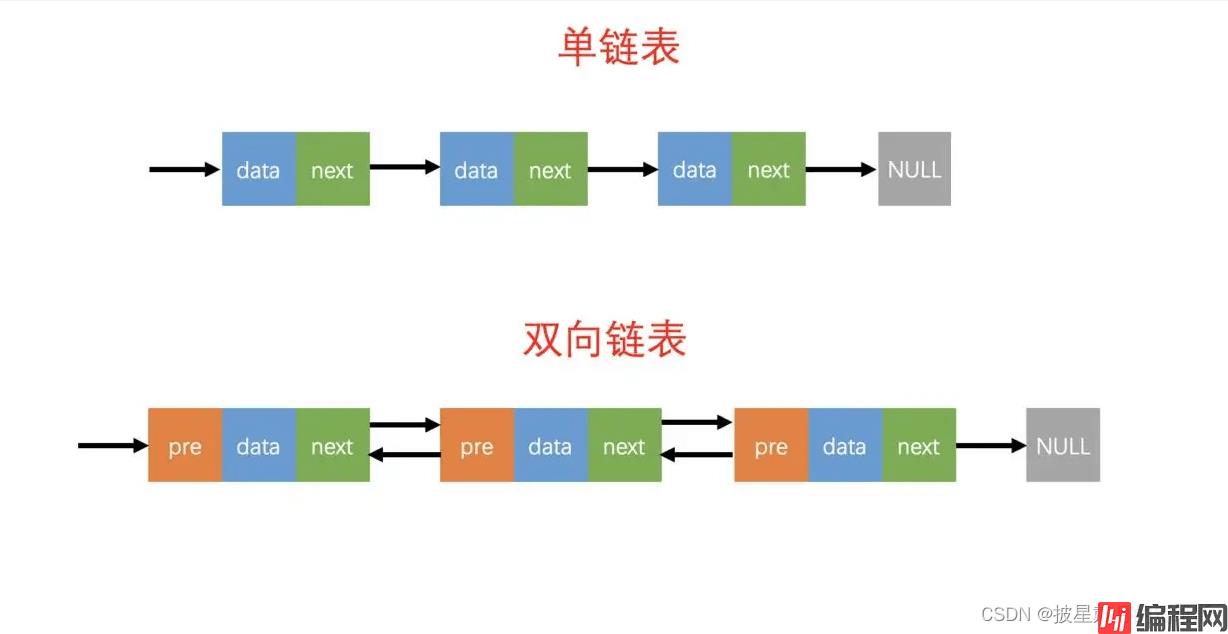
目录一、双向链表的概念二、双向链表的实现三、链表与顺序表的差别四、链表oj总结一、双向链表的概念 1、概念:概念:双向链表是每个结点除后继指针外还有⼀个前驱指针。双向链表也有带头结点
1、概念:概念:双向链表是每个结点除后继指针外还有⼀个前驱指针。双向链表也有带头结点结构和不带头结点结构两种,带头结点的双向链表更为常用;另外,双向链表也可以有循环和非循环两种结构,循环结构的双向链表更为常用。
头文件List.h
#pragma once
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
typedef int LTDateType;
typedef struct Listnode
{
LTDateType date;
struct ListNode* next;
struct ListNode* prev;
}LTNode;
//void ListInit(LTNode** pphead);
void ListPrint(LTNode* phead);
void ListPopBack(LTNode* phead);
LTNode* ListInit();//初始化
LTNode* BuyLTNode(LTDateType x);
void ListPushBack(LTNode* phead, LTDateType x);
void ListPushFront(LTNode* phead, LTDateType x);
void ListPopFront(LTNode* phead);
LTNode* ListFind(LTNode* phead, LTDateType x);
//在pos前插入
void ListInsert(LTNode* pos, LTDateType x);
//删除pos位置的节点
void ListErease(LTNode* pos);
void ListDestory(LTNode* phead);源文件List.C
#include"List.h"
LTNode* BuyLTNode(LTDateType x)
{
LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));
if (newnode == NULL)
{
printf("malloc fail\n");
exit(-1);
}
newnode->date = x;
newnode->next = NULL;
newnode->prev = NULL;
return newnode;
}
//void ListInit(LTNode** pphead)
//{
// assert(pphead);
// *pphead = BuyLTNode(0);
// (*pphead)->next = *pphead;
// (*pphead)->prev = *pphead;
//}
LTNode* ListInit()
{
LTNode* phead = BuyLTNode(0);
phead->next = phead;
phead->prev = phead;
return phead;
}
void ListPrint(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
printf("%d ", cur->date);
cur = cur->next;
}
printf("\n");
}
void ListPushBack(LTNode* phead, LTDateType x)
{
assert(phead);
LTNode* tail = phead->prev;
LTNode* newnode = BuyLTNode(x);
tail->next = newnode;
newnode->prev = tail;
newnode->next = phead;
phead->prev = newnode;
}
void ListPushFront(LTNode* phead, LTDateType x)
{
assert(phead);
ListInsert(phead->next, x);
}
void ListPopBack(LTNode* phead)//尾删
{
assert(phead);
assert(phead->next != phead);//说明传进来的不只有phead,不然phead被free掉了。
//LTNode* tail = phead->prev;
//LTNode* tailPrev = tail->prev;
//free(tail);
//tail = NULL;
//tailPrev->next = phead;
//phead->prev = tailPrev;
ListErease(phead->prev);
}
void ListPopFront(LTNode* phead)//头删
{
assert(phead);
assert(phead->next != phead);
ListErease(phead->next);
}
LTNode* ListFind(LTNode* phead, LTDateType x)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
if (cur->date == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
//void ListInsert(LTNode* pos, LTDateType x)
//{
// assert(pos);
// LTNode* newnode = BuyLTNode(x);
// pos->prev->next = newnode;
// newnode->prev = pos->prev;
//
// pos->prev = newnode;
// newnode->next = pos;
//
//}
//更好的写法
void ListInsert(LTNode* pos, LTDateType x)
{
assert(pos);
//无关写的顺序
LTNode* newnode = BuyLTNode(x);
LTNode* posPrev = pos->prev;
newnode->next = pos;
pos->prev = newnode;
posPrev->next = newnode;
newnode->prev = posPrev;
}
// 驼峰法
//函数和类型所以单词首字母大写
//变量:第一个单词小写后续单词首字母大写
void ListErease(LTNode* pos)
{
assert(pos);
LTNode* prev = pos->prev;
LTNode* next = pos->next;
free(pos);
//此时要把pos置成空,不然pos就是野指针了
pos = NULL;
prev->next = next;//LT的新的prev指向pos->next;
next->prev = prev;//LT的新的next的prev指向prev;
}
void ListDestory(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;//从头结点的下一个位置开始。
while (cur != phead)
{
LTNode* next = cur->next;//先记录,再free
//ListErease(cur);//副用Erease函数实现destory
free(cur);//
cur = next;
}
free(phead);
//phead = NULL;形参的改变不影响实参
}| 不同点 | 顺序表 | 链表 |
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定连 续 |
| 随机访问 | 支持O(1) | 不支持:O(N) |
| 任意位置插入或者删除元 素 | 可能需要搬移元素,效率低O(N) | 只需修改指针指向 |
| 插入 | 动态顺序表,空间不够时需要扩容 | 没有容量的概念 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置插入和删除频繁 |
| 缓存利用率 | 高 | 低 |
1、链表中倒数第k个结点_牛客题霸_牛客网(链接)
思路:快慢指针法,fast先走k步, slow和fast同时走, fast走到尾时,slow就是倒数第k个
代码示例:
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k ) {
struct ListNode* slow, *fast;
slow = fast = pListHead;
while(k --)//走k步
{
//判断K是否大于链表的长度。
if(fast == NULL) return NULL;
fast = fast->next;
}
while(fast)//当fast 指针走到尾时
{
slow = slow->next;
fast = fast->next;
}
return slow;
}
第二种写法:
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k )
{
struct ListNode* p1 = NULL, *p2 = NULL;
p1 = pListHead;
p2 = pListHead;
int a = k;
int c = 0;//记录节点个数
//p1指针先跑,并且记录节点数,当p1指针跑了k-1个节点后,p2指针开始跑,
//当p1指针跑到最后时,p2所指指针就是倒数第k个节点
while(p1)//当p1 不为空时
{
p1 = p1->next;
c ++;//节点个数增加
if(k < 1) p2 = p2->next;
k --;
}
if(c < a) return NULL;
return p2;
}2、21. 合并两个有序链表(链接)
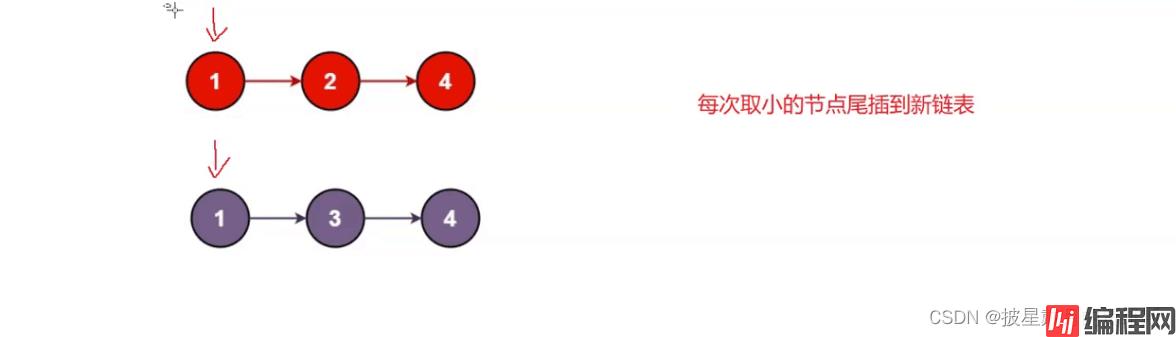
思路:归并的思想,将小的值尾插到新链表。时间复杂度为n^2;如果再定义一个尾指针, 每次记录尾。
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{
if(list1 == NULL)//list1和list2分别是两个链表的头指针
return list2;
if(list2 == NULL)
return list1;
struct ListNode* head = NULL, *tail = NULL;//head是新链表的头指针,tail是新链表的尾指针
while(list1 && list2)
{
if(list1->val < list2->val)
{
if(tail == NULL)//这一步不太理解
{
head = tail = list1;
}
else
{
tail->next = list1;//先传指针指向
tail = list1;//再把list 的地址传给tail,相当于tail往前挪了一步。
}
list1 = list1->next;
}
else
{
if(tail == NULL)
{
head = tail = list2;
}
else
{
tail->next = list2;
tail = list2;//传地址
}
list2 = list2->next;
}
}
if(list1)
{
tail->next = list1;//如果链表1不为空,而此时链表二为空,则直接把链表二的值连接过去就好了。
}
if(list2)
{
tail->next = list2;
}
return head;
}
//方法二:设置一个哨兵位头结点
//head存随机值, head->next存第一个链表的值。起到简化代码的作用。
//一般的链表没有设置哨兵位头结点。
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{
struct ListNode* head = NULL, *tail = NULL;
head = tail = (struct ListNode*)malloc(sizeof(struct ListNode));
head->next = NULL;
while(list1 && list2)
{
if(list1->val < list2->val)
{
tail->next = list1;//先传指针指向
tail = list1;//再把list 的地址传给tail,相当于tail往前挪了一步。
list1 = list1->next;
}
else
{
tail->next = list2;
tail = list2;//传地址
list2 = list2->next;
}
}
if(list1)
{
tail->next = list1;//如果链表1不为空,而此时链表二为空,则直接把链表二的值连接过去就好了。
}
if(list2)
{
tail->next = list2;
}
//解决内存泄漏问题;
struct ListNode* list = head->next;
free(head);
return list;
}3、链表分割_牛客题霸_牛客网(链接)
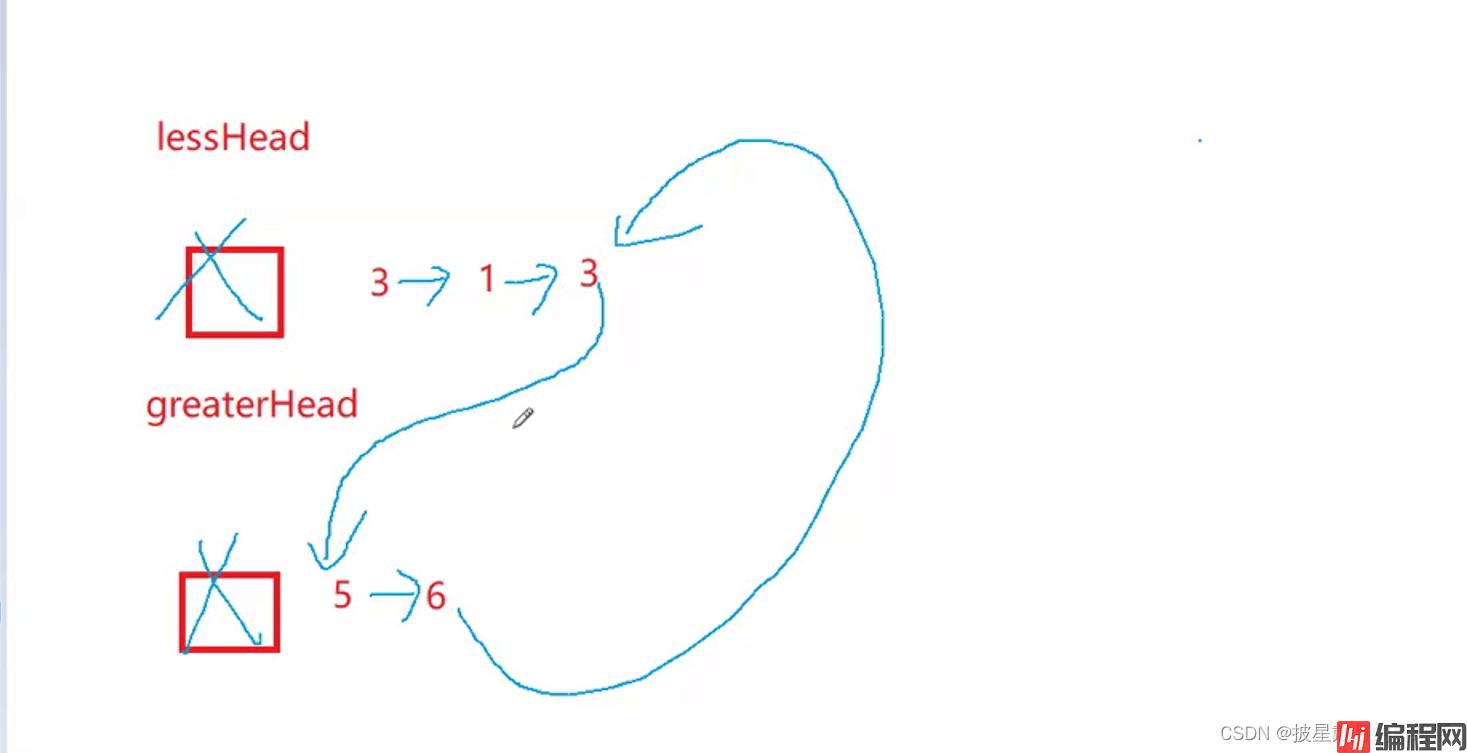
思路:新设置两个链表,小于x的插到第一个链表,大于x的插到第二个链表。

定义四个指针:Lesshead, LessTail,GreatHead, GreatTail.
原链表的值分别尾插到这两个链表, 然后分别更新LessTail,和GreatTail;
最后LessTail的指针再指向GreatHead。完成两个链表的连接。
想极端场景:
1、所有值比x小
2、所有值比x大
3、比x大和小都有,最后一个值是比x小
4、比x大和小都有,最后一个值是比x大
//构成环链表,造成死循环。
//设置哨兵位
class Partition {
public:
ListNode* partition(ListNode* pHead, int x) {
struct ListNode* lessHead, *lessTail, *greatHead, *greatTail;
lessHead = lessTail = (struct ListNode*)malloc(sizeof(struct ListNode));
greatHead = greatTail = (struct ListNode*)malloc(sizeof(struct ListNode));
lessTail->next = greatTail->next = NULL;
struct ListNode* cur = pHead;
while (cur) {
if (cur->val < x) {
lessTail->next = cur;
lessTail = lessTail->next;
} else {
greatTail->next = cur;
greatTail = greatTail->next;
}
cur = cur->next;
}
//完成链接工作
lessTail->next = greatHead->next;
greatTail->next = NULL;//切断greetTail的最后与greetHead的链接
struct ListNode* list = lessHead->next;
free(lessHead);
free(greatHead);
return list;
}
};4、链表的回文结构_牛客题霸_牛客网(链接)
思路:找出链表的中间节点, 然后逆置,判断前后链表是否一致,若一致,则说明该链表是回文结构。
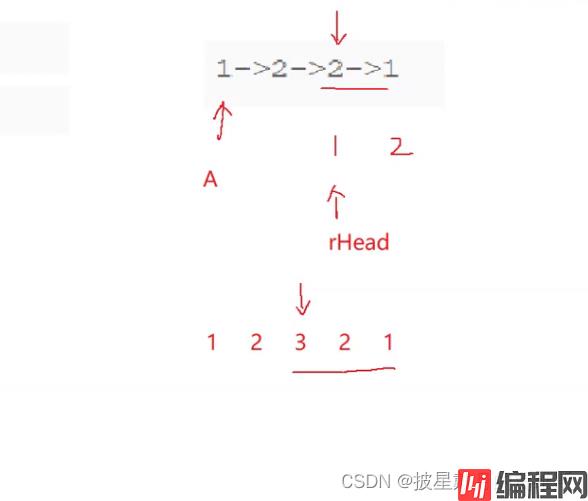
为什么奇数个时也能过,
例如:1 2 3 2 1
逆置完变为了 1 2 1 2 3 ;
当A走到2的位置时2->next = 3, rHead走到的 2->next = 3, 相等。
class PalindromeList {
public:
struct ListNode* middleNode(struct ListNode* head)
{
struct ListNode* slow, * fast;
slow = fast = head;
while(fast && fast->next) //想的是结束的条件,写的是继续的条件
{
slow = slow->next;
fast = fast->next->next;
}
return slow;
}
struct ListNode* reverseList(struct ListNode* head)
{
struct ListNode* NewHead = NULL;
struct ListNode* cur = head;
while(cur)
{
struct ListNode* next = cur->next;
//头插
cur->next = NewHead;//更多代表链表的指向方向。
NewHead = cur;//接着把地址传过来(更新)
cur = next;//(更新)
}
return NewHead;
}
bool chkPalindrome(ListNode* A) {
struct ListNode* mid = middleNode(A);
struct ListNode*rHead = reverseList(mid);//应该逆置mid,中间结点。
while(A && rHead)
{
if(A->val == rHead->val)
{
A = A->next;
rHead = rHead->next;
}
else
{
return false;
}
}
return true;
}
};5、力扣相交链表(链接)
思路1:A链表每个节点B跟链表依次比较,如果有相等,就是相交,第一个相等就是交点。
时间复杂度:o(N*M);
思路二:如果两个链表相交,则这两个链表的最后一个元素的地址相同。
包含思路二三:
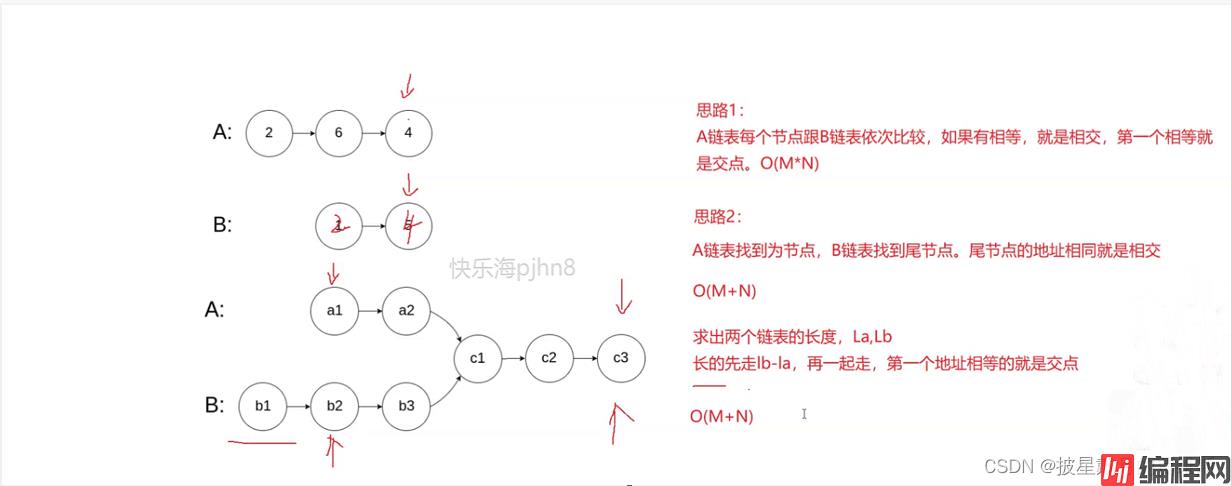
代码示例:
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB)
{
struct ListNode* tailA, *tailB;//因为之后还要用到headA,和headB,所以要用tail来进行迭代。
tailA = headA, tailB = headB;
int lenA = 1, lenB = 1;
while(tailA)//求出A的尾
{
tailA = tailA->next;
++lenA;//求出A的长度
}
while(tailB)//求出链表B的尾
{
tailB = tailB->next;
++lenB;//求出B的长度
}
if(tailA != tailB)//如果两个链表的尾不相等,则返回空
{
return NULL;
}
//相交,求交点,长的先走差距步,再同时找交点。
struct ListNode* shortList = headA, *longList = headB;//默认A短B长
if(lenA > lenB)
{
shortList = headB;
longList = headA;
}
int gap = abs(lenA - lenB);//求出差距
while(gap--)//减gap次,若是--gap,就是减了gap - 1次
{
longList = longList->next;
}
while(shortList && longList)
{
if(shortList == longList)
return shortList;//此时shortList == longList;
longList = longList->next;
shortList = shortList->next;
}
//最最关键的一步:就是要在外面返回一个值,因为编译器不会判断代码在哪返回,只会检查你的代码的语法问题。
return NULL;
}本文分别从双向链表的概念、实现,还比较了顺序表和链表的区别,以及5道链表oj题四个方面介绍了链表进阶的知识,希望大家读后能够有所收获。
到此这篇关于C语言超详细i讲解双向链表的文章就介绍到这了,更多相关C语言双向链表内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: C语言超详细i讲解双向链表
本文链接: https://www.lsjlt.com/news/149800.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0