Python 官方文档:入门教程 => 点击学习
目录前言什么是消息累加器RecordAccumulator消息缓存模型ProducerBatch的内存大小内存分配Batch的创建和释放问题和答案总结前言 在阅读本文之前, 希望你可
在阅读本文之前, 希望你可以思考一下下面几个问题, 带着问题去阅读文章会获得更好的效果。
kafka为了提高Producer客户端的发送吞吐量和提高性能,选择了将消息暂时缓存起来,等到满足一定的条件, 再进行批量发送, 这样可以减少网络请求,提高吞吐量。
而缓存这个消息的就是RecordAccumulator类.

上图就是整个消息存放的缓存模型,我们接下来一个个来讲解。

上图表示的就是 消息缓存的模型, 生产的消息就是暂时存放在这个里面。
那么创建ProducerBatch的时候,应该分配多少的内存呢?
先说结论: 当消息预估内存大于batch.size的时候,则按照消息预估内存创建, 否则按照batch.size的大小创建(默认16k).
我们来看一段代码,这段代码就是在创建ProducerBatch的时候预估内存的大小
RecordAccumulator#append
// 找到 batch.size 和 这条消息在batch中的总内存大小的 最大值
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
// 申请内存
buffer = free.allocate(size, maxTimeToBlock);假设当前生产了一条消息为M, 刚好消息M找不到可以存放消息的ProducerBatch(不存在或者满了),那么这个时候就需要创建一个新的ProducerBatch了
预估消息的大小 跟batch.size 默认大小16384(16kb). 对比,取最大值用于申请的内存大小的值。
那么, 这个消息的预估是如何预估的?纯粹的是消息体的大小吗?
DefaultRecordBatch#estimateBatchSizeUpperBound
预估需要的Batch大小,是一个预估值,因为没有考虑压缩算法从额外开销
static int estimateBatchSizeUpperBound(ByteBuffer key, ByteBuffer value, Header[] headers) {
return RECORD_BATCH_OVERHEAD + DefaultRecord.recordSizeUpperBound(key, value, headers);
}也就是说创建一个ProducerBatch,最少就要83B .
比如我发送一条消息 " 1 " , 预估得到的大小是 86B, 跟batch.size(默认16384) 相比取最大值。 那么申请内存的时候取最大值 16384 。
关于Batch的结构和消息的结构,我们回头单独用一篇文章来讲解。
我们都知道RecordAccumulator里面的缓存大小是一开始定义好的, 由buffer.memory控制, 默认33554432 (32M)
当生产的速度大于发送速度的时候,就可能出现Producer写入阻塞。
而且频繁的创建和释放ProducerBatch,会导致频繁GC, 所有kafka中有个缓存池的概念,这个缓存池会被重复使用,但是只有固定( batch.size)的大小才能够使用缓存池。
PS:以下16k指得是 batch.size的默认值.
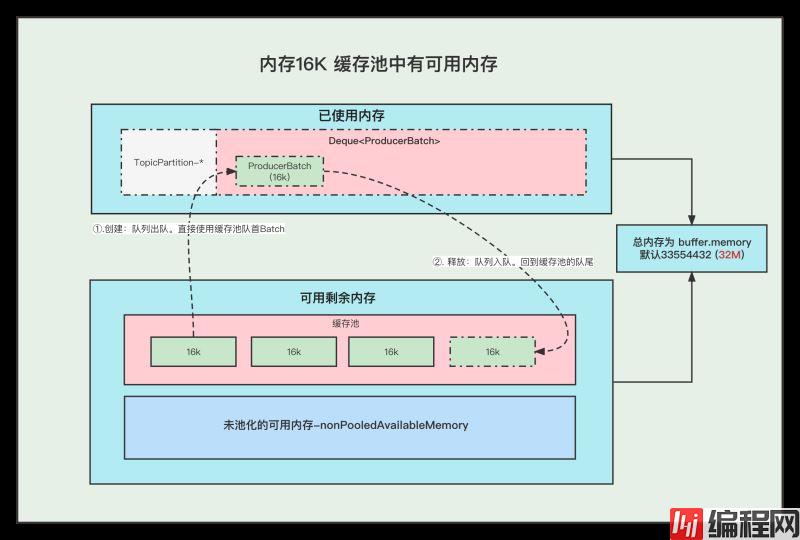
1. 内存16K 缓存池中有可用内存
①. 创建Batch的时候, 会去缓存池中,获取队首的一块内存ByteBuffer 使用。
②. 消息发送完成,释放Batch, 则会把这个ByteBuffer,放到缓存池的队尾中,并且调用ByteBuffer.clear 清空数据。以便下次重复使用
2. 内存16K 缓存池中无可用内存
①. 创建Batch的时候, 去非缓存池中的内存获取一部分内存用于创建Batch. 注意:这里说的获取内存给Batch, 其实就是让 非缓存池nonPooledAvailableMemory 减少 16K 的内存, 然后Batch正常创建就行了, 不要误以为好像真的发生了内存的转移。
②. 消息发送完成,释放Batch, 则会把这个ByteBuffer,放到缓存池的队尾中,并且调用ByteBuffer.clear 清空数据, 以便下次重复使用

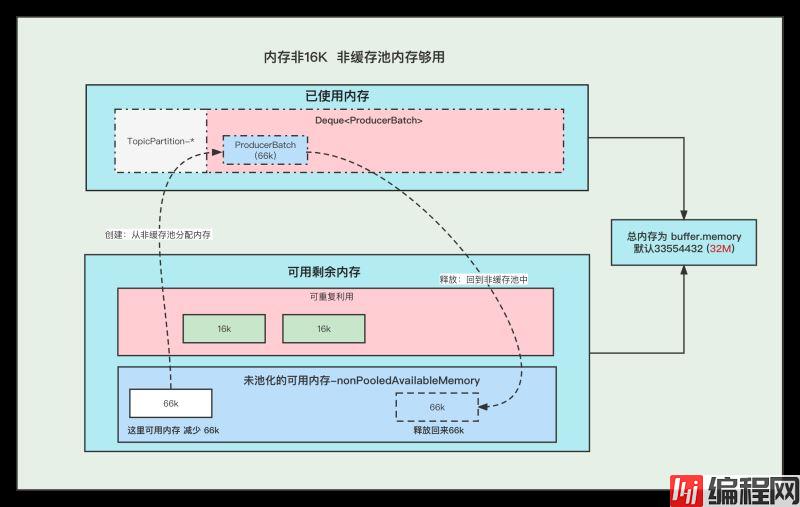
3. 内存非16K 非缓存池中内存够用
①. 创建Batch的时候, 去非缓存池(nonPooledAvailableMemory)内存获取一部分内存用于创建Batch. 注意:这里说的获取内存给Batch, 其实就是让 非缓存池(nonPooledAvailableMemory) 减少对应的内存, 然后Batch正常创建就行了, 不要误以为好像真的发生了内存的转移。
②. 消息发送完成,释放Batch, 纯粹的是在非缓存池(nonPooledAvailableMemory)中加上刚刚释放的Batch内存大小。 当然这个Batch会被GC掉
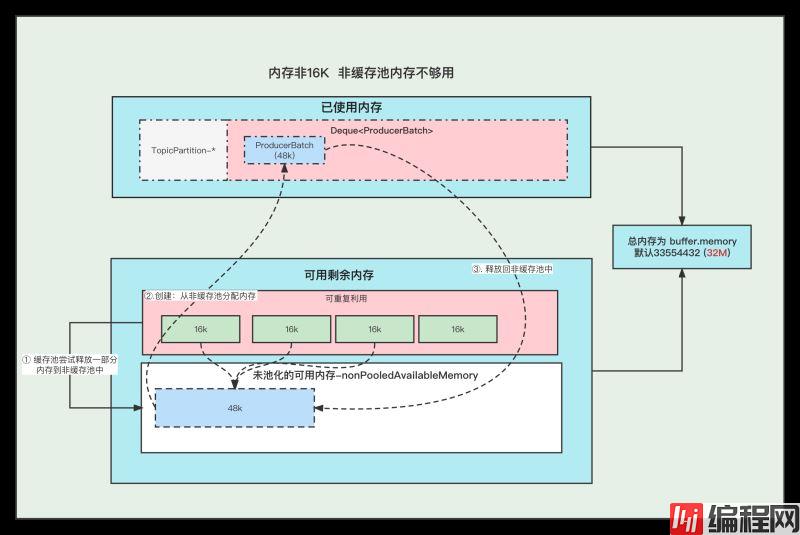
4. 内存非16K 非缓存池内存不够用
①. 先尝试将 缓存池中的内存一个一个释放到 非缓存池中, 直到非缓存池中的内存够用与创建Batch了
②. 创建Batch的时候, 去非缓存池(nonPooledAvailableMemory)内存获取一部分内存用于创建Batch. 注意:这里说的获取内存给Batch, 其实就是让 非缓存池(nonPooledAvailableMemory) 减少对应的内存, 然后Batch正常创建就行了, 不要误以为好像真的发生了内存的转移。
③. 消息发送完成,释放Batch, 纯粹的是在非缓存池(nonPooledAvailableMemory)中加上刚刚释放的Batch内存大小。 当然这个Batch会被GC掉
例如: 下面我们需要创建 48k的batch, 因为超过了16k,所以需要在非缓存池中分配内存, 但是非缓存池中当前可用内存为0 , 分配不了, 这个时候就会尝试去 缓存池里面释放一部分内存到 非缓存池。
释放第一个ByteBuffer(16k) 不够,则继续释放第二个,直到释放了3个之后总共48k,发现内存这时候够了, 再去创建Batch。
注意:这里我们涉及到的 非缓存池中的内存分配, 仅仅指的的内存数字的增加和减少。
发送消息的时候, 当Broker挂掉了,消息体还能写入到消息缓存中吗?
当Broker挂掉了,Producer会提示下面的警告⚠️, 但是发送消息过程中
这个消息体还是可以写入到 消息缓存中的,也仅仅是写到到缓存中而已。
WARN [Producer clientId=console-producer] Connection to node 0 (/172.23.164.192:9090) could not be established. Broker may not be available当最新的ProducerBatch还有空余的内存,但是接下来的一条消息很大,不足以加上上一个Batch中,会怎么办呢?
那么会创建新的ProducerBatch。
那么创建ProducerBatch的时候,应该分配多少的内存呢?
触发创建ProducerBatch的那条消息预估大小大于batch.size ,则以预估内存创建。
否则,以batch.size创建。
还有一个问题供大家思考:
当消息还存储在缓存中的时候, 假如Producer客户端挂掉了,消息是不是就丢失了?
到此这篇关于Kafka Producer中消息缓存模型的文章就介绍到这了,更多相关Kafka Producer消息缓存模型内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Kafka Producer中的消息缓存模型图解详解
本文链接: https://www.lsjlt.com/news/146085.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0