Python 官方文档:入门教程 => 点击学习
目录一、数据集爬取二、数据处理三、开始识别四、模型测试总结一、数据集爬取 现在的深度学习对数据集量的需求越来越大了,也有了许多现成的数据集可供大家查找下载,但是如果你只是想要做一下深
现在的深度学习对数据集量的需求越来越大了,也有了许多现成的数据集可供大家查找下载,但是如果你只是想要做一下深度学习的实例以此熟练一下或者找不到好的数据集,那么你也可以尝试自己制作数据集——自己从网上爬取图片,下面是通过百度图片爬取数据的示例。
import os
import time
import requests
import re
def imgdata_set(save_path,Word,epoch):
q=0 #停止爬取图片条件
a=0 #图片名称
while(True):
time.sleep(1)
url="https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word={}&pn={}&ct=&ic=0&lm=-1&width=0&height=0".fORMat(word,q)
#word=需要搜索的名字
headers={
'User-Agent': 'Mozilla/5.0 (windows NT 10.0; Win64; x64) AppleWEBKit/537.36 (Khtml, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.56'
}
response=requests.get(url,headers=headers)
# print(response.request.headers)
html=response.text
# print(html)
urls=re.findall('"objURL":"(.*?)"',html)
# print(urls)
for url in urls:
print(a) #图片的名字
response = requests.get(url, headers=headers)
image=response.content
with open(os.path.join(save_path,"{}.jpg".format(a)),'wb') as f:
f.write(image)
a=a+1
q=q+20
if (q/20)>=int(epoch):
break
if __name__=="__main__":
save_path = input('你想保存的路径:')
word = input('你想要下载什么图片?请输入:')
epoch = input('你想要下载几轮图片?请输入(一轮为60张左右图片):') # 需要迭代几次图片
imgdata_set(save_path, word, epoch)
通过上述的代码可以自行选择自己需要保存的图片路径、图片种类和图片数目。如我下面做的几种常见的盆栽植物的图片爬取,只需要执行六次代码,改变相应的盆栽植物的名称就可以了。下面是爬取盆栽芦荟的输入示例,输入完成后按Enter执行即可,会自动爬取图片保存到指定文件夹,

如图即为爬取后的图片。
可以看到图片中出现了一些无法打开的图片,同时因为是直接爬取的网络上的图片,可能会出现一些相同的图片,这些都需要进行删除,这就需要我们进行第二步处理了。
由于上面直接爬取到的图片有一些瑕疵,这就需要对图片进行进一步的处理了,对图片进行去重处理
通过重复图片去重处理,将自己需要的数据集按照种类分别保存在各自的文件夹里。同样,由于数据集可能存在无法打开的图片,这就需要对数据集进行下一步处理了。
首先将上面去重处理后的文件夹统一保存在同一个文件夹里面,如下图所示。
记住此文件夹路径,我这里是‘C:\Users\Lenovo\Desktop\data’,将此路径输入到下面代码中。
import os
from PIL import Image
root_path=r"C:\Users\Lenovo\Desktop\data" #待处理文件夹绝对路径(可按‘Ctrl+Shift+c'复制)
root_names=os.listdir(root_path)
for root_name in root_names:
path=os.path.join(root_path,root_name)
print("正在删除文件夹:",path)
names=os.listdir(path)
names_path=[]
for name in names:
# print(name)
img=Image.open(os.path.join(path,name))
name_path=os.path.join(path,name)
if img==None: #筛选无法打开的图片
names_path.append(name_path)
print('成功保存错误图片路径:{}'.format(name))
else:
w,h=img.size
if w<50 or h<50: #筛选错误图片
names_path.append(name_path)
print('成功保存特小图片路径:{}'.format(name))
print("开始删除需删除的图片")
for r in names_path:
os.remove(r)
print("已删除:",r)
经过上述处理即完成了图片数据集的处理。最后,也可以对图片数据集进行图片名称的处理,使图片的名称重新从零开始依次排列,方便计数(注意下面代码中的rename将会删除掉原文件夹中的图片)。
import os
root_dir=r"C:\Users\Lenovo\Desktop\pzlh" #原文件夹路径
save_path=r"C:\Users\Lenovo\Desktop\pzlh2" #新建文件夹路径
img_path=os.listdir(root_dir)
a=0
for i in img_path:
a+=1
i= os.path.join(os.path.abspath(root_dir), i)
new_name=os.path.join(os.path.abspath(save_path), str(a) + '_pzlh.jpg') #此处可以修改图片名称
os.rename(i,new_name) #特别注意:rename会删除原图
最后,我们可以得到一个将完整的常见盆栽植物的数据集。如果此时数据集的图片数量不多,我们还可以采用数据增强的方法,如旋转,加噪等步骤,都可以在网上找到相应的教程。最后,我们可以得到数据集如下图所示。

首先,先为上面的图片数据集生成对应的标签文件,运行下面代码可以自动生成对应的标签文件。
import os
root_path=r"C:\Users\Lenovo\Desktop\data"
save_path=r"C:\Users\Lenovo\Desktop\data_label" #对应的label文件夹下也要建好相应的空子文件夹
names=os.listdir(root_path) #得到images文件夹下的子文件夹的名称
for name in names:
path=os.path.join(root_path,name)
img_names=os.listdir(path) #得到子文件夹下的图片的名称
for img_name in img_names:
save_name = img_name.split(".jpg")[0]+'.txt' #得到相应的lable名称
txt_path=os.path.join(save_path,name) #得到label的子文件夹的路径
with open(os.path.join(txt_path,save_name), "w") as f: #结合子文件夹路径和相应子文件夹下图片的名称生成相应的子文件夹txt文件
f.write(name) #将label写入对应txt文件夹
print(f.name)
然后,将上面已经准备好的数据集按照7:3(其他比例也可以)分为训练数据集和验证数据集(图片和标签一定要完全对应即对应图片和标签应该都处于训练集或者数据集),并如下图所示放置。
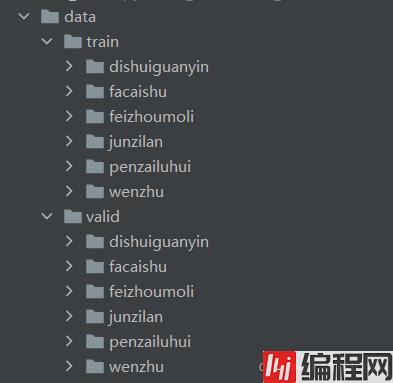
最后,数据集准备好后,即可导入到模型开始训练,运行下列代码
import time
from torch.utils.tensorboard import SummaryWriter
from torchvision.datasets import ImageFolder
from torchvision import transforms
from torch.utils.data import DataLoader
import torchvision.models as models
import torch.nn as nn
import torch
print("是否使用GPU训练:{}".format(torch.cuda.is_available())) #打印是否采用gpu训练
if torch.cuda.is_available:
print("GPU名称为:{}".format(torch.cuda.get_device_name())) #打印相应的gpu信息
#数据增强太多也可能造成训练出不好的结果,而且耗时长,宜增强两三倍即可。
normalize=transforms.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5]) #规范化
transform=transforms.Compose([ #数据处理
transforms.Resize((64,64)),
transforms.ToTensor(),
normalize
])
dataset_train=ImageFolder('data/train',transform=transform) #训练数据集
# print(dataset_tran[0])
dataset_valid=ImageFolder('data/valid',transform=transform) #验证或测试数据集
# print(dataset_train.classer)#返回类别
print(dataset_train.class_to_idx) #返回类别及其索引
# print(dataset_train.imgs)#返回图片路径
print(dataset_valid.class_to_idx)
train_data_size=len(dataset_train) #放回数据集长度
test_data_size=len(dataset_valid)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
#torch自带的标准数据集加载函数
dataloader_train=DataLoader(dataset_train,batch_size=4,shuffle=True,num_workers=0,drop_last=True)
dataloader_test=DataLoader(dataset_valid,batch_size=4,shuffle=True,num_workers=0,drop_last=True)
#2.模型加载
model_ft=models.resnet18(pretrained=True)#使用迁移学习,加载预训练权重
# print(model_ft)
in_features=model_ft.fc.in_features
model_ft.fc=nn.Sequential(nn.Linear(in_features,36),
nn.Linear(36,6))#将最后的全连接改为(36,6),使输出为六个小数,对应六种植物的置信度
#冻结卷积层函数
# for i,para in enumerate(model_ft.parameters()):
# if i<18:
# para.requires_grad=False
# print(model_ft)
# model_ft.half()#可改为半精度,加快训练速度,在这里不适用
model_ft=model_ft.cuda()#将模型迁移到gpu
#3.优化器
loss_fn=nn.CrossEntropyLoss()
loss_fn=loss_fn.cuda() #将loss迁移到gpu
learn_rate=0.01 #设置学习率
optimizer=torch.optim.SGD(model_ft.parameters(),lr=learn_rate,momentum=0.01)#可调超参数
total_train_step=0
total_test_step=0
epoch=50 #迭代次数
writer=SummaryWriter("logs_train_yaopian")
best_acc=-1
ss_time=time.time()
for i in range(epoch):
start_time = time.time()
print("--------第{}轮训练开始---------".format(i+1))
model_ft.train()
for data in dataloader_train:
imgs,targets=data
# if torch.cuda.is_available():
# imgs.float()
# imgs=imgs.float()#为上述改为半精度操作,在这里不适用
imgs=imgs.cuda()
targets=targets.cuda()
# imgs=imgs.half()
outputs=model_ft(imgs)
loss=loss_fn(outputs,targets)
optimizer.zero_grad() #梯度归零
loss.backward() #反向传播计算梯度
optimizer.step() #梯度优化
total_train_step=total_train_step+1
if total_train_step%100==0:#一轮时间过长可以考虑加一个
end_time=time.time()
print("使用GPU训练100次的时间为:{}".format(end_time-start_time))
print("训练次数:{},loss:{}".format(total_train_step,loss.item()))
# writer.add_Scalar("valid_loss",loss.item(),total_train_step)
model_ft.eval()
total_test_loss=0
total_accuracy=0
with torch.no_grad(): #验证数据集时禁止反向传播优化权重
for data in dataloader_test:
imgs,targets=data
# if torch.cuda.is_available():
# imgs.float()
# imgs=imgs.float()
imgs = imgs.cuda()
targets = targets.cuda()
# imgs=imgs.half()
outputs=model_ft(imgs)
loss=loss_fn(outputs,targets)
total_test_loss=total_test_loss+loss.item()
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
print("整体测试集上的loss:{}(越小越好,与上面的loss无关此为测试集的总loss)".format(total_test_loss))
print("整体测试集上的正确率:{}(越大越好)".format(total_accuracy / len(dataset_valid)))
writer.add_scalar("valid_loss",(total_accuracy/len(dataset_valid)),(i+1))#选择性使用哪一个
total_test_step = total_test_step + 1
if total_accuracy > best_acc: #保存迭代次数中最好的模型
print("已修改模型")
best_acc = total_accuracy
torch.save(model_ft, "best_model_yaopian.pth")
ee_time=time.time()
zong_time=ee_time-ss_time
print("训练总共用时:{}h:{}m:{}s".format(int(zong_time//3600),int((zong_time%3600)//60),int(zong_time%60))) #打印训练总耗时
writer.close()
上述采用的迁移学习直接使用resnet18的模型进行训练,只对全连接的输出进行修改,是一种十分方便且实用的方法,同样,你也可以自己编写模型,然后使用自己的模型进行训练,但是这种方法显然需要训练更长的时间才能达到拟合。如图所示,只需要修改矩形框内部分,将‘model_ft=models.resnet18(pretrained=True)'改为自己的模型‘model_ft=model’即可。

经过上述的步骤后,我们将会得到一个‘best_model_yaopian.pth’的模型权重文件,最后运行下列代码就可以对图片进行识别了
import os
import torch
import torchvision
from PIL import Image
from torch import nn
i=0 #识别图片计数
root_path="测试_data" #待测试文件夹
names=os.listdir(root_path)
for name in names:
print(name)
i=i+1
data_class=['滴水观音','发财树','非洲茉莉','君子兰','盆栽芦荟','文竹'] #按文件索引顺序排列
image_path=os.path.join(root_path,name)
image=Image.open(image_path)
print(image)
transforms=torchvision.transforms.Compose([torchvision.transforms.Resize((64,64)),
torchvision.transforms.ToTensor()])
image=transforms(image)
print(image.shape)
model_ft=torchvision.models.resnet18() #需要使用训练时的相同模型
# print(model_ft)
in_features=model_ft.fc.in_features
model_ft.fc=nn.Sequential(nn.Linear(in_features,36),
nn.Linear(36,6)) #此处也要与训练模型一致
model=torch.load("best_model_yaopian.pth",map_location=torch.device("cpu")) #选择训练后得到的模型文件
# print(model)
image=torch.reshape(image,(1,3,64,64)) #修改待预测图片尺寸,需要与训练时一致
model.eval()
with torch.no_grad():
output=model(image)
print(output) #输出预测结果
# print(int(output.argmax(1)))
print("第{}张图片预测为:{}".format(i,data_class[int(output.argmax(1))])) #对结果进行处理,使直接显示出预测的植物种类
最后,通过上述步骤我们可以得到一个简单的盆栽植物智能识别程序,对盆栽植物进行识别,如下图是识别结果说明。

到这里,我们就实现了一个简单的深度学习图像识别示例了。
到此这篇关于python PyTorch图像识别基础介绍的文章就介绍到这了,更多相关Python pytorch图像识别内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: python pytorch图像识别基础介绍
本文链接: https://www.lsjlt.com/news/139005.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0