Python 官方文档:入门教程 => 点击学习
目录1.如何用函数2.默认参数陷阱2.1针对可变数据类型,不可变不受影响3.名称空间和作用域4.闭包函数5.函数的参数5.1定义阶段5.2调用阶段6.装饰器:闭包函数的应用6.1装饰
先定义后调用,定义阶段只检测语法,不执行代码
调用阶段,开始执行代码
函数都有返回值
定义时无参,调用时也是无参
定义时有参,调用时也必须有参
def c(a=[]):
a.append(1)
print(a)
c()
c()
c()
结果:
[1]
[1, 1]
[1, 1, 1]
def c(a=[]):
a.append(1)
print(a)
c([])
c([])
c([])
结果:
[1]
[1]
[1]
名称空间就是用来存放名字与值内存地址绑定关系的地方(内存空间)
但凡查找值一定要通过名字,访问名字必须去查找名称空间
名称空间分为三大类
内置名称空间: 存放的是python解释器自带的名字
生命周期: 在解释器启动时则生效,解释器关闭则失效
全局名称空间: 存放的是文件级别的名字
生命周期: 在解释器解释执行Python文件时则生效,文件执行完毕后则失效
局部名称空间: 在函数内定义的名字
生命周期: 只在调用函数时临时产生该函数的局部名称空间,该函数调用完毕则失效
加载顺序
内置->全局->局部
查找名字的顺序
基于当前所在位置往上查找
假设当前站在局部,查找顺序:局部->全局->内置
假设当前站在全局,查找顺序:全局->内置
名字的查找顺序,在函数定义阶段就已经固定死了(即在检测语法时就已经确定了名字的查找顺序),与函数的调用位置无关
也就是说无论在任何地方调用函数,都必须回到当初定义函数的位置去确定名字的查找关系
作用域: 作用域指的就是作用的范围
全局作用域: 包含的是内置名称空间与全局名称空间中的名字
特点: 全局有效,全局存活
局部作用域: 包含的是局部名称空间中的名字
特点: 局部有效,临时存活
global: 在局部声明一个名字是来自于全局作用域的,可以用来在局部修改全局的不可变类型
nonlocal: 声明一个名字是来自于当前层外一层作用域的,可以用来在局部修改外层函数的不可变类型
定义在函数内部且包含对外部函数的作用域名字的引用,需要结合函数对象的概念将闭包函数返回到全局作用域去使用,从而打破函数的层级限制
闭包函数提供了一种为函数体传值的解决方案
def func():
name='eGon'
def inner():
print(name)
return inner
inner = func()
inner()
位置形参
在定义阶段从左往右的顺序依次定义的形参
默认形参
在定义阶段已经为其初始化赋值
关键字参数
自由主题
可变长度的形参args
溢出的位置参数,打包成元组,给接受,赋给args的变量名
命名关键字参数
放在*和之间的参数,必须按照key=value形式传值
可变长度的位置形参kwargs
溢出的关键字实参,打包成字典,给**接受,赋给变量kwargs
形参和实参关系: 在调用函数时,会将实参的值绑定给形参的变量名,这种绑定关系临时生效,在调用结束后就失效了
位置实参
调用阶段按照从左往右依次传入的传入的值,会与形参一一对应
关键字实参
在调用阶段,按照key=value形式指名道姓的为形参传值
实参中带*的,再传值前先将打散成位置实参,再进行赋值
实参中带的**,在传值前先将其打散成关键字实参,再进行赋值
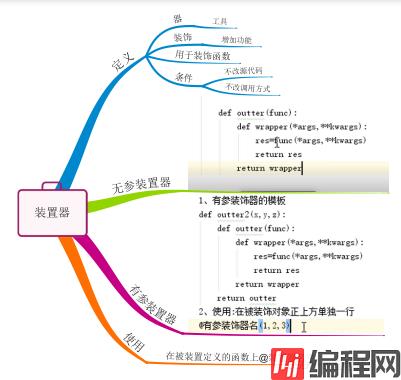
装饰器就是用来为被装饰器对象添加新功能的工具
**注意:**装饰器本身可以是任意可调用对象,被装饰器的对象也可以是任意可调用对象
为何使用装饰器
**开放封闭原则:**封闭指的是对修改封闭,对扩展开放
1. 不修改被装饰对象的源代码`
2. 不修改被装饰器对象的调用方式
装饰器的目标:就是在遵循1和2原则的前提下为被装饰对象添加上新功能
在被装饰对象正上方单独一行写@装饰器的名字
python解释器一旦运行到@装饰器的名字,就会调用装饰器,然后将被装饰函数的内存地址当作参数传给装饰器,最后将装饰器调用的结果赋值给原函数名 foo=auth(foo) 此时的foo是闭包函数wrapper
import time
def timmer(func):
def wrapper(*args,**kwargs):
start_time=time.time()
res=func(*args,**kwargs)
stop_time=time.time()
print('run time is %s' %(stop_time-start_time))
return res
return wrapper
@timmer
def foo():
time.sleep(3)
print('from foo')
foo()
def auth(driver='file'):
def auth2(func):
def wrapper(*args,**kwargs):
name=input("user: ")
pwd=input("pwd: ")
if driver == 'file':
if name == 'egon' and pwd == '123':
print('login successful')
res=func(*args,**kwargs)
return res
elif driver == 'ldap':
print('ldap')
return wrapper
return auth2
@auth(driver='file')
def foo(name):
print(name)
foo('egon')
#题目一:
db='db.txt'
login_status={'user':None,'status':False}
def auth(auth_type='file'):
def auth2(func):
def wrapper(*args,**kwargs):
if login_status['user'] and login_status['status']:
return func(*args,**kwargs)
if auth_type == 'file':
with open(db,encoding='utf-8') as f:
dic=eval(f.read())
name=input('username: ').strip()
passWord=input('password: ').strip()
if name in dic and password == dic[name]:
login_status['user']=name
login_status['status']=True
res=func(*args,**kwargs)
return res
else:
print('username or password error')
elif auth_type == 'sql':
pass
else:
pass
return wrapper
return auth2
@auth()
def index():
print('index')
@auth(auth_type='file')
def home(name):
print('welcome %s to home' %name)
# index()
# home('egon')
#题目二
import time,random
user={'user':None,'login_time':None,'timeout':0.000003,}
def timmer(func):
def wrapper(*args,**kwargs):
s1=time.time()
res=func(*args,**kwargs)
s2=time.time()
print('%s' %(s2-s1))
return res
return wrapper
def auth(func):
def wrapper(*args,**kwargs):
if user['user']:
timeout=time.time()-user['login_time']
if timeout < user['timeout']:
return func(*args,**kwargs)
name=input('name>>: ').strip()
password=input('password>>: ').strip()
if name == 'egon' and password == '123':
user['user']=name
user['login_time']=time.time()
res=func(*args,**kwargs)
return res
return wrapper
@auth
def index():
time.sleep(random.randrange(3))
print('welcome to index')
@auth
def home(name):
time.sleep(random.randrange(3))
print('welcome %s to home ' %name)
index()
home('egon')
#题目三:简单版本
import requests
import os
cache_file='cache.txt'
def make_cache(func):
def wrapper(*args,**kwargs):
if not os.path.exists(cache_file):
with open(cache_file,'w'):pass
if os.path.getsize(cache_file):
with open(cache_file,'r',encoding='utf-8') as f:
res=f.read()
else:
res=func(*args,**kwargs)
with open(cache_file,'w',encoding='utf-8') as f:
f.write(res)
return res
return wrapper
@make_cache
def get(url):
return requests.get(url).text
# res=get('https://www.python.org')
# print(res)
#题目四:扩展版本
import requests,os,hashlib
engine_settings={
'file':{'dirname':'./db'},
'Mysql':{
'host':'127.0.0.1',
'port':3306,
'user':'root',
'password':'123'},
'Redis':{
'host':'127.0.0.1',
'port':6379,
'user':'root',
'password':'123'},
}
def make_cache(engine='file'):
if engine not in engine_settings:
raise TypeError('egine not valid')
def deco(func):
def wrapper(url):
if engine == 'file':
m=hashlib.md5(url.encode('utf-8'))
cache_filename=m.hexdigest()
cache_filepath=r'%s/%s' %(engine_settings['file']['dirname'],cache_filename)
if os.path.exists(cache_filepath) and os.path.getsize(cache_filepath):
return open(cache_filepath,encoding='utf-8').read()
res=func(url)
with open(cache_filepath,'w',encoding='utf-8') as f:
f.write(res)
return res
elif engine == 'mysql':
pass
elif engine == 'redis':
pass
else:
pass
return wrapper
return deco
@make_cache(engine='file')
def get(url):
return requests.get(url).text
# print(get('Https://www.python.org'))
print(get('https://www.baidu.com'))
#题目五
route_dic={}
def make_route(name):
def deco(func):
route_dic[name]=func
return deco
@make_route('select')
def func1():
print('select')
@make_route('insert')
def func2():
print('insert')
@make_route('update')
def func3():
print('update')
@make_route('delete')
def func4():
print('delete')
print(route_dic)
#题目六
import time
import os
def logger(logfile):
def deco(func):
if not os.path.exists(logfile):
with open(logfile,'w'):pass
def wrapper(*args,**kwargs):
res=func(*args,**kwargs)
with open(logfile,'a',encoding='utf-8') as f:
f.write('%s %s run\n' %(time.strftime('%Y-%m-%d %X'),func.__name__))
return res
return wrapper
return deco
@logger(logfile='aaaaaaaaaaaaaaaaaaaaa.log')
def index():
print('index')
index()
到此这篇关于Python必备技巧之函数的使用详解的文章就介绍到这了,更多相关Python函数内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python必备技巧之函数的使用详解
本文链接: https://www.lsjlt.com/news/144985.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0