Python 官方文档:入门教程 => 点击学习
目录概述RNN权重共享计算过程LSTM阶段数据介绍代码预处理主函数概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的
从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁.

RNN (Recurrent Neural Network), 即循环神经网络. RNN 相较于 CNN, 可以帮助我们更好的处理序列信息, 挖掘前后信息之间的联系. 对于 NLP 这类的任务, 语料的前后概率有极大的联系. 比如: “明天天气真好” 的概率 > “明天天气篮球”.

传统神经网络:
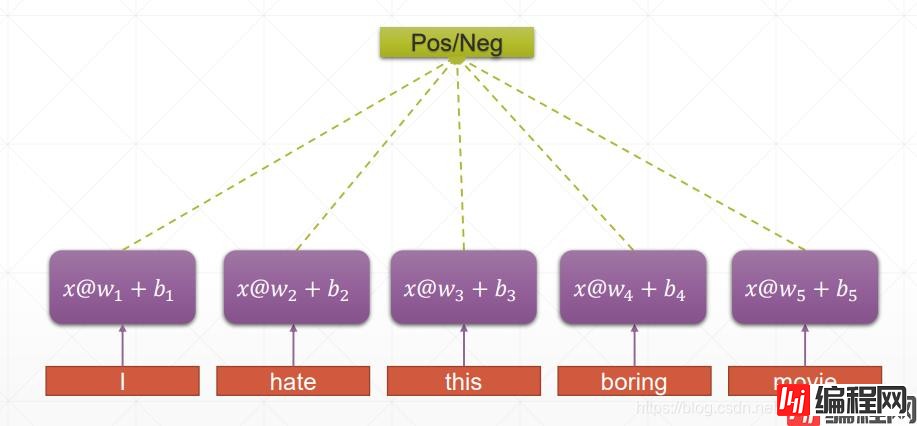
RNN:

RNN 的权重共享和 CNN 的权重共享类似, 不同时刻共享一个权重, 大大减少了参数数量.
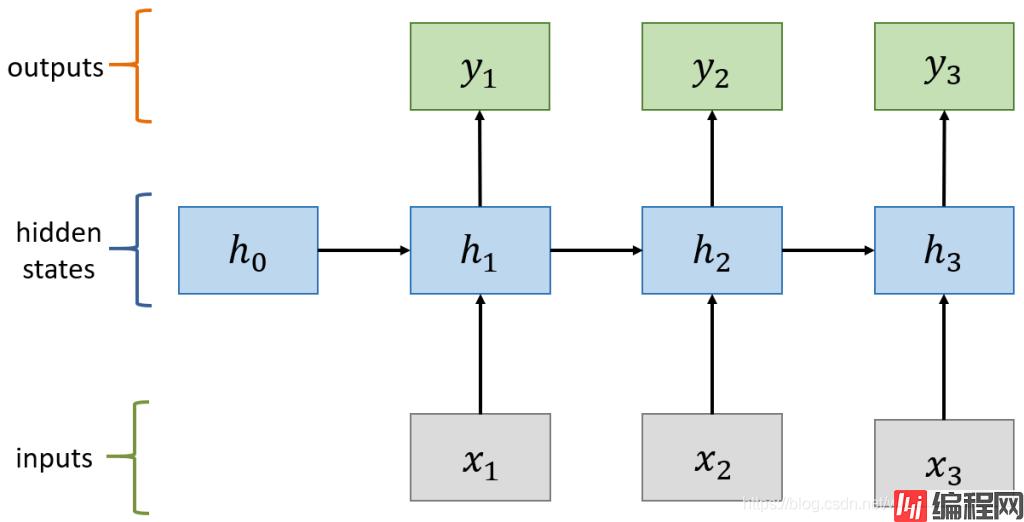
计算状态 (State)
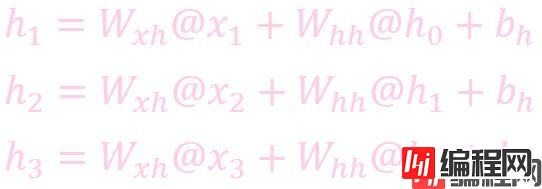
计算输出:
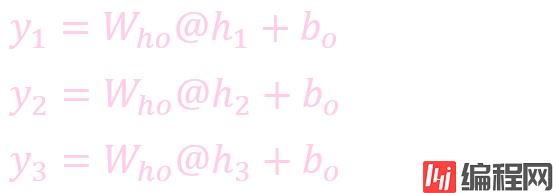
LSTM (Long Short Term Memory), 即长短期记忆模型. LSTM 是一种特殊的 RNN 模型, 解决了长序列训练过程中的梯度消失和梯度爆炸的问题. 相较于普通 RNN, LSTM 能够在更长的序列中有更好的表现. 相比 RNN 只有一个传递状态 ht, LSTM 有两个传递状态: ct (cell state) 和 ht (hidden state).
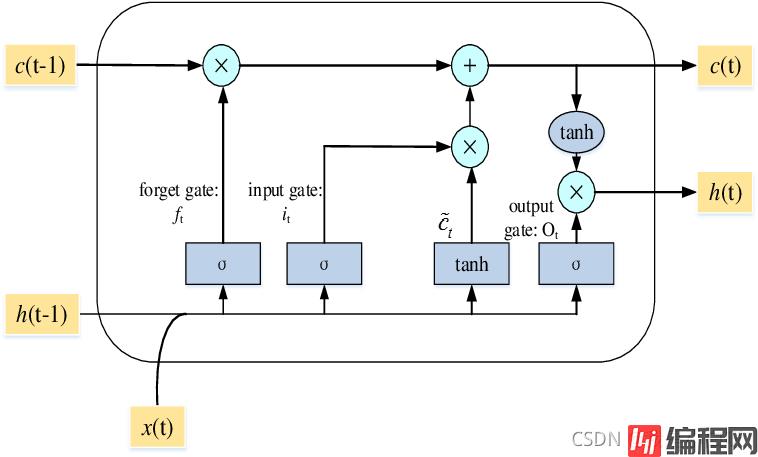
LSTM 通过门来控制传输状态。
LSTM 总共分为三个阶段:
约 3 万条评论数据, 分为好评和差评.

好评:
0 做父母一定要有刘墉这样的心态,不断地学习,不断地进步,不断地给自己补充新鲜血液,让自己保持一...
1 作者真有英国人严谨的风格,提出观点、进行论述论证,尽管本人对物理学了解不深,但是仍然能感受到...
2 作者长篇大论借用详细报告数据处理工作和计算结果支持其新观点。为什么荷兰曾经县有欧洲最高的生产...
3 作者在战几时之前用了"拥抱"令人叫绝.日本如果没有战败,就有会有美军的占领,没胡官僚主义的延...
4 作者在少年时即喜阅读,能看出他精读了无数经典,因而他有一个庞大的内心世界。他的作品最难能可贵...
5 作者有一种专业的谨慎,若能有幸学习原版也许会更好,简体版的书中的印刷错误比较多,影响学者理解...
6 作者用诗一样的语言把如水般清澈透明的思想娓娓道来,像一个经验丰富的智慧老人为我们解开一个又一...
7 作者提出了一种工作和生活的方式,作为咨询界的元老,不仅能提出理念,而且能够身体力行地实践,并...
8 作者妙语连珠,将整个60-70年代用层出不穷的摇滚巨星与自身故事紧紧相连什么是乡愁?什么是摇...
9 作者逻辑严密,一气呵成。没有一句废话,深入浅出,循循善诱,环环相扣。让平日里看到指标图释就头...
差评:
0 做为一本声名在外的流行书,说的还是广州的外企,按道理应该和我的生存环境差不多啊。但是一看之下...
1 作者有明显的自恋倾向,只有有老公养不上班的太太们才能像她那样生活。很多方法都不实用,还有抄袭...
2 作者完全是以一个过来的自认为是成功者的角度去写这个问题,感觉很不客观。虽然不是很喜欢,但是,...
3 作者提倡内调,不信任化妆品,这点赞同。但是所列举的方法太麻烦,配料也不好找。不是太实用。
4 作者的文笔一般,观点也是和市面上的同类书大同小异,不推荐读者购买。
5 作者的文笔还行,但通篇感觉太琐碎,有点文人的无病呻吟。自由主义者。作者的品性不敢苟同,无民族...
6 作者倒是个很小资的人,但有点自恋的感觉,书并没有什么大帮助
7 作为一本描写过去年代感情生活的小说,作者明显生活经验不足,并且文字功底极其一般,看后感觉浪费...
8 作为个人经验在网上谈谈可以,但拿来出书就有点过了,书中还有些明显的谬误。不过文笔还不错,建议...
9 昨天刚兴奋地写了评论,今天便遇一闹心事,因把此套书推荐给很多朋友,朋友就拖我在网上购,结果前...
import numpy as np
import pandas as pd
import jieba
# 读取停用词
stop_Words = pd.read_csv("stopwords.txt", index_col=None, names=["stop_word"])
stop_words = stop_words["stop_word"].values.tolist()
def load_data():
# 读取数据
neg = pd.read_excel("neg.xls", header=None)
pos = pd.read_excel("pos.xls", header=None)
# 调试输出
print(neg.head(10))
print(pos.head(10))
# 组合
x = np.concatenate((pos[0], neg[0]))
y = np.concatenate((np.ones(len(pos), dtype=int), np.zeros(len(neg), dtype=int)))
# 生成df
data = pd.DataFrame({"content": x, "label": y})
print(data.head())
data.to_csv("data.csv")
def pre_process(text):
# 分词
text = jieba.lcut(text)
# 去除数字
text = [w for w in text if not str(w).isdigit()]
# 去除左右空格
text = list(filter(lambda w: w.strip(), text))
# # 去除长度为1的字符
# text = list(filter(lambda w: len(w) > 1, text))
# 去除停用
text = list(filter(lambda w: w not in stop_words, text))
return " ".join(text)
if __name__ == '__main__':
# 读取数据
data = pd.read_csv("data.csv")
# 预处理
data["content"] = data["content"].apply(pre_process)
# 保存
data.to_csv("processed.csv", index=False)
import pandas as pd
import Tensorflow as tf
from sklearn.model_selection import train_test_split
def tokenizer():
# 读取数据
data = pd.read_csv("processed.csv", index_col=False)
print(data.head())
# 转换成元组
X = tuple(data["content"])
# 实例化tokenizer
tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=30000)
# 拟合
tokenizer.fit_on_texts(X)
# 词袋
word_index = tokenizer.word_index
# print(word_index)
print(len(word_index))
# 转换
sequence = tokenizer.texts_to_sequences(X)
# 填充
characters = tf.keras.preprocessing.sequence.pad_sequences(sequence, maxlen=100)
# 标签转换
labels = tf.keras.utils.to_cateGorical(data["label"])
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(characters, labels, test_size=0.2,
random_state=0)
return X_train, X_test, y_train, y_test
def main():
# 读取分词数据
X_train, X_test, y_train, y_test = tokenizer()
print(X_train[:5])
print(y_train[:5])
# 超参数
EMBEDDING_DIM = 200 # embedding 维度
optimizer = tf.keras.optimizers.RMSprop() # 优化器
loss = tf.losses.CategoricalCrossentropy(from_logits=True) # 损失
# 模型
model = tf.keras.Sequential([
tf.keras.layers.Embedding(30001, EMBEDDING_DIM),
tf.keras.layers.LSTM(200, dropout=0.2, recurrent_dropout=0.2),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(2, activation="softmax")
])
model.build(input_shape=[None, 20])
print(model.summary())
# 组合
model.compile(optimizer=optimizer, loss=loss, metrics=["accuracy"])
# 保存
checkpoint = tf.keras.callbacks.ModelCheckpoint("model/jindong.h5py", monitor='val_accuracy', verbose=1,
save_best_only=True,
mode='max')
# 训练
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=2, batch_size=32, callbacks=[checkpoint])
if __name__ == '__main__':
main()
输出结果:
Unnamed: 0 content label
0 0 做 父母 一定 要 有 刘墉 这样 的 心态 不断 地 学习 不断 地 进步 不断 地 给 ... 1
1 1 作者 真有 英国人 严谨 的 风格 提出 观点 进行 论述 论证 尽管 本人 对 物理学 了... 1
2 2 作者 长篇大论 借用 详细 报告 数据处理 工作 和 计算结果 支持 其新 观点 为什么 荷... 1
3 3 作者 在 战 几时 之前 用 了 " 拥抱 " 令人 叫绝 . 日本 如果 没有 战败 就 ... 1
4 4 作者 在 少年 时即 喜 阅读 能 看出 他 精读 了 无数 经典 因而 他 有 一个 庞大... 1
49366
[[ 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 205 1808 119 40 56 2139 1246 434 3594 1321 1715
9 165 15 22]
[ 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 1157 8 3018 1 62 851 34 4 23 455 365
46 239 1157 3903]
[ 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 1579 53 388 958 294 1146 18 1 49 1146 305
2365 1 496 235]
[ 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 213 4719 509
730 21403 524 42]
[ 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 105 159 1 5 16 11
24 2 299 294 8 39 306 16796 11 1778 29 2674
640 2 543 1820]]
[[0. 1.]
[0. 1.]
[1. 0.]
[1. 0.]
[1. 0.]]
2021-09-20 18:59:07.031583: W tensorflow/stream_executor/platfORM/default/dso_loader.cc:64] Could not load dynamic library 'nvcuda.dll'; dlerror: nvcuda.dll not found
2021-09-20 18:59:07.031928: W tensorflow/stream_executor/cuda/cuda_driver.cc:326] failed call to cuInit: UNKNOWN ERROR (303)
2021-09-20 18:59:07.037546: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:169] retrieving CUDA diagnostic information for host: DESKTOP-VVCH1JQ
2021-09-20 18:59:07.037757: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:176] hostname: DESKTOP-VVCH1JQ
2021-09-20 18:59:07.043925: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneapi Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 200) 6000200
_________________________________________________________________
lstm (LSTM) (None, 200) 320800
_________________________________________________________________
dropout (Dropout) (None, 200) 0
_________________________________________________________________
dense (Dense) (None, 64) 12864
_________________________________________________________________
dense_1 (Dense) (None, 2) 130
=================================================================
Total params: 6,333,994
Trainable params: 6,333,994
Non-trainable params: 0
_________________________________________________________________
None
2021-09-20 18:59:07.470578: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:176] None of the MLIR Optimization Passes are enabled (reGIStered 2)
Epoch 1/2
C:\Users\windows\Anaconda3\lib\site-packages\tensorflow\python\keras\backend.py:4870: UserWarning: "`categorical_crossentropy` received `from_logits=True`, but the `output` argument was produced by a sigmoid or softmax activation and thus does not represent logits. Was this intended?"
'"`categorical_crossentropy` received `from_logits=True`, but '
528/528 [==============================] - 272s 509ms/step - loss: 0.3762 - accuracy: 0.8476 - val_loss: 0.2835 - val_accuracy: 0.8839Epoch 00001: val_accuracy improved from -inf to 0.88391, saving model to model\jindong.h5py
2021-09-20 19:03:40.563733: W tensorflow/Python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
Epoch 2/2
528/528 [==============================] - 299s 566ms/step - loss: 0.2069 - accuracy: 0.9266 - val_loss: 0.2649 - val_accuracy: 0.9005Epoch 00002: val_accuracy improved from 0.88391 to 0.90050, saving model to model\jindong.h5py
到此这篇关于Python机器学习NLP自然语言处理基本操作之京东评论分类的文章就介绍到这了,更多相关Python NLP 京东评论分类内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python机器学习NLP自然语言处理基本操作之京东评论分类
本文链接: https://www.lsjlt.com/news/154742.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0