Python 官方文档:入门教程 => 点击学习
目录效果图开发完成后的界面采集过程界面采集后存储主要功能用到的第三方模块打包为 exe 命令全部源码效果图 最近帮朋友写个简单爬虫,顺便整理了下,搞成了一个带GUI界面的小说爬虫工具
最近帮朋友写个简单爬虫,顺便整理了下,搞成了一个带GUI界面的小说爬虫工具,用来从笔趣阁爬取小说。

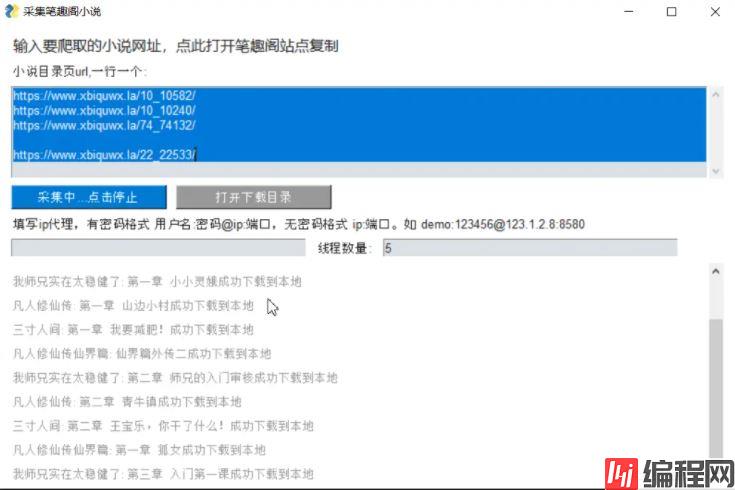

2.支持使用代理,尤其是多线程采集时,不使用代理可能封ip

3.实时输出采集结果

使用 threading.BoundedSemaphore() pool_sema.acquire() pool_sema.release() 来限制线程数量,防止并发线程过。具体限制数量,可在软件界面输入,默认5个线程

# 所有线程任务开始前
pool_sema.threading.BoundedSemaphore(5)
# 具体每个线程开始前 锁
pool_sema.acquire()
....
# 线程任务执行结束释放
pol_sema.release()
pip install requests
pip install pysimplegui
pip install lxml
pip install pyinstaller
GUI 界面使用了一个tkinter 的封装库 PySimpleGUI, 使用非常方便,虽然界面不够漂亮,但胜在简单,非常适合开发些小工具。https://pysimplegui.readthedocs.io/en/latest/比如这个界面的布局,只需简单几个 list
layout = [
[sg.Text('输入要爬取的小说网址,点此打开笔趣阁站点复制', font=("微软雅黑", 12),
key="openWEBsite", enable_events=True, tooltip="点击在浏览器中打开")],
[sg.Text("小说目录页url,一行一个:")],
[
sg.Multiline('', key="url", size=(120, 6), autoscroll=True, expand_x=True, right_click_menu=['&Right', ['粘贴']]
)
],
[sg.Text(visible=False, text_color="#ff0000", key="error")],
[
sg.Button(button_text='开始采集', key="start", size=(20, 1)),
sg.Button(button_text='打开下载目录', key="opendir",
size=(20, 1), button_color="#999999")
],
[sg.Text('填写ip代理,有密码格式 用户名:密码@ip:端口,无密码格式 ip:端口。如 demo:123456@123.1.2.8:8580')],
[
sg.Input('', key="proxy"),
sg.Text('线程数量:'),
sg.Input('5', key="threadnum"),
],
[
sg.Multiline('等待采集', key="res", disabled=True, border_width=0, background_color="#ffffff", size=(
120, 6), no_scrollbar=False, autoscroll=True, expand_x=True, expand_y=True, font=("宋体", 10), text_color="#999999")
],
]pyinstaller -Fw start.py
import time
import requests
import os
import sys
import re
import random
from lxml import etree
import webbrowser
import PySimpleGUI as sg
import threading
# user-agent
header = {
"User-Agent": "Mozilla/5.0 (windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/97.0.4692.99 Safari/537.36"
}
# 代理
proxies = {}
# 删除书名中特殊符号
# 笔趣阁基地址
baseurl = 'Https://www.xbiquwx.la/'
# 线程数量
threadNum = 6
pool_sema = None
THREAD_EVENT = '-THREAD-'
cjstatus = False
# txt存储目录
filePath = os.path.abspath(os.path.join(os.getcwd(), 'txt'))
if not os.path.exists(filePath):
os.mkdir(filePath)
# 删除特殊字符
def deletetag(text):
return re.sub(r'[\[\]#\/\\:*\,;\?\"\'<>\|\(\)《》&\^!~=%\{\}@!:。·!¥……() ]','',text)
# 入口
def main():
global cjstatus, proxies, threadNum, pool_sema
sg.theme("reddit")
layout = [
[sg.Text('输入要爬取的小说网址,点此打开笔趣阁站点复制', font=("微软雅黑", 12),
key="openwebsite", enable_events=True, tooltip="点击在浏览器中打开")],
[sg.Text("小说目录页url,一行一个:")],
[
sg.Multiline('', key="url", size=(120, 6), autoscroll=True, expand_x=True, right_click_menu=['&Right', ['粘贴']]
)
],
[sg.Text(visible=False, text_color="#ff0000", key="error")],
[
sg.Button(button_text='开始采集', key="start", size=(20, 1)),
sg.Button(button_text='打开下载目录', key="opendir",
size=(20, 1), button_color="#999999")
],
[sg.Text('填写ip代理,有密码格式 用户名:密码@ip:端口,无密码格式 ip:端口。如 demo:123456@123.1.2.8:8580')],
[
sg.Input('', key="proxy"),
sg.Text('线程数量:'),
sg.Input('5', key="threadnum"),
],
[
sg.Multiline('等待采集', key="res", disabled=True, border_width=0, background_color="#ffffff", size=(
120, 6), no_scrollbar=False, autoscroll=True, expand_x=True, expand_y=True, font=("宋体", 10), text_color="#999999")
],
]
window = sg.Window('采集笔趣阁小说', layout, size=(800, 500), resizable=True,)
while True:
event, values = window.read()
if event == sg.WIN_CLOSED or event == 'close': # if user closes window or clicks cancel
break
if event == "openwebsite":
webbrowser.open('%s' % baseurl)
elif event == 'opendir':
os.system('start explorer ' + filePath)
elif event == 'start':
if cjstatus:
cjstatus = False
window['start'].update('已停止...点击重新开始')
continue
window['error'].update("", visible=False)
urls = values['url'].strip().split("\n")
lenth = len(urls)
for k, url in enumerate(urls):
if (not re.match(r'%s\d+_\d+/' % baseurl, url.strip())):
if len(url.strip()) > 0:
window['error'].update("地址错误:%s" % url, visible=True)
del urls[k]
if len(urls) < 1:
window['error'].update(
"每行地址需符合 %s84_84370/ 形式" % baseurlr, visible=True)
continue
# 代理
if len(values['proxy']) > 8:
proxies = {
"http": "http://%s" % values['proxy'],
"https": "http://%s" % values['proxy']
}
# 线程数量
if values['threadnum'] and int(values['threadnum']) > 0:
threadNum = int(values['threadnum'])
pool_sema = threading.BoundedSemaphore(threadNum)
cjstatus = True
window['start'].update('采集中...点击停止')
window['res'].update('开始采集')
for url in urls:
threading.Thread(target=downloadbybook, args=(
url.strip(), window,), daemon=True).start()
elif event == "粘贴":
window['url'].update(sg.clipboard_get())
print("event", event)
if event == THREAD_EVENT:
strtext = values[THREAD_EVENT][1]
window['res'].update(window['res'].get()+"\n"+strtext)
cjstatus = False
window.close()
#下载
def downloadbybook(page_url, window):
try:
bookpage = requests.get(url=page_url, headers=header, proxies=proxies)
except Exception as e:
window.write_event_value(
'-THREAD-', (threading.current_thread().name, '\n请求 %s 错误,原因:%s' % (page_url, e)))
return
if not cjstatus:
return
# 锁线程
pool_sema.acquire()
if bookpage.status_code != 200:
window.write_event_value(
'-THREAD-', (threading.current_thread().name, '\n请求%s错误,原因:%s' % (page_url, page.reason)))
return
bookpage.encoding = 'utf-8'
page_tree = etree.HTML(bookpage.text)
bookname = page_tree.xpath('//div[@id="info"]/h1/text()')[0]
bookfilename = filePath + '/' + deletetag(bookname)+'.txt'
zj_list = page_tree.xpath(
'//div[@class="box_con"]/div[@id="list"]/dl/dd')
for _ in zj_list:
if not cjstatus:
break
zjurl = page_url + _.xpath('./a/@href')[0]
zjname = _.xpath('./a/@title')[0]
try:
zjpage = requests.get(
zjurl, headers=header, proxies=proxies)
except Exception as e:
window.write_event_value('-THREAD-', (threading.current_thread(
).name, '\n请求%s:%s错误,原因:%s' % (zjname, zjurl, zjpage.reason)))
continue
if zjpage.status_code != 200:
window.write_event_value('-THREAD-', (threading.current_thread(
).name, '\n请求%s:%s错误,原因:%s' % (zjname, zjurl, zjpage.reason)))
return
zjpage.encoding = 'utf-8'
zjpage_content = etree.HTML(zjpage.text).xpath('//div[@id="content"]/text()')
content = "\n【"+zjname+"】\n"
for _ in zjpage_content:
content += _.strip() + '\n'
with open(bookfilename, 'a+', encoding='utf-8') as fs:
fs.write(content)
window.write_event_value(
'-THREAD-', (threading.current_thread().name, '\n%s:%s 采集成功' % (bookname, zjname)))
time.sleep(random.unifORM(0.05, 0.2))
# 下载完毕
window.write_event_value('-THREAD-', (threading.current_thread(
).name, '\n请求 %s 结束' % page_url))
pool_sema.release()
if __name__ == '__main__':
main()
以上就是基于python3制作一个带GUI界面的小说爬虫工具的详细内容,更多关于python3小说爬虫工具的资料请关注编程网其它相关文章!
--结束END--
本文标题: 基于Python3制作一个带GUI界面的小说爬虫工具
本文链接: https://www.lsjlt.com/news/138286.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0