一、概念介绍: 1、sparkmagic:它是一个在Jupyter Notebook中的通过Livy服务器 Spark REST与远程Spark群集交互工作工具。Sparkmagic
1、sparkmagic:它是一个在Jupyter Notebook中的通过Livy服务器 Spark REST与远程Spark群集交互工作工具。Sparkmagic项目包括一组以多种语言交互运行Spark代码的框架和一些内核,可以使用这些内核将Jupyter Notebook中的代码转换在Spark环境运行。
2、Livy:它是一个基于Spark的开源REST服务,它能够通过REST的方式将代码片段或是序列化的二进制代码提交到Spark集群中去执行。它提供了以下这些基本功能:提交Scala、python或是R代码片段到远端的Spark集群上执行,提交Java、Scala、Python所编写的Spark作业到远端的Spark集群上执行和提交批处理应用在集群中运行
为下图所示:

具备提供Saprk集群,自己可以搭建或者直接使用华为云上服务,如MRS,并且在集群上安装Spark客户端。同节点(可以是Docker容器或者虚拟机)安装Jupyter Notebook和Livy,安装包的路径为:https://livy.incubator.apache.org/download/
修改livy.conf参考:Https://enterprise-docs.anaconda.com/en/latest/admin/advanced/config-livy-server.html
添加如下配置:
livy.spark.master = yarn
livy.spark.deploy-mode = cluster
livy.impersonation.enabled = false
livy.server.csrf-protection.enabled = false
livy.server.launch.kerberos.keytab=/opt/workspace/keytabs/user.keytab
livy.server.launch.kerberos.principal=miner
livy.superusers=miner修改livy-env.sh, 配置SPARK_HOME、hadoop_CONF_DIR等环境变量
export JAVA_HOME=/opt/Bigdata/client/jdk/jdk
export HADOOP_CONF_DIR=/opt/Bigdata/client/hdfs/hadoop/etc/hadoop
export SPARK_HOME=/opt/Bigdata/client/Spark2x/spark
export SPARK_CONF_DIR=/opt/Bigdata/client/Spark2x/spark/conf
export LIVY_LOG_DIR=/opt/workspace/apache-livy-0.7.0-incubating-bin/logs
export LIVY_PID_DIR=/opt/workspace/apache-livy-0.7.0-incubating-bin/pids
export LIVY_SERVER_JAVA_OPTS="-Djava.security.krb5.conf=/opt/Bigdata/client/KrbClient/kerberos/var/krb5kdc/krb5.conf -DZooKeeper.server.principal=zookeeper/hadoop.hadoop.com -Djava.security.auth.login.config=/opt/Bigdata/client/HDFS/hadoop/etc/hadoop/jaas.conf -Xmx128m"启动Livy:
./bin/livy-server start
Jupyter Notebook是一个开源并且使用很广泛项目,安装流程不在此赘述
sparkmagic可以理解为在Jupyter Notebook中的一种kernel,直接pip install sparkmagic。注意安装前系统必须具备GCc python-dev libkrb5-dev工具,如果没有,apt-get install或者yum install安装。安装完以后会生成$HOME/.sparkmagic/config.JSON文件,此文件为sparkmagic的关键配置文件,兼容spark的配置。关键配置如图所示

其中url为Livy服务的ip和端口,支持http和https两种协议
python3_KERNEL_DIR="$(jupyter kernelspec list | grep -w "python3" | awk '{print $2}')"
KERNELS_FOLDER="$(dirname "${PYTHON3_KERNEL_DIR}")"
SITE_PACKAGES="$(pip show sparkmagic|grep -w "Location" | awk '{print $2}')"
cp -r ${SITE_PACKAGES}/sparkmagic/kernels/pysparkkernel ${KERNELS_FOLDER}
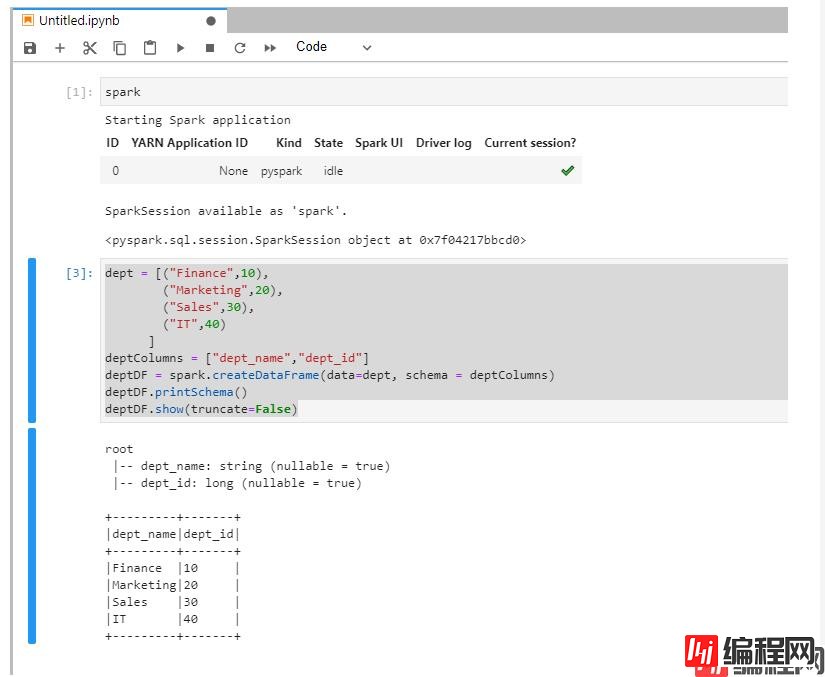

到此这篇关于基于Jupyter notebook搭建Spark集群开发环境的详细过程的文章就介绍到这了,更多相关基于Jupyter notebook搭建Spark集群开发环境内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: 基于Jupyter notebook搭建Spark集群开发环境的详细过程
本文链接: https://www.lsjlt.com/news/137859.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0