Python 官方文档:入门教程 => 点击学习
目录1.滤除缺失数据dropna()1)滤除含有NaN值的所有行2)滤除含有NaN值的所有列3)滤除元素都是NaN值的行4)滤除元素都是NaN值的列5)滤除指定列中含有缺失的行2.删
import pandas as pd
import numpy as np
df=pd.DataFrame({"record":[np.nan,"亚健康|潘光|45岁","疾病|张思",np.nan],"date":[np.nan,20210102,20210103,20210104]},index=["one","two","three","four"])
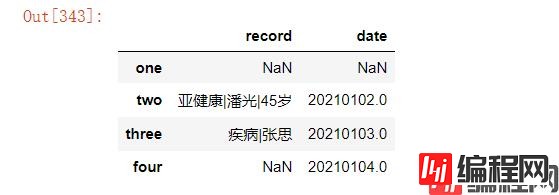
df.dropna()#默认axis=0

df.dropna(axis=1)

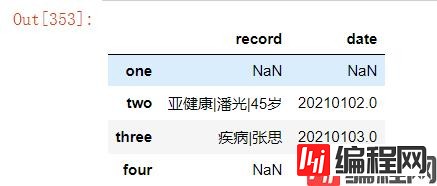
df.dropna(axis=0,how="all")
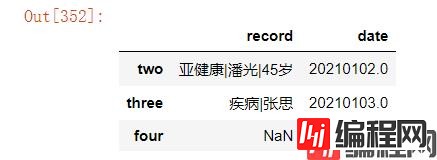
df.dropna(subset=["record"],axis=0)

以上如果需要在原数据上直接做更改,需设置参数inplace=True
df=pd.DataFrame({'state':[1,1,2,2,1,2,2],'pop':['a','b','c','d','b','c','d']})

语法:drop_duplicates(subset,keep,inplace),其中参数 keep:{‘first’,‘last’,False},默认’first’
first:保留第一次出现的重复项,删除第二次及之后出现的重复项。
last:保留最后一次出现的重复项,删除之前出现的重复项。
"false":删除所有重复项。
df.drop_duplicates(keep="first")
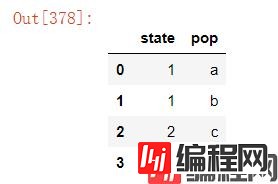
df.drop_duplicates(keep="last")

df.drop_duplicates(keep=False)

df.drop_duplicates(subset=["state"],keep="first")

以上如果需要在原数据上直接做更改,需设置参数inplace=True
df=pd.DataFrame(np.arange(16).reshape(4,4),columns=["one","two","three","four"])
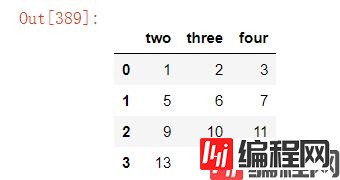
df.drop(["one"],axis=1)
另外,也可通过del df["one"]来实现删除指定列,但该方法不推荐,因为这默认直接在源数据上做更改。
df.drop([0],axis=0)

以上如果需要在原数据上直接做更改,需设置参数inplace=True
到此这篇关于python pandas删除指定行/列数据的文章就介绍到这了,更多相关Python pandas删除指定行/列内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python pandas删除指定行/列数据的方法实例
本文链接: https://www.lsjlt.com/news/163997.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0