Python 官方文档:入门教程 => 点击学习
内容介绍 以 python 使用 Keans 进行聚类分析的简单举例应用介绍聚类分析。 聚类分析 或 聚类 是对一组对象进行分组的任务,使得同一组(称为聚类)中的对象(在某种意义上)
以 python 使用 Keans 进行聚类分析的简单举例应用介绍聚类分析。
聚类分析 或 聚类 是对一组对象进行分组的任务,使得同一组(称为聚类)中的对象(在某种意义上)与其他组(聚类)中的对象更相似(在某种意义上)。
它是探索性数据挖掘的主要任务,也是统计数据分析的常用技术,用于许多领域,包括机器学习,模式识别,图像分析,信息检索,生物信息学,数据压缩和计算机图形学。
根据运营或商业目的挑选出来的变量,对目标群体进行聚类,将目标群体分成几个有明显的特征区别的细分群体,在运营活动中为这些细分群体采用精细化、个性化的运营和服务,提升运营的效率和商业效果。
按特定的指标变量对众多产品种类进行聚类。将产品体系细分成具有不同价值、不同目的、多维度产品组合,在此基础上制定相应的产品开发计划、运营计划和服务计划。
主要是风控应用。孤立点可能会存在欺诈的风险成分。
分为基于划分、层次、密度、网格、统计学、模型等类型的算法,典型算法包括K均值(经典的聚类算法)、DBSCAN、两步聚类、BIRCH、谱聚类等。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn import metrics
import random
# 随机生成100组包含3组特征的数据
feature = [[random.random(),random.random(),random.random()] for i in range(100)]
label = [int(random.randint(0,2)) for i in range(100)]
# 转换数据格式
x_feature = np.array(feature)
# 训练聚类模型
n_clusters = 3 # 设置聚类数量
model_kmeans = KMeans(n_clusters=n_clusters, random_state=0) # 建立聚类模型对象
model_kmeans.fit(x_feature) # 训练聚类模型
y_pre = model_kmeans.predict(x_feature) # 预测聚类模型
y_pre

是K均值模型对象的属性,表示样本距离最近的聚类中心的总和,它是作为在没有真实分类结果标签下的非监督式评估指标。
该值越小越好,值越小证明样本在类间的分布越集中,即类内的距离越小。
# 样本距离最近的聚类中心的总和
inertias = model_kmeans.inertia_
调整后的兰德指数(Adjusted Rand Index),兰德指数通过考虑在预测和真实聚类中在相同或不同聚类中分配的所有样本对和计数对来计算两个聚类之间的相似性度量。
调整后的兰德指数通过对兰德指数的调整得到独立于样本量和类别的接近于0的值,其取值范围为[-1, 1],负数代表结果不好,越接近于1越好意味着聚类结果与真实情况越吻合。
# 调整后的兰德指数
adjusted_rand_s = metrics.adjusted_rand_score(label, y_pre)互信息(Mutual InfORMation, MI),互信息是一个随机变量中包含的关于另一个随机变量的信息量,在这里指的是相同数据的两个标签之间的相似度的量度,结果是非负值。
# 互信息
mutual_info_s = metrics.mutual_info_score(label, y_pre)
调整后的互信息(Adjusted Mutual Information, AMI),调整后的互信息是对互信息评分的调整得分。
它考虑到对于具有更大数量的聚类群,通常MI较高,而不管实际上是否有更多的信息共享,它通过调整聚类群的概率来纠正这种影响。
当两个聚类集相同(即完全匹配)时,AMI返回值为1;随机分区(独立标签)平均预期AMI约为0,也可能为负数。
# 调整后的互信息
adjusted_mutual_info_s = metrics.adjusted_mutual_info_score(label, y_pre)
同质化得分(Homogeneity),如果所有的聚类都只包含属于单个类的成员的数据点,则聚类结果将满足同质性。其取值范围[0,1]值越大意味着聚类结果与真实情况越吻合。
# 同质化得分
homogeneity_s = metrics.homogeneity_score(label, y_pre)
完整性得分(Completeness),如果作为给定类的成员的所有数据点是相同集群的元素,则聚类结果满足完整性。其取值范围[0,1],值越大意味着聚类结果与真实情况越吻合。
# 完整性得分
completeness_s = metrics.completeness_score(label, y_pre)
它是同质化和完整性之间的谐波平均值,v = 2 (均匀性 完整性)/(均匀性+完整性)。其取值范围[0,1],值越大意味着聚类结果与真实情况越吻合。
v_measure_s = metrics.v_measure_score(label, y_pre)
轮廓系数(Silhouette),它用来计算所有样本的平均轮廓系数,使用平均群内距离和每个样本的平均最近簇距离来计算,它是一种非监督式评估指标。其最高值为1,最差值为-1,0附近的值表示重叠的聚类,负值通常表示样本已被分配到错误的集群。
# 平均轮廓系数
silhouette_s = metrics.silhouette_score(x_feature, y_pre, metric='euclidean')
该分数定义为群内离散与簇间离散的比值,它是一种非监督式评估指标。
# Calinski和Harabaz得分
calinski_harabaz_s = metrics.calinski_harabasz_score(x_feature, y_pre)
# 模型效果可视化
centers = model_kmeans.cluster_centers_ # 各类别中心
colors = ['#4EACC5', '#FF9C34', '#4E9A06'] # 设置不同类别的颜色
plt.figure() # 建立画布
for i in range(n_clusters): # 循环读类别
index_sets = np.where(y_pre == i) # 找到相同类的索引集合
cluster = x_feature[index_sets] # 将相同类的数据划分为一个聚类子集
plt.scatter(cluster[:, 0], cluster[:, 1], c=colors[i], marker='.') # 展示聚类子集内的样本点
plt.plot(centers[i][0], centers[i][1], 'o', markerfacecolor=colors[i], markeredgecolor='k',
markersize=6) # 展示各聚类子集的中心
plt.show() # 展示图像
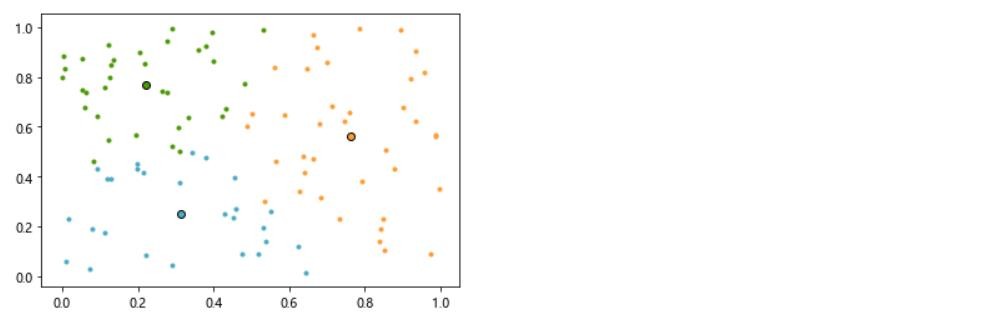
# 模型应用
new_X = [1, 3.6,9.9]
cluster_label = model_kmeans.predict(np.array(new_X).reshape(1,-1))
print ('聚类预测结果为: %d' % cluster_label)

以上就是分析总结Python数据化运营KMeans聚类的详细内容,更多关于Python数据化运营KMeans聚类的资料请关注编程网其它相关文章!
--结束END--
本文标题: 分析总结Python数据化运营KMeans聚类
本文链接: https://www.lsjlt.com/news/133601.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0