Python 官方文档:入门教程 => 点击学习
目录1、 创建用户2、 安装jdk3、 修改hosts4、 配置ssh免密登录5、 安装ZooKeeper解压:修改配置文件修改内容如下:配置环境变量启动6、 安装hadoop对于三
安装hadoop有好几种方式,以下按照hdfs高可用的方式来安装。
命令:
useradd -m bigdata
passwd bigdata
解压:
tar -zvf jdk-8u191-linux-x64.tar.gz
修改环境变量
JAVA_HOME=/usr/lib/JVM/java-8-openjdk-arm64
JRE_HOME=/usr/lib/jvm/java-8-openjdk-arm64/jre
CLASSPATH=:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME PATH CLASSPATH
修改/etc/hosts
10.211.55.12 hadoop01 # NameNode Active
10.211.55.13 hadoop01 # NameNode Standby
10.211.55.14 hadoop01 # DataNode1
在每一台需要配置的机器上执行以下命令:
ssh-keygen –t rsa
执行完成后默认会在其根目录下创建一个.ssh目录,在这个目录中有id_rsa和id_rsa.pub两个文件。然后将所有机器的id_rsa.pub文件的内容都合并到一个新的文件中,文件命名为authorized_keys,然后将该文件分发到各台机器上。
最后,使用ssh登录其他机器测试是否完成免密。
下载链接:https://zookeeper.apache.org/releases.html
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
将zookeeper下conf目录中的zoo_sample.cfg文件复制一份,新复制的文件重命名为zoo.cfg文件。
#zookeeper的文件路径
dataDir=/root/zookeeper/data
#zookeeper集群节点信息
server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
#server.A=B:C:D 其中A是一个数字,代表这是第几号服务器;B是服务器的IP地址;C表示服务器与群集中的“领导者”交换信息的端口;当领导者失效后,D表示用来执行选举时服务器相互通信的端口。
然后在上述设置的文件目录中新建一个文件,文件名为myid,文件内容为一个数字。例如上述配置的hadoop01对应的是server.1,它的myid的文件内容就是1。
修改/etc/profile文件
export ZOOKEEPER_HOME=/root/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
启动命令如下
#启动
zkServer.sh start
#查询状态
zkServer.sh status
hadoo01:journalnode、namenode、datanode、resourcemanager、nodemanager
hadoo02:journalnode、namenode、datanode、resourcemanager、nodemanager
hadoo03:journalnode、datanode、nodemanager
下载链接:Https://hadoop.apache.org/releases.html
tar -zxvf hadoop-2.7.6.tar.gz
hadoop的配置文件在解压后文件夹的etc目录下的hadoop目录中。
<configuration>
<!-- 配置hdfs的名称,其中value标签中的nns1为自定义的,与后文hdfs-site.xml中的属性对应即可-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://nns1</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 其他临时文件的存储的目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/HadoopData/HDFSData</value>
</property>
<!-- 下面两项与权限相关,在配置Hiveserver2的时候如果没配置这两项会出问题。name标签中的root需要改为你使用的用户名-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- -->
<!-- 配置zookeeper-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
</configuration>
<configuration>
<!-- 配置hdfs服务,需要与上文中的fs.defaultFS对应-->
<property>
<name>dfs.nameservices</name>
<value>nns1</value>
</property>
<!-- 配置hdfs的namenode,使用“,”分隔,value标签中的内容需要自定义-->
<property>
<name>dfs.ha.namenodes.nns1</name>
<value>nn1,nn2</value>
</property>
<!-- 配置两台namenode,name标签最后的内容需要与上文对应-->
<property>
<name>dfs.namenode.rpc-address.nns1.nn1</name>
<value>hadoop01:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.nns1.nn2</name>
<value>hadoop02:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.nns1.nn1</name>
<value>hadoop01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.nns1.nn2</name>
<value>hadoop02:50070</value>
</property>
<!--配置journalnode,修改value中的ip地址与端口便可,最后的nns1可以改为上述定义的名称 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/nns1</value>
</property>
<!-- 客户端连接可用状态的NameNode所用的代理类 -->
<property>
<name>dfs.client.failover.proxy.provider.nns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 一旦需要NameNode切换,使用ssh方式进行操作,配置了这个需要服务器能使用fuster,有的服务器可能需要安装 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 如果使用ssh进行故障切换,使用ssh通信时用的密钥存储的位置 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 指定journalnode的存储路径 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/HadoopData/HDFSData/journal</value>
</property>
<!-- 是否启动自动故障转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 指定namenode数据存储路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/HadoopData/HDFSData/name</value>
</property>
<!-- 指定datanode数据存储路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/HadoopData/HDFSData/data</value>
</property>
<!-- 设置文件副本数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 是否启动hdfs网页界面 -->
<property>
<name>dfs.WEBhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
<configuration>
<!-- 采用yarn作为mapReduce的资源调度框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
<configuration>
<!-- 启用HA高可用性 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 使用了2个resourcemanager,分别指定Resourcemanager的地址 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 配置集群名称 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1-yarn</value>
</property>
<!--配置RM节点 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop02</value>
</property>
<!--在hadoop01上配置rm1,在hadoop02上配置rm2,注意:一般都喜欢把配置好的文件远程复制到其它机器上,但这个在YARN的另一个机器上一定要修改 -->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<!--开启自动恢复功能 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--配置与zookeeper的连接地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<!-- 配置shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
hadoop01
hadoop02
hadoop03
slaves中配置的服务器ip,没改hosts文件则直接写ip地址便可。该文件配置的服务器在启动的时候会启动datanode和nodemanager两个进程。
(一般直接复制上述配置好的文件,注意yarn-site.xml中的id,还有保证配置中的路径在每台机器上都存在)。
初始化之前需要保证zookeeper能正常提供服务,启动命令之前有提到
初始化前需要保证journalnode已经启动。启动脚本在hadoop的sbin目录下,名字为hadoop-daemon.sh。
启动命令如下:
./hadoop-daemon.sh start journalnode
命令如下
hdfs zkfc -fORMatZK
命令如下
hadoop namenode -format
这一步会在上述hdfs-site.xml,配置的dfs.namenode.name.dir路径下创建一系列文件。
在另一台配置了namenode的服务器上执行以下命令:
hdfs namenode -bootstrapStanby
上述命令如果执行失败,还有一个简单的方法可以同步元数据。可以直接将步骤4中在第一台生成的文件复制到第二台服务器。
同样在sbin目录下,使用start-all.sh可以启动所有服务,使用start-dfs.sh和start-yarn.sh可以分别启动hdfs和yarn。
使用hadoop-deamon.sh和yarn-deamon.sh分别别启动hdfs和yarn的单个进程。
安装命令如下:
yum install psmisc
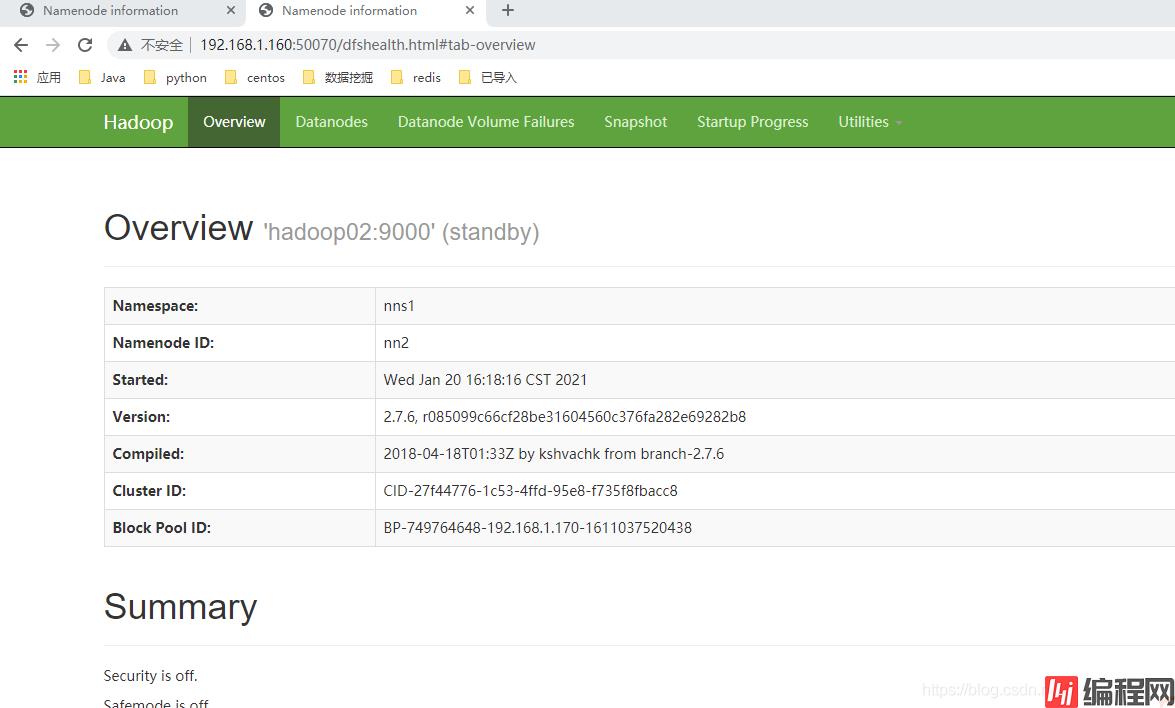
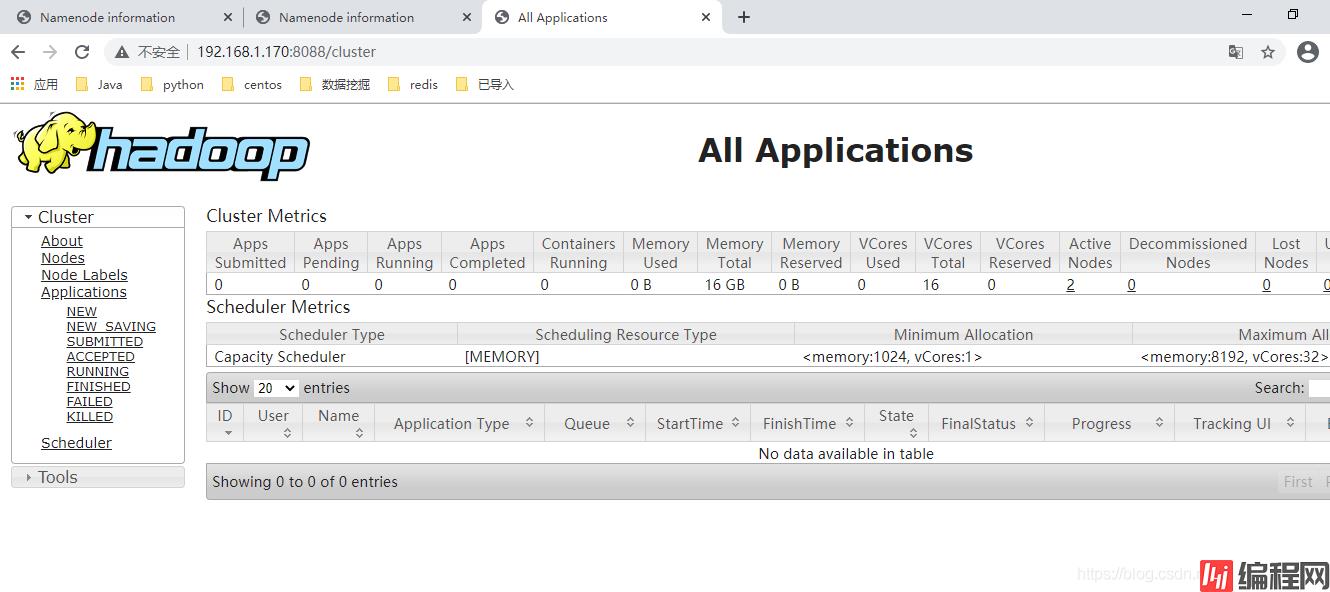
hdfs网页访问50070端口,yarn网页访问8088。这两个端口可以在配置文件中修改。
正常启动则可以访问到以下页面。
以上就是Hadoop源码分析二安装配置过程的详细内容,本系列下一篇文章传送门Hadoop源码分析三启动及脚本剖析更多Hadoop源码分析的资料请持续关注编程网!
--结束END--
本文标题: Hadoop源码分析二安装配置过程详解
本文链接: https://www.lsjlt.com/news/134447.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0