目录起源进程内存布局栈设置分配方式特点堆分配方式特点堆与栈区别扩展总结起源 之前在知乎上看了一句话,指针是C的精髓,也是初学者的一个坎。换句话说,内存管理是C的精髓,C/C++可以直
之前在知乎上看了一句话,指针是C的精髓,也是初学者的一个坎。换句话说,内存管理是C的精髓,C/C++可以直接跟OS打交道,从性能角度出发,开发者可以根据自己的实际使用场景灵活进行内存分配和释放。虽然在c++中自C++11引入了smart pointer,虽然很大程度上能够避免使用裸指针,但仍然不能完全避免,最重要的一个原因是你不能保证组内其他人不适用指针,更不能保证合作部门不使用指针。
那么为什么C/C++中会存在指针呢?
这就得从进程的内存布局说起。

上图为32位进程的内存布局,从上图中主要包含以下几个块:
由于本文主要讲内存分配相关,所以下面的内容仅涉及到栈(stack)和堆(heap)。
栈一块连续的内存块,栈上的内存分配就是在这一块连续内存块上进行操作的。编译器在编译的时候,就已经知道要分配的内存大小,当调用函数时候,其内部的遍历都会在栈上分配内存;当结束函数调用时候,内部变量就会被释放,进而将内存归还给栈。
class Object {
public:
Object() = default;
// ....
};
void fun() {
Object obj;
// do sth
}
在上述代码中,obj就是在栈上进行分配,当出了fun作用域的时候,会自动调用Object的析构函数对其进行释放。
前面有提到,局部变量会在作用域(如函数作用域、块作用域等)结束后析构、释放内存。因为分配和释放的次序是刚好完全相反的,所以可用到堆栈先进后出(first-in-last-out, FILO)的特性,而 C++ 语言的实现一般也会使用到调用堆栈(call stack)来分配局部变量(但非标准的要求)。
因为栈上内存分配和释放,是一个进栈和出栈的过程(对于编译器只是一个移动指针的过程),所以相比于堆上的内存分配,栈要快的多。
虽然栈的访问速度要快于堆,每个线程都有一个自己的栈,栈上的对象是不能跨线程访问的,这就决定了栈空间大小是有限制的,如果栈空间过大,那么在大型程序中几十乃至上百个线程,光栈空间就消耗了RAM,这就导致heap的可用空间变小,影响程序正常运行。
在linux系统上,可用通过如下命令来查看栈大小:
ulimit -s
10240
在笔者的机器上,执行上述命令输出结果是10240(KB)即10m,可以通过shell命令修改栈大小。
ulimit -s 102400通过如上命令,可以将栈空间临时修改为100m,可以通过下面的命令:
/etc/security/limits.conf静态分配
静态分配由编译器完成,假如局部变量以及函数参数等,都在编译期就分配好了。
void fun() {
int a[10];
}
上述代码中,a占10 * sizeof(int)个字节,在编译的时候直接计算好了,运行的时候,直接进栈出栈。
动态分配
可能很多人认为只有堆上才会存在动态分配,在栈上只可能是静态分配。其实,这个观点是错的,栈上也支持动态分配,该动态分配由alloca()函数进行分配。栈的动态分配和堆是不同的,通过alloca()函数分配的内存由编译器进行释放,无序手动操作。
堆(heap)是一种内存管理方式。内存管理对操作系统来说是一件非常复杂的事情,因为首先内存容量很大,其次就是内存需求在时间和大小块上没有规律(操作系统上运行着几十甚至几百个进程,这些进程可能随时都会申请或者是释放内存,并且申请和释放的内存块大小是随意的)。
堆这种内存管理方式的特点就是自由(随时申请、随时释放、大小块随意)。堆内存是操作系统划归给堆管理器(操作系统中的一段代码,属于操作系统的内存管理单元)来管理的,堆管理器提供了对应的接口_sbrk、mmap_等,只是该接口往往由运行时库进行调用,即也可以说由运行时库进行堆内存管理,运行时库提供了malloc/free函数由开发人员调用,进而使用堆内存。
正如我们所理解的那样,由于是在运行期进行内存分配,分配的大小也在运行期才会知道,所以堆只支持动态分配,内存申请和释放的行为由开发者自行操作,这就很容易造成我们说的内存泄漏。
理解堆和栈的区别,对我们开发过程中会非常有用,结合上面的内容,总结下二者的区别。
对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制,容易产生memory leak
进栈和出栈 截止到这里,栈和堆的基本特性以及各自的优缺点、使用场景已经分析完成,在这里给开发者一个建议,能使用栈的时候,就尽量使用栈,一方面是因为效率高于堆,另一方面内存的申请和释放由编译器完成,这样就避免了很多问题。
终于到了这一小节,其实,上面讲的那么多,都是为这一小节做铺垫。
在前面的内容中,我们对比了栈和堆,虽然栈效率比较高,且不存在内存泄漏、内存碎片等,但是由于其本身的局限性(不能多线程、大小受限),所以在很多时候,还是需要在堆上进行内存。
我们先看一段代码:
#include <stdio.h>
#include <stdlib.h>
int main() {
int a;
int *p;
p = (int *)malloc(sizeof(int));
free(p);
return 0;
}
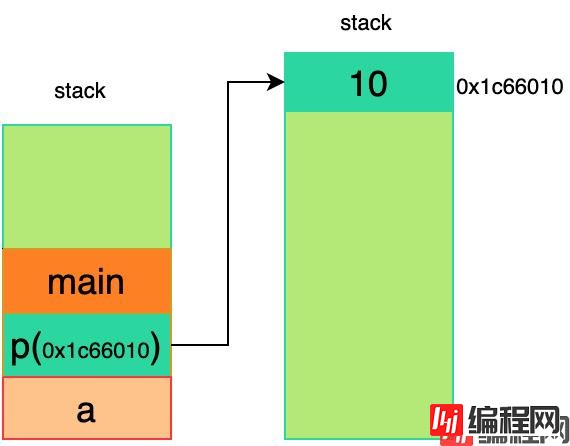
上述代码很简单,有两个变量a和p,类型分别为int和int *,其中,a和p存储在栈上,p的值为在堆上的某块地址(在上述代码中,p的值为0x1c66010),上述代码布局如下图所示:
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注编程网的更多内容!
--结束END--
本文标题: 深入理解C语言的指针
本文链接: https://www.lsjlt.com/news/162552.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0