目录数据类型类型的基本归类整形有符号数和无符号数是否char 等于signed char呢?浮点型构造类型(自定义类型)指针类型空类型整形在内存中的存储原码,反码,补码正整数负整数大
常见的数据类型
| 常见的数据类型 | 字节 | |
|---|---|---|
| char | 字符数据类型 | 1 |
| short | 短整型 | 2 |
| int | 整形 | 4 |
| long | 长整型 | 4 |
| long long | 更长的整形 | 8 |
| float | 浮点型 | 4 |
| double | 双精度浮点型 | 8 |
注意:
#include<stdbool.h>
int main()
{
_Bool flag = false;
_Bool flag2 = true;
if(flag)
{
printf("haha\n");
}
if(flag2)
{
printf("hehe\n");
}
return 0;
}//只打印了hehe
char也属于整形(每一个字符在储存的时候是储存他所对应的ascll值,ascll是整数)
| char | unsigned char | signed char |
| short | unsigned short | signed short |
| int | unsigned int | signed int |
| long | unsigned long | signed long |
int main()
{
int a = 10;
int a = -10;
return 0;
}//a是一个有符号数,它可以储存正负整数
//int ===> signed int
//short ===> signed short
//long ===> signed long
有一些变量只有正数由意义,例如年龄,价格。定义这些变量的时候就可以用无符号数定义 ,无符号数只能存储正数。
int main()
{
unsigned int a = 10;
//无符号变量只能储存正数
a = -10;
//即使这里输入了一个负数,它也会把这个负数转化成一个正数(不是简单的去掉符号,这是关于二进制的计算)
return 0;
}
答案:取决于编译器
打印无符号数应该用%u
%u和%d打印的解读方式不同:
#include<stdio.h>
int main()
{
unsigned int a = 10;
printf("%u",a);//正确的形式
//如果存储了一个-10进去会怎么样
a = -10;
printf("%u",a);
//会打印4294967286,而这个数据不是随机数
return 0;
}
为什么无符号整形储存 -10 的时候会打印出来4284967286(并不是随机数)?
%u在解读的时候认为此时a仍然存储的是正数,解读了a的补码。在本章后面介绍原反补吗的时候在详细解释细节。
| 浮点型 | 大小 |
|---|---|
| float | 4 |
| double | 8 |
| 构造类型 | |
|---|---|
| 数组 | 数组名去掉后剩下的就是数组的类型 |
| 结构体 | struct |
| 枚举类型 | enum |
| 联合(联合体)类型 | uNIOn |
| 指针类型 |
|---|
| char* pc |
| int * pi |
| float* pf |
| void* pv |
void表示空类型(无类型)
通常应用于函数的返回类型,函数的参数,指针类型
int a = 10;
int b = -10;
然后我们观察a、b在内存中的储存

数据在内存里面是以二进制储存的,但是编译器是以十六进制展现给我们看的:
a在内存中的值是 :0a 00 00 00
b在内存中的值是: f6 ff ff ff
为什么是这样的值呢?下面介绍整数的原码、反码、补码。
整数二进制有3种表示形式,而内存中存储的是二进制的补码
例如 1 的原码:
00000000 00000000 00000000 00000001
正整数的原码、反码和补码相同
从原码转换成补码:先取反再加一。
从补码转换成原码:可以先减一再取反,也可以先取反再加一(和原码转换成补码的过程相同)。
| 类型 | 数据:15 | 数据:-15 |
|---|---|---|
| 原码 | 00000000 00000000 00000000 00001111 | 10000000 00000000 00000000 00001111 |
| 反码 | 00000000 00000000 00000000 00001111 | 11111111 11111111 11111111 11110000 |
| 补码 | 00000000 00000000 00000000 00001111 | 11111111 11111111 11111111 11110001 |
解释为什么%u打印-10;会出现4294967286
用上面的方法我们就可以计算出-10的补码:
| 数据 | 补码 |
|---|---|
| 10 | 11111111 11111111 11111111 11110110 |
回到最开始使用%u打印-10会打印成4294967286,是因为在使用%u的时候,不会解读符号位,会将整个32位二进制都当作有效位,读出一个数据,而这个数据就是4294967286。
同时回到刚才a,b的值
int main()
{
int a = 10;
int b = -10;
//a: 00000000 00000000 00000000 00001010
//b: 11111111 11111111 11111111 11110110
}
//四个二进制位转换成一个十六进制位
//a: 00 00 00 0a
//b: ff ff ff f6
为什么和在内存界面看到的不同呢?
内存界面和我们计算出来的顺序是相反的:
| 数据 | 计算结果 | 内存 |
|---|---|---|
| 10 | 00 00 00 0a | 0a 00 00 00 |
| -10 | ff ff ff f6 | f6 ff ff ff |
为什么会倒着存进去?
这就和字节序有关,下面我们来了解字节序
当储存的内容超过一个字节的时候,储存的时候就有顺序
(一个char类型的数据是没有字节序。char类型的数据只有一个字节,没有顺序)
机器有两种对字节的存储顺序:
我们用下面这个例子来解释:
int main()
{
int a = 0x11223344;//0x开头说明是十六进制数字
//再内存界面看到:44 33 22 11
return 0;
}

而我在观察内存的时候发现我的机器是按照方式2进行存储的,所以我的机器是采用的小端字节序。
那么有什么方法可以快速判断自己当前使用的机器属于哪一种字节序呢?
#include<stdio.h>
int main()
{
int a = 1;
//a的十六进制是 00 00 00 01
//如果是大端那么内存中为:00 00 00 01
//如果是小端那么内存中为:01 00 00 00
//只需要判断第一个字节的内容是不是1
char*pc = (char*)&a;
//强制类型转换截取了a的第一个字节
if(*pc)//也可以是:if(*(char*)&a)
{
printf("小端");
}
else
{
printf("大端");
}
return 0;
}
int main()
{
char a = -1;
signed char b = -1;
unsigned char c = -1;
printf("%d %d %d ",a,b,c);//会打印出-1 -1 255
return 0;
}
解释:
| 数据(变量) | 整形提升前 | 整形提升后(补码) | 原码代表的数据 |
|---|---|---|---|
| a/b | 11111111 | 11111111 11111111 11111111 11111111 | -1 |
| c | 11111111 | 00000000 00000000 00000000 11111111 | 255 |
%d打印的时候会认为这就是要打印数据的补码,按照打印正常整数的形式打印这三个变量
#include<stdio.h>
int main()
{
char a = -128;
printf("%u",a);//会打印4294967168
return 0;
}
解释:
| 数据 | 二进制(补码) | 截取(a储存的部分) |
|---|---|---|
| -128 | 11111111 11111111 11111111 10000000 | 10000000 |
联想:这里如果是a = 128,那么阶段后的值仍然是10000000
| 数据(变量) | 整形提升前 | 整形提升后(补码) |
|---|---|---|
| a | 10000000 | 11111111 11111111 11111111 10000000 |
| 常见的浮点数 | 例子 |
|---|---|
| 字面浮点数 | 3.14159 |
| 科学计数法的表示形式 | 1E10(1乘以10的10次方) |
注意:
我们通过下面这个例题来探究浮点型和整形在内存中的储存方式有什么不同
#include<stdio.h>
int main()
{
int n = 9;
float* pf = (float*)&n;
//第一组
printf("n = %d\n", n); //打印出:9
printf("*pf = %f\n", *pf);//打印出:0.000000
//第二组
*pf = 9.0;
printf("n = %d\n", n); //打印出:1091567616
printf("*pf = %f\n", *pf);//打印出:9.000000
return 0;
}
为什么会出现这样的情况?
回答这个问题前,先来了解浮点型的二进制存储形式:
国际标准电气电子工程师学会(IEEE):任何一个二进制浮点数V都可以表示成下面的形式
| (5.5)十进制 | (5.5)二进制 |
|---|---|
| 5.5 | 101.1 |
| 5.5*(10^1) | 1.011*(2^2) |
十进制浮点数:5.5
转化成二进制:101.1
可以写成:(-1)^0 * 1.011 * (2^2)
S = 0
M = 1.011
E = 2
只需要储存SME三个值
单精度浮点数储存格式(32位)
| 第一位 | 接着8位 | 剩下23位 |
|---|---|---|
| 符号位 | 指数位 | 有效位 |
双精度浮点数储存格式(64位)
| 第一位 | 接着11位 | 剩下52位 |
|---|---|---|
| 符号位 | 指数位 | 有效位 |
原因:
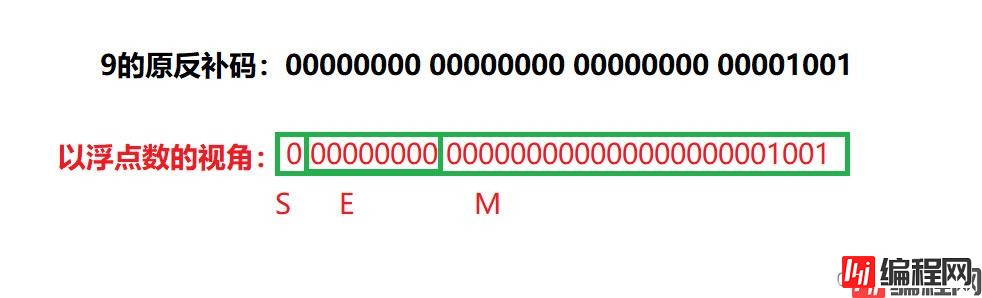
此时E为全0,是一个会被判定成一个十分小的数据,所以打印0.000000

--结束END--
本文标题: C语言中数据在内存如何存储
本文链接: https://www.lsjlt.com/news/159458.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0