往左数第一项是id号
music_id = a.get("href").split("/")[-1]
# 获取title属性 和“.m4a”拼接成文件名
music_name = a.get("title") + ".m4a"
# 修改请求参数id
params['id'] = music_id
# 获得音频源地址
r = requests.get(get_link_url, headers=headers, params=params)
link = r.JSON()['data']['src']
# 获取音频文件并保存
music_file = requests.get(link).content
with open(music_name, "wb") as f:
f.write(music_file)
print("下载完毕!")
运行代码,等待亿会(真的要等亿会),可以看到当前目录下已经出现了音频文件,如图:
到此这篇关于python爬虫之批量下载喜马拉雅音频的文章就介绍到这了,更多相关python下载喜马拉雅音频内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python爬虫之批量下载喜马拉雅音频
本文链接: https://www.lsjlt.com/news/126251.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0