Python 官方文档:入门教程 => 点击学习
目录一、Introduction1 BP神经网络的优点2 BP神经网络的缺点二、实现过程1 Demo2 基于BP神经网络的乳腺癌分类预测三、Keys一、Introduction 1
#%% 基础数组运算库导入
import numpy as np
# 画图库导入
import matplotlib.pyplot as plt
# 导入三维显示工具
from mpl_toolkits.mplot3D import Axes3D
# 导入BP模型
from sklearn.neural_network import MLPClassifier
# 导入demo数据制作方法
from sklearn.datasets import make_classification
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import warnings
from sklearn.exceptions import ConvergenceWarning
#%%模型训练
# 制作五个类别的数据,每个类别1000个样本
train_samples, train_labels = make_classification(n_samples=1000, n_features=3,
n_redundant=0,n_classes=5, n_infORMative=3,
n_clusters_per_class=1,class_sep=3, random_state=10)
# 将五个类别的数据进行三维显示
fig = plt.figure()
ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=20, azim=20)
ax.scatter(train_samples[:, 0], train_samples[:, 1], train_samples[:, 2], marker='o', c=train_labels)
plt.title('Demo Data Map')

#%% 建立 BP 模型, 采用sgd优化器,relu非线性映射函数
BP = MLPClassifier(solver='sgd',activation = 'relu',max_iter = 500,alpha = 1e-3,
hidden_layer_sizes = (32,32),random_state = 1)
# 进行模型训练
with warnings.catch_warnings():
warnings.filterwarnings("ignore", cateGory=ConvergenceWarning,
module="sklearn")
BP.fit(train_samples, train_labels)
# 查看 BP 模型的参数
print(BP)
#%% 进行模型预测
predict_labels = BP.predict(train_samples)
# 显示预测的散点图
fig = plt.figure()
ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=20, azim=20)
ax.scatter(train_samples[:, 0], train_samples[:, 1], train_samples[:, 2], marker='o', c=predict_labels)
plt.title('Demo Data Predict Map with BP Model')
# 显示预测分数
print("预测准确率: {:.4f}".format(BP.score(train_samples, train_labels)))
# 可视化预测数据
print("真实类别:", train_labels[:10])
print("预测类别:", predict_labels[:10])
# 准确率等报表
print(classification_report(train_labels, predict_labels))
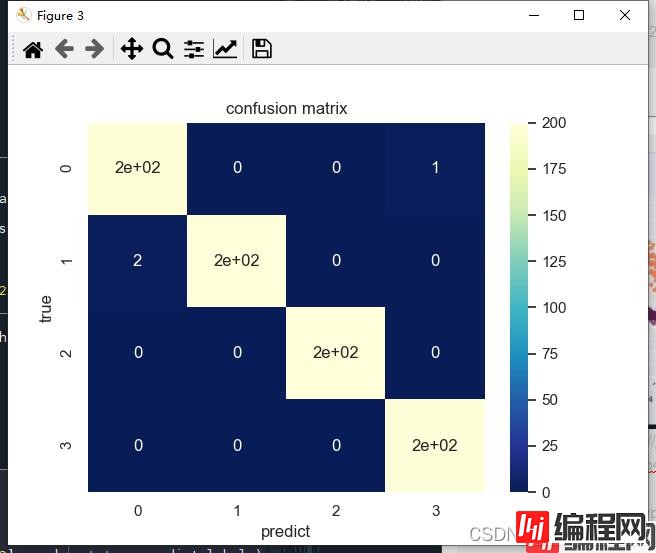
# 计算混淆矩阵
classes = [0, 1, 2, 3]
cofusion_mat = confusion_matrix(train_labels, predict_labels, classes)
sns.set()
figur, ax = plt.subplots()
# 画热力图
sns.heatmap(cofusion_mat, cmap="YlGnBu_r", annot=True, ax=ax)
ax.set_title('confusion matrix') # 标题
ax.set_xticklabels([''] + classes, minor=True)
ax.set_yticklabels([''] + classes, minor=True)
ax.set_xlabel('predict') # x轴
ax.set_ylabel('true') # y轴
plt.show()


#%%# 进行新的测试数据测试
test_sample = np.array([[-1, 0.1, 0.1]])
print(f"{test_sample} 类别是: ", BP.predict(test_sample))
print(f"{test_sample} 类别概率分别是: ", BP.predict_proba(test_sample))
test_sample = np.array([[-1.2, 10, -91]])
print(f"{test_sample} 类别是: ", BP.predict(test_sample))
print(f"{test_sample} 类别概率分别是: ", BP.predict_proba(test_sample))
test_sample = np.array([[-12, -0.1, -0.1]])
print(f"{test_sample} 类别是: ", BP.predict(test_sample))
print(f"{test_sample} 类别概率分别是: ", BP.predict_proba(test_sample))
test_sample = np.array([[100, -90.1, -9.1]])
print(f"{test_sample} 类别是: ", BP.predict(test_sample))
print(f"{test_sample} 类别概率分别是: ", BP.predict_proba(test_sample))

#%%基于BP神经网络的乳腺癌分类
#基本库导入
# 导入乳腺癌数据集
from sklearn.datasets import load_breast_cancer
# 导入BP模型
from sklearn.neural_network import MLPClassifier
# 导入训练集分割方法
from sklearn.model_selection import train_test_split
# 导入预测指标计算函数和混淆矩阵计算函数
from sklearn.metrics import classification_report, confusion_matrix
# 导入绘图包
import seaborn as sns
import matplotlib.pyplot as plt
# 导入三维显示工具
from mpl_toolkits.mplot3d import Axes3D
# 导入乳腺癌数据集
cancer = load_breast_cancer()
# 查看数据集信息
print('breast_cancer数据集的长度为:',len(cancer))
print('breast_cancer数据集的类型为:',type(cancer))
# 分割数据为训练集和测试集
cancer_data = cancer['data']
print('cancer_data数据维度为:',cancer_data.shape)
cancer_target = cancer['target']
print('cancer_target标签维度为:',cancer_target.shape)
cancer_names = cancer['feature_names']
cancer_desc = cancer['DESCR']
#分为训练集与测试集
cancer_data_train,cancer_data_test = train_test_split(cancer_data,test_size=0.2,random_state=42)#训练集
cancer_target_train,cancer_target_test = train_test_split(cancer_target,test_size=0.2,random_state=42)#测试集

#%%# 建立 BP 模型, 采用Adam优化器,relu非线性映射函数
BP = MLPClassifier(solver='adam',activation = 'relu',max_iter = 1000,alpha = 1e-3,hidden_layer_sizes = (64,32, 32),random_state = 1)
# 进行模型训练
BP.fit(cancer_data_train, cancer_target_train)
#%% 进行模型预测
predict_train_labels = BP.predict(cancer_data_train)
# 可视化真实数据
fig = plt.figure()
ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=20, azim=20)
ax.scatter(cancer_data_train[:, 0], cancer_data_train[:, 1], cancer_data_train[:, 2], marker='o', c=cancer_target_train)
plt.title('True Label Map')
plt.show()
# 可视化预测数据
fig = plt.figure()
ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=20, azim=20)
ax.scatter(cancer_data_train[:, 0], cancer_data_train[:, 1], cancer_data_train[:, 2], marker='o', c=predict_train_labels)
plt.title('Cancer with BP Model')
plt.show()

#%% 显示预测分数
print("预测准确率: {:.4f}".format(BP.score(cancer_data_test, cancer_target_test)))
# 进行测试集数据的类别预测
predict_test_labels = BP.predict(cancer_data_test)
print("测试集的真实标签:\n", cancer_target_test)
print("测试集的预测标签:\n", predict_test_labels)
#%% 进行预测结果指标统计 统计每一类别的预测准确率、召回率、F1分数
print(classification_report(cancer_target_test, predict_test_labels))

#%% 计算混淆矩阵
confusion_mat = confusion_matrix(cancer_target_test, predict_test_labels)
# 打印混淆矩阵
print(confusion_mat)
# 将混淆矩阵以热力图的方式显示
sns.set()
figure, ax = plt.subplots()
# 画热力图
sns.heatmap(confusion_mat, cmap="YlGnBu_r", annot=True, ax=ax)
# 标题
ax.set_title('confusion matrix')
# x轴为预测类别
ax.set_xlabel('predict')
# y轴实际类别
ax.set_ylabel('true')
plt.show()

注:之前还做过基于BP神经网络的人口普查数据预测,有需要的猿友私信
BP神经网络的要点在于前向传播和误差反向传播,来对参数进行更新,使得损失最小化。
它是一个迭代算法,基本思想是:
886~~~
到此这篇关于python机器学习应用之基于BP神经网络的预测篇详解的文章就介绍到这了,更多相关Python BP神经网络内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python机器学习应用之基于BP神经网络的预测篇详解
本文链接: https://www.lsjlt.com/news/162773.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0