Python 官方文档:入门教程 => 点击学习
目录前言环境建设正式开始configureScanner第一段代码第二段代码第三段代码第四段代码parseTypeFiltersdoScanfindCandidateComponen
在上一章节spring和mybatis整合的原理详解中有写到Spring和MyBatis整合时用到的Bean扫描是Spring本身提供的。这一篇文章就写到Spring是如何实现Bean扫描的。
不得不说Bean扫描是一个很重要的技术,在springMVC中的Controller扫描,和SpringBoot中的Bean扫描,Component扫描,Configuration扫描,原理我这里猜测都是由这个实现的。
由于创建包扫描的条件很简单,只要在Xml中配置一个属性即可。

在我前面的文章的阅读基础,我们直接这里节省时间,直接定位到ComponentScanBaeanDefinitionParser类中的parse方法。
@Override
@Nullable
public BeanDefinition parse(Element element, ParserContext parserContext) {
String basePackage = element.getAttribute(BASE_PACKAGE_ATTRIBUTE);
basePackage = parserContext.getReaderContext().getEnvironment().resolvePlaceholders(basePackage);
String[] basePackages = StringUtils.tokenizeToStringArray(basePackage,
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
// Actually scan for bean definitions and reGISter them.
// 实际上,扫描bean定义并注册它们。
ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element);
Set<BeanDefinitionHolder> beanDefinitions = scanner.doScan(basePackages);
registerComponents(parserContext.getReaderContext(), beanDefinitions, element);
return null;
}
这个代码的前半部分比较简单,就是可能当前传进来的basePackage可能是多个,所以这里使用方法去处理这个字符串。比较重要的代码在下半部分。
也就是三个方法:
boolean useDefaultFilters = true;
if (element.hasAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE)) {
useDefaultFilters = Boolean.parseBoolean(element.getAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE));
}
这一段声明了个变量,默认为True,在下方的If中去会去修改这个值。由于我们在applicatio.xml中没有设置这个属性,这里还是默认值。
// Delegate bean definition registration to scanner class.
// 将 bean 定义注册委托给扫描程序类。
ClassPathBeanDefinitionScanner scanner = createScanner(parserContext.getReaderContext(), useDefaultFilters);
scanner.setBeanDefinitionDefaults(parserContext.getDelegate().getBeanDefinitionDefaults());
scanner.setAutowireCandidatePatterns(parserContext.getDelegate().getAutowireCandidatePatterns());
createScanner方法中,就是new了一个ClassPathBeanDefinitionScanner对象给返回回来了。 随后又为该扫描器加入了两个属性。
if (element.hasAttribute(RESOURCE_PATTERN_ATTRIBUTE)) {
scanner.setResourcePattern(element.getAttribute(RESOURCE_PATTERN_ATTRIBUTE));
}
这里判断有无配置ResourcePattern属性,有的话设置。
try {
parseBeanNameGenerator(element, scanner);
}
catch (Exception ex) {
// ...
}
try {
parseScope(element, scanner);
}
catch (Exception ex) {
// ...
}这两个方法代码跟进去有个共性。都是判断有没有配置一个属性,然后给sanner设置属性,具体看下方代码截图。

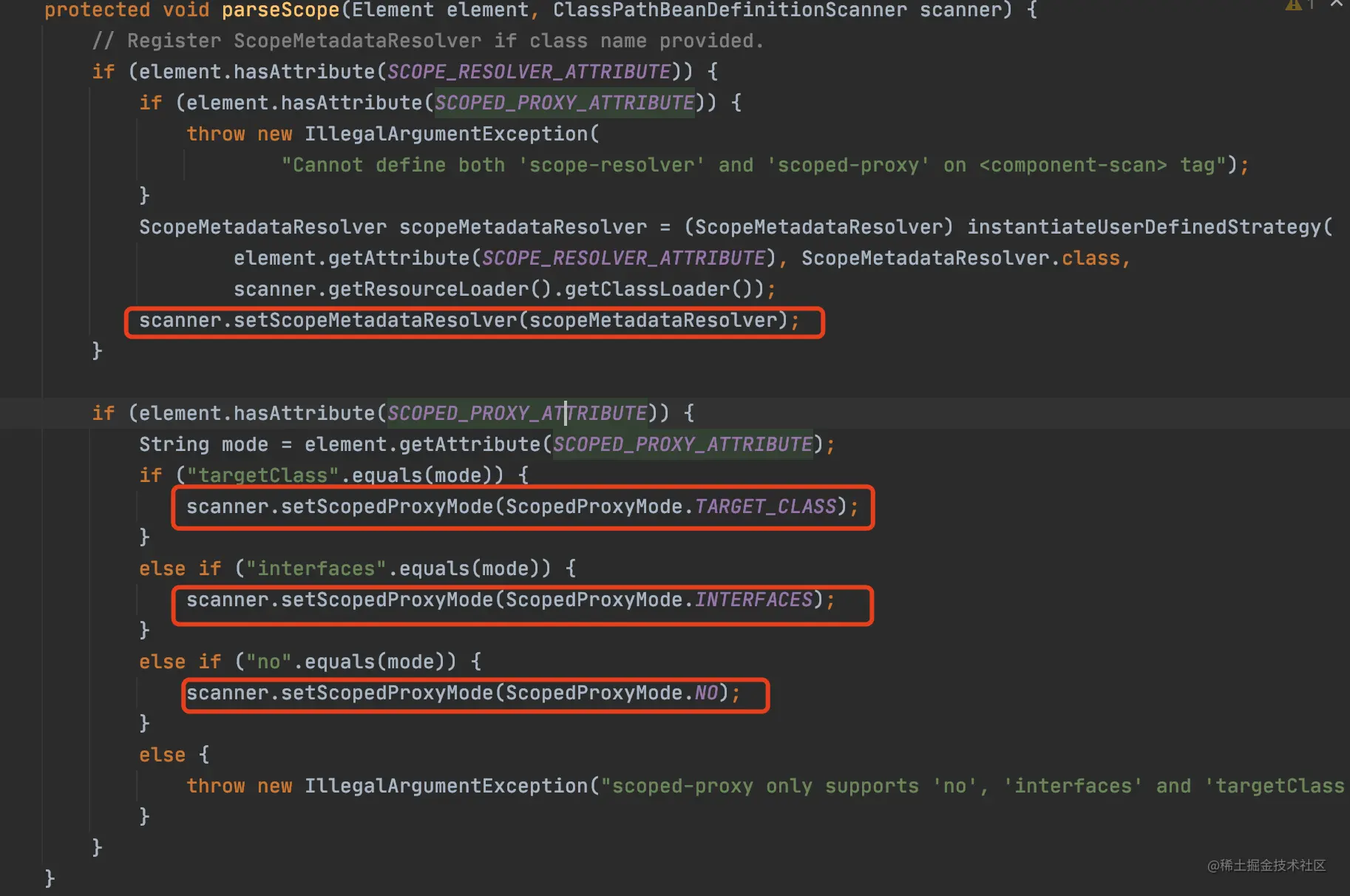
这里这两个方法是干嘛的,我心里想了想,不知道,也不知道在什么地方会用到,所以这里接着往下看。
protected void parseTypeFilters(Element element, ClassPathBeanDefinitionScanner scanner, ParserContext parserContext) {
// Parse exclude and include filter elements.
ClassLoader classLoader = scanner.getResourceLoader().getClassLoader();
nodeList nodeList = element.getChildNodes();
for (int i = 0; i < nodeList.getLength(); i++) {
Node node = nodeList.item(i);
if (node.getNodeType() == Node.ELEMENT_NODE) {
String localName = parserContext.getDelegate().getLocalName(node);
try {
if (INCLUDE_FILTER_ELEMENT.equals(localName)) {
TypeFilter typeFilter = createTypeFilter((Element) node, classLoader, parserContext);
scanner.addIncludeFilter(typeFilter);
}
else if (EXCLUDE_FILTER_ELEMENT.equals(localName)) {
TypeFilter typeFilter = createTypeFilter((Element) node, classLoader, parserContext);
scanner.addExcludeFilter(typeFilter);
}
}
catch (ClassNotFoundException ex) {
// ...
}
catch (Exception ex) {
// ...
}
}
}
}
首先看这个方法名parseTypeFilters,转换类型类型过滤器。
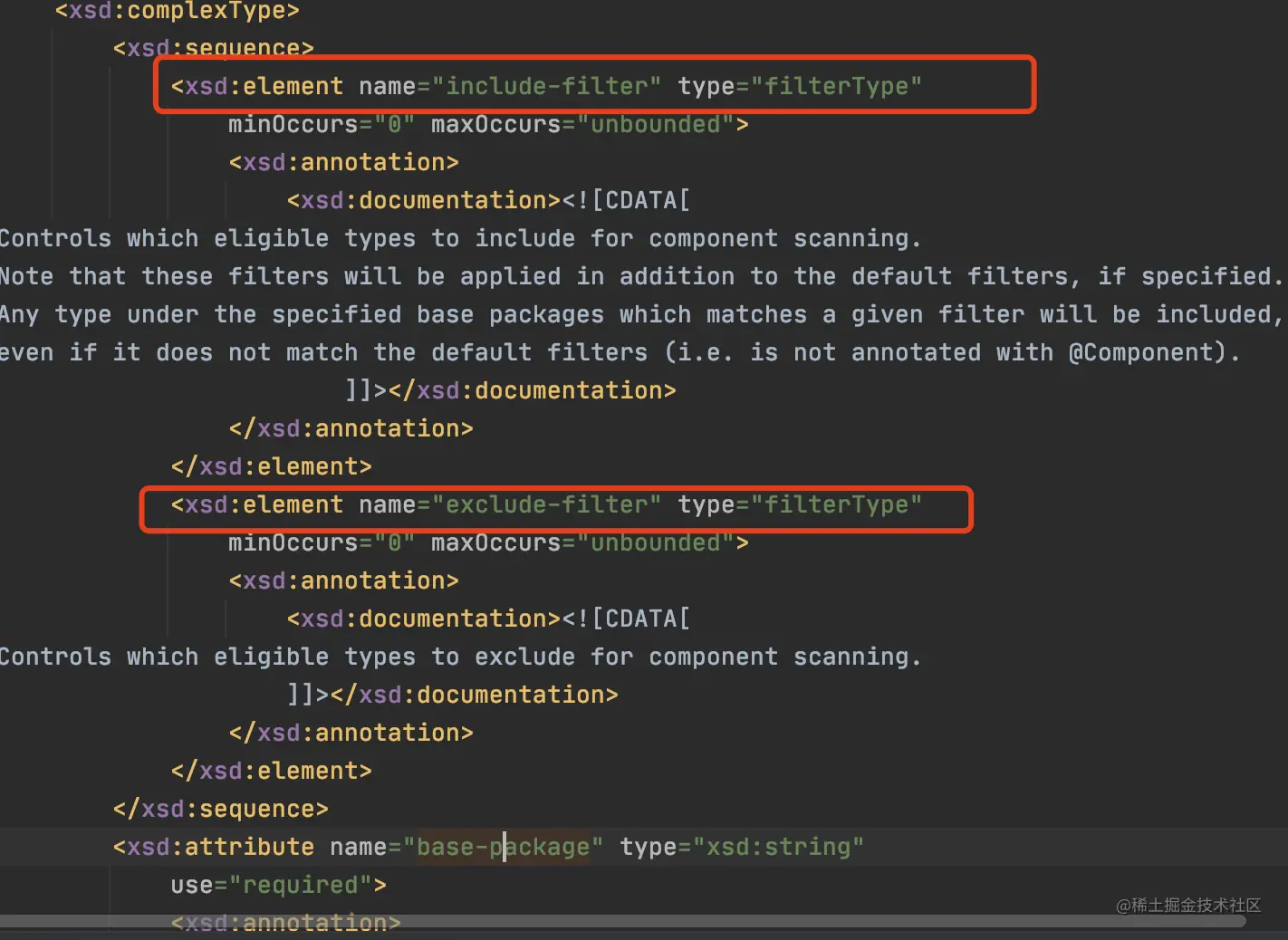
通过查看Spring的DTD文件,看到component-scan标签下还有两个子标签,想必就是对应上方的代码中解释了。
随后该方法运行完后,就把创建好的scanner对象,给返回回去了。
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
在第一行代码中,创建了个BeanDefinitions的Set,大概是用来存放结果的。
随后根据basePacage,查找到了所有的候选BeanDefinition,至于获取的方法我在下方有讲到。
随后遍历了刚刚获取到的BeanDefinition。
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
// ...
for (Resource resource : resources) {
// ... 暂时不看
}
}
catch (IOException ex) {
// ... throw
}
return candidates;
}
上面一段代码,方法一进入,创建了一个set集合,这个set机会也就是方法最后的返回值,后续的代码中会向这个set去追加属性。
随后到了packageSearchPath,这里是通过拼接字符串的方式最终得到这个变量,拼接规则如下:
classpath*: + 转换后的xml路径 + ***.class
随后根据resourceLoader,可以加载上方路径下的所有class文件。
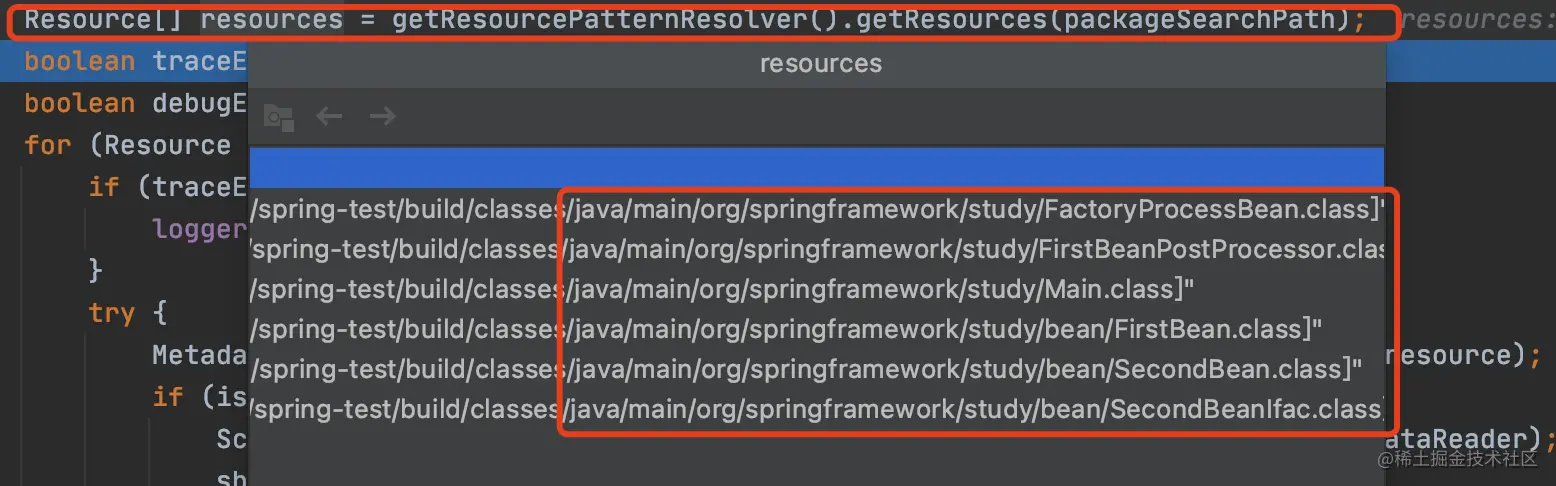
随后进入For遍历环节。
当前的resource资源也就是读取到的class文件。
for (Resource resource: resources) {
try {
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
// ... 打印日志
candidates.add(sbd);
}
else {
// ... 打印日志
}
}
else {
// ... 打印日志
}
}
catch (FileNotFoundException ex) {
// ... 打印日志
}
catch (Throwable ex) {
// ... throw
}
}
进入For后,首先获取metadataReader。这里代码简单追一下。


主要做的是两件事,一个new了一个SimpleMetaDataReader。然后把这个MetaDataReader放入了缓存中。随后返回了这个Reader对象。
然后就进入了第一个比较关键的方法代码,isCandidateComponent方法,仔细一看,这个方法怎么被调用了两次,因为这个if进入后还会调用isCandidateComponent方法,然后我看了看入参,不一致,一个入参事Reader,一个入参事BeanDefinition。我们第一个if中点用的Reader的isCandidateComponent方法。
protected boolean
isCandidateComponent(MetadataReader metadataReader) throws IOException {
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return false;
}
}
for (TypeFilter tf : this.includeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return isConditionMatch(metadataReader);
}
}
return false;
}
上方的excludeFilters排除的我们不用看,主要是看下方的include

后续的代码我就不读了,大概实现我猜测是通过Reader去读到类上的注解,看看有没有当前filter中设置的注解。有的话返回true。
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
刚刚外层的If为True后,这里会创建一个ScannedGenericBeanDefinition,既然是BeanDefinition,那就可以被Spring加载。
后面把创建的BeanDefinition放入了isCandidateComponent方法。
protected boolean isCandidateComponent(AnnotatedBeanDefinition beanDefinition) {
AnnotationMetadata metadata = beanDefinition.getMetadata();
return (metadata.isIndependent() && (metadata.isConcrete() ||
(metadata.isAbstract() && metadata.hasAnnotatedMethods(Lookup.class.getName()))));
}
@Override
public boolean isIndependent() {
// enclosinGClassName 为 null
return (this.enclosingClassName == null || this.independentInnerClass);
}
default boolean isConcrete() {
return !(isInterface() || isAbstract());
}
到这个方法基本第一个判断就返回了。isIndependent方法中一开始看到其中的两个单词我有点懵,enclosingClass和innerClass,可能是我英文不好的缘故或者基础差吧,百度搜了才知道的。我这里就不讲了,有兴趣你们可以自己搜索一下。自己搜索的记忆更深刻。只要是普通的Component的时候,这里为True。
至于下民的isConcrete方法,就是判断一下当前类是不是接口,或者抽象类。很明显如果是正常的Component,这里是false,随后取反为True。
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
当把BeanDefinition传入后返回为True,进入If,也就是添加当前的BeanDefinition进入结果集,返回结果集。
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
把刚刚获取到BeanDefinition拿出来遍历.
第一步获取MetaData,这个在刚刚的代码中有写到。随后把他的ScopeName赋值给了MetaData。
接下来有两个if是对这个BeanDefinition设置一些参数的。可以简单扫一眼。捕捉一些关键信息即可。

这个里面设置一个属性,这里记录一下,后面有用到再看。
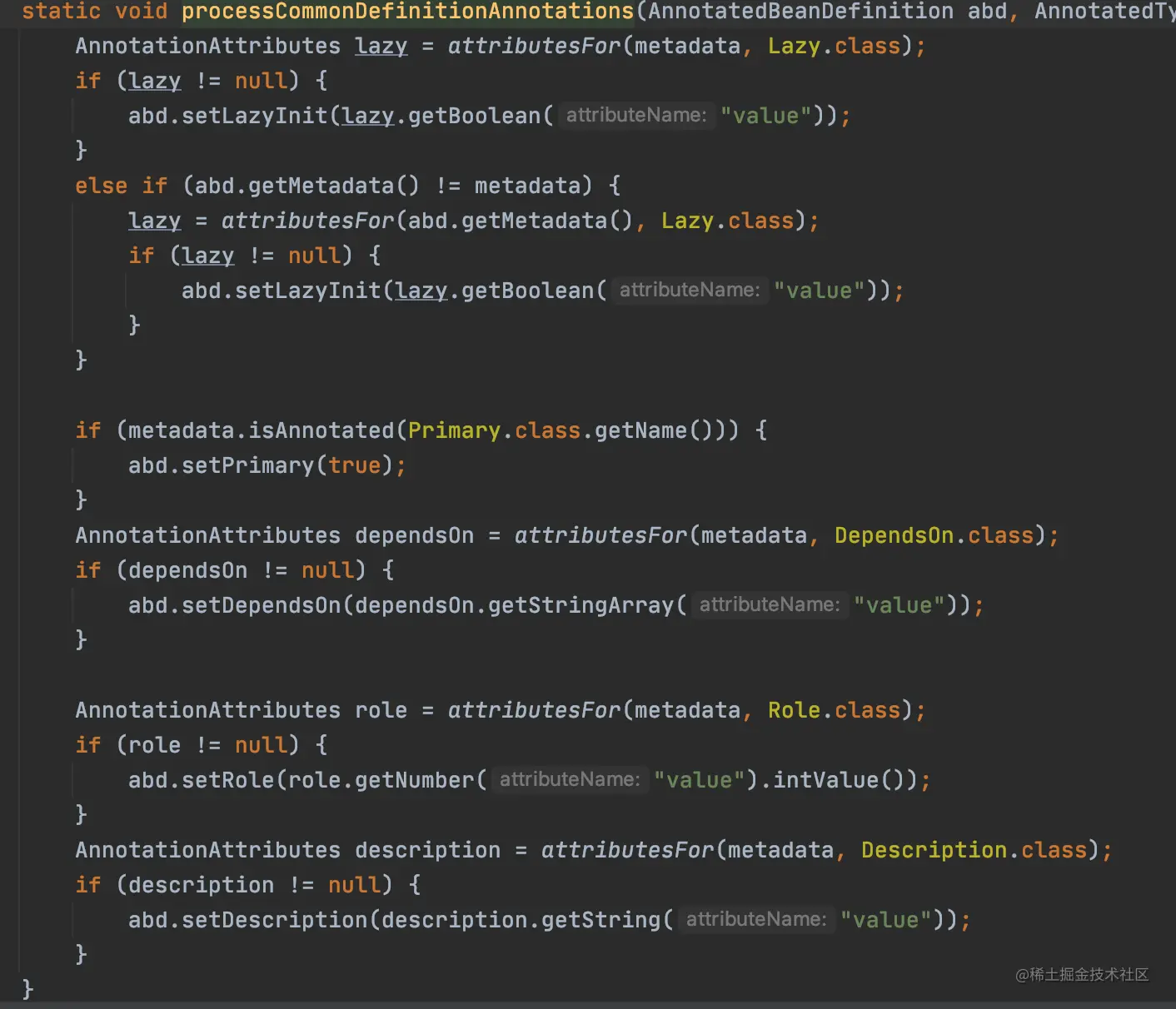
这个里面是针对类里添加的一些别的注解,来给BeanDefinition添加一些配置。看到几个比较眼熟的,Lazy,Primary,Description这些注解比较眼熟。
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
粗略的扫一眼,这里可以看几个重要的地方,一个是进入If的条件,注册BeanDefinition。
至于applyScopedProxyMode方法,因为我没的类上没有加Scope注解,所以这里都是不会配置代理。也就是直接返回当前传入的BeanDefinition。
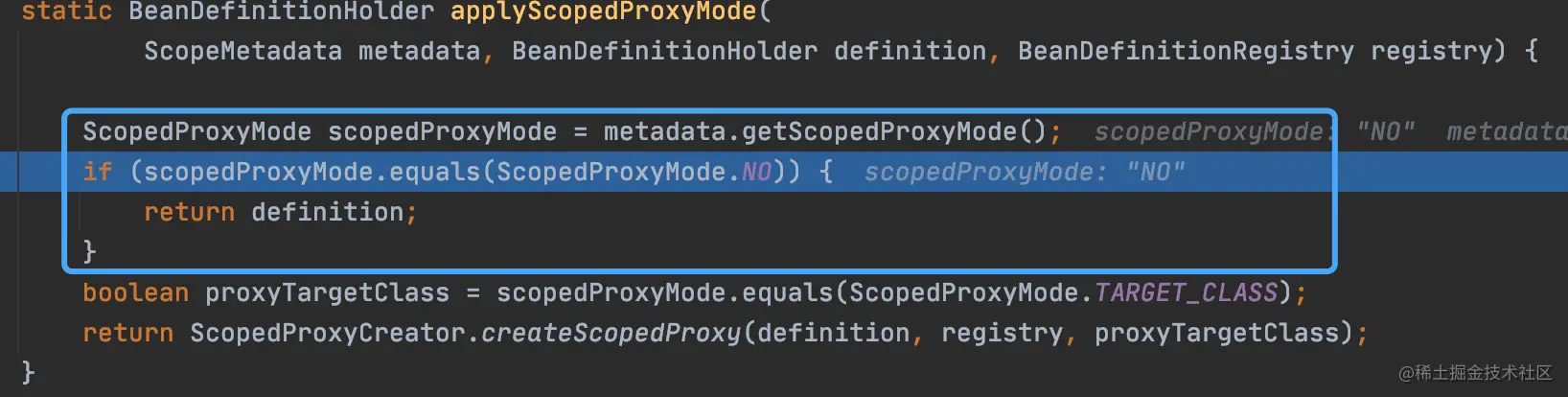
protected boolean checkCandidate(String beanName, BeanDefinition beanDefinition) throws IllegalStateException {
if (!this.registry.containsBeanDefinition(beanName)) {
return true;
}
BeanDefinition existingDef = this.registry.getBeanDefinition(beanName);
BeanDefinition originatingDef = existingDef.getOriginatingBeanDefinition();
if (originatingDef != null) {
existingDef = originatingDef;
}
if (isCompatible(beanDefinition, existingDef)) {
return false;
}
// ... throw Exception.
}
因为是通过Bean扫描进入的,也就是BeanDefinitionRegister当中是没有这个BeanDefinition的。所以这里直接就返回True,不会有走到下面的机会。
这个时候大家可以思考一下,如果走到下面了会怎么样。欢迎评论区讨论。
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
接下来就去registerBeanDefinition了,然后还把registry传进入了方法,那很明显了。这里是去注册BeanDefinition了。

由于在这个环节,扫描器把BeanDefinition放进Registry,那么在之后的Refresh方法中的finishBeanFactoryInitialization方法就会把BeanDefinition都实例化完毕。
到此这篇关于Spring中Bean扫描原理详情的文章就介绍到这了,更多相关Spring Bean扫描原理内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Spring中Bean扫描原理详情
本文链接: https://www.lsjlt.com/news/153540.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0