目录背景 方案一:老数据备份 方案二:分表 方案三:迁移至tidb 重点说下同步老数据遇到的坑 最终同步脚本方案 总结背景 由于历史业务数据采用Mysql来存储的,其中有一张操作记
由于历史业务数据采用Mysql来存储的,其中有一张操作记录表video_log,每当用户创建、更新或者审核人员审核的时候,对应的video_log就会加一条日志,这个log表只有insert,可想而知,1个video对应多条log,一天10w video,平均统计一个video对应5条log,那么一天50w的log, 一个月50 * 30 = 1500w条记录, 一年就是1500 * 12 = 1.8亿。目前线上已经有2亿多的数据了,由于log本身不面向C端,用于查询问题的,所以可以忍受一点的延迟。 但是随着时间的积累,必然会越来越慢,影响效率,于是提出改造。

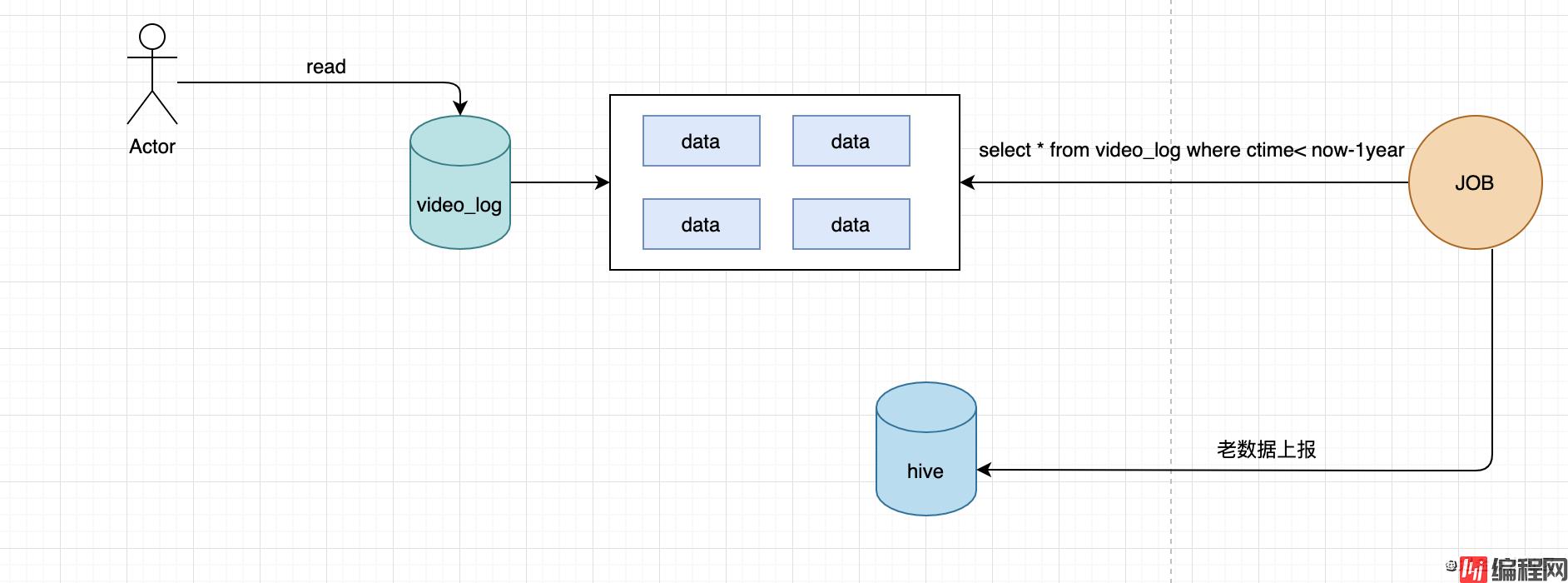
由于log本身不是最关键的数据,但是也要求实时性高(用于实时查询问题),所以一开始的想法是核心的基础存储还是保持不变,较老的数据迁移出去,毕竟突然去查询一年前的操作记录的概率很小,如果突然要查,可以走离线。设计的话,我们只需要一个定时脚本,每天在凌晨4点左右(业务低峰期)抽数据。抽出的数据可以上报到一些离线存储(一般公司都有基于Hive的数仓之类的),这样就可以保持线上的video_log的数据不会一直增长。
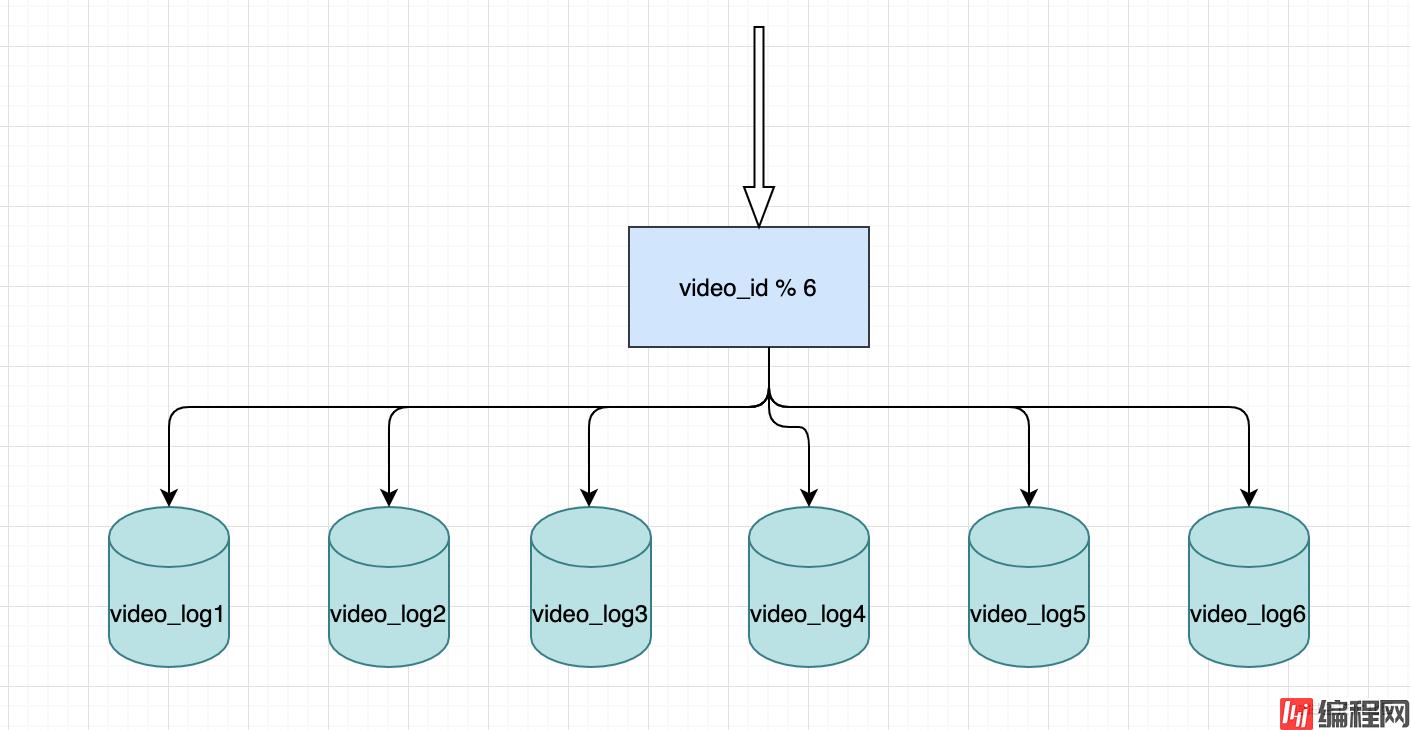
分表也是一种解决方案,相对方案一的好处就是,所有的数据都支持实时查,缺点是代码要改造了。
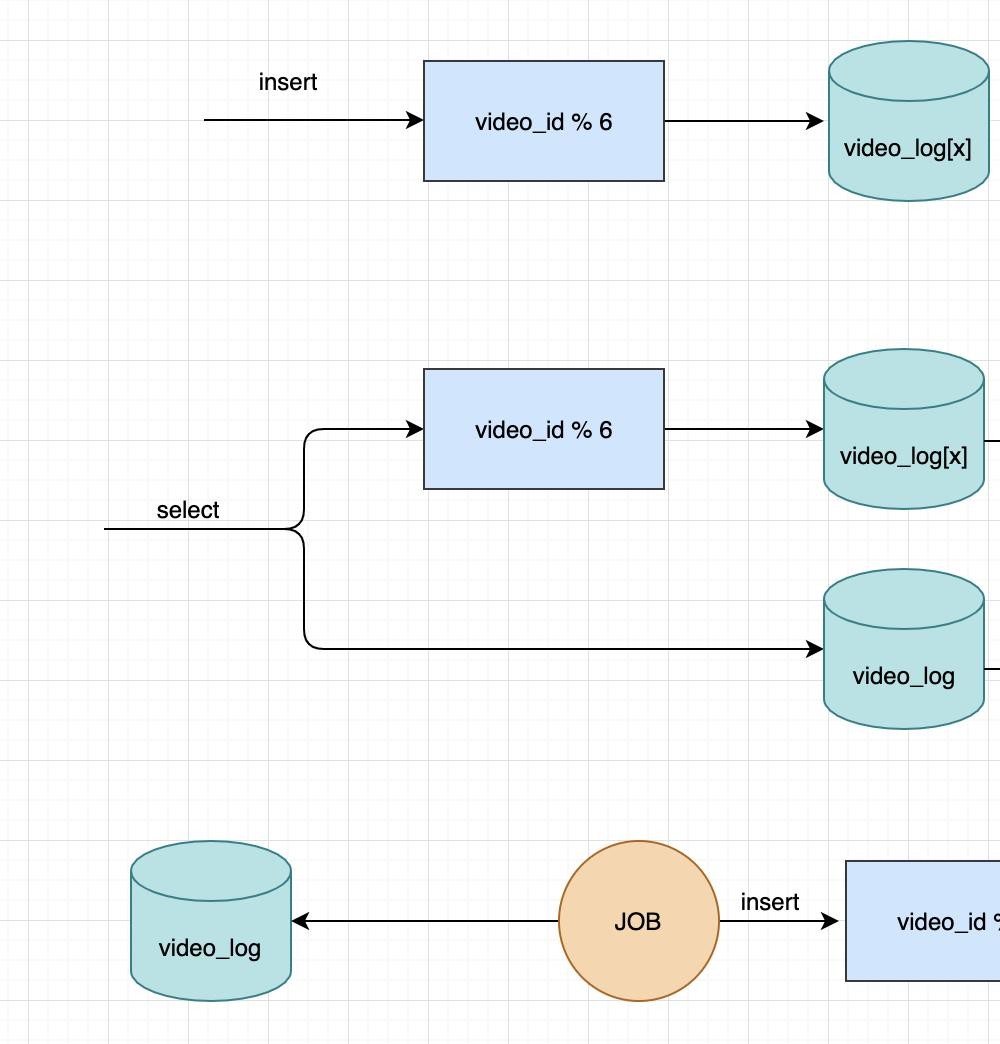
接下来就是改造代码了,得解决新老数据读写的问题。
方案二的缺点比较明显,3年后咋办,继续拆表?感觉始终有个历史债在那。于是我们的目光定位到了tidb,tidb是分布式的数据库,接入了tidb,我们就无需关心分表了,这些tidb都帮我们做了,它会自己做节点的扩容。由于是分布式的,所以tidb的主键是无序的,这点很重要。
整个流程大概分为以下4个步骤:

迁移至tidb,看似很简单,其实在job脚本这里隐藏着几个坑。

综合考虑数据的重复性,job重启效率性,和整个同步的效率性,我大概做出以下方案:
最终通过方案三的四个切换步骤+高效率的同步脚本平稳的完成了数据的迁移
到此这篇关于mysql迁移的方案与踩坑的文章就介绍到这了,更多相关mysql迁移方案与踩坑内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: 一次mysql迁移的方案与踩坑实战记录
本文链接: https://www.lsjlt.com/news/131809.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-04-26
2024-04-26
2024-04-26
2024-04-26
2024-04-26
2024-04-26
2024-04-24
2024-04-24
2024-04-24
2024-04-24
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0