Python 官方文档:入门教程 => 点击学习
目录介绍kafka核心相关名称kafka集群安装kafka使用kafka文件存储SpringBoot整合kafka介绍 Apache Kafka 是分布式发布-订阅消息系统,在 ka
Apache Kafka 是分布式发布-订阅消息系统,在 kafka官网上对 kafka 的定义:一个分布式发布-订阅消息传递系统。 它最初由LinkedIn公司开发,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
注意:Kafka并没有遵循JMS规范(),它只提供了发布和订阅通讯方式。
kafka中文官网:Http://kafka.apachecn.org/quickstart.html
主题和队列的区别:
队列是一个数据结构,遵循先进先出原则
参考官方文档:https://kafka.apachecn.org/quickstart.html

安装jdk环境和zookeeper这里不详述了。
kafka为什么依赖于zookeeper:kafka会将MQ信息存放到zookeeper上,为了使整个集群能够方便扩展,采用zookeeper的事件通知相互感知。
kafka集群安装步骤:
1、下载kafka的压缩包,下载地址:https://kafka.apachecn.org/downloads.html
2、解压安装包
tar -zxvf kafka_2.11-1.0.0.tgz
3、修改kafka的配置文件 config/server.properties
配置文件修改内容:
zookeeper.connect=192.168.1.19:2181listeners=PLaiNTEXT://192.168.1.19:9092broker.id=04、依次启动kafka
./kafka-server-start.sh -daemon config/server.properties
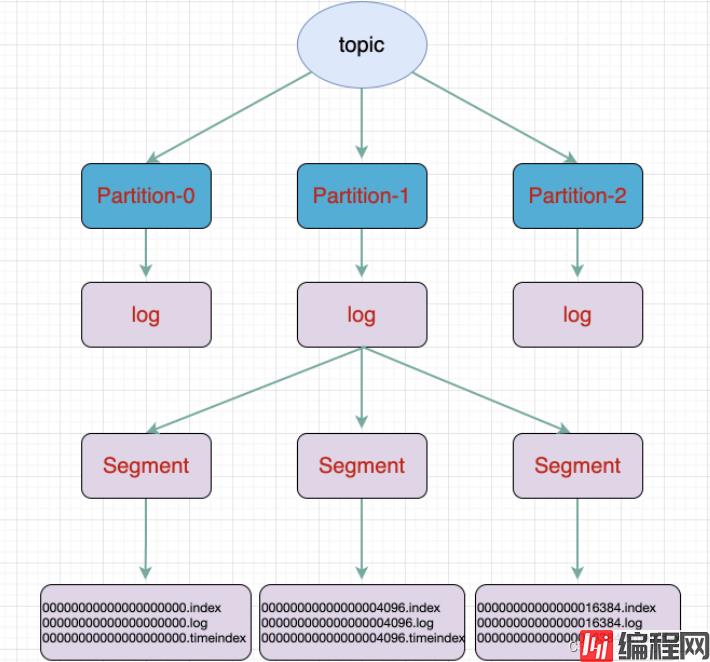
topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是Producer生成的数据。Producer生成的数据会被不断追加到该log文件末端,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment,每个segment包括:“.index”文件、“.log”文件和.timeindex等文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号。
例如:执行命令新建一个主题,分三个区存放放在三个broker中:
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic kaico

Maven依赖
<dependencies>
<!-- springBoot集成kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- SpringBoot整合WEB组件 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
yml配置
# kafka
spring:
kafka:
# kafka服务器地址(可以多个)
# bootstrap-servers: 192.168.212.164:9092,192.168.212.167:9092,192.168.212.168:9092
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094
consumer:
# 指定一个默认的组名
group-id: kafkaGroup1
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: earliest
# key/value的反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# key/value的序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 批量抓取
batch-size: 65536
# 缓存容量
buffer-memory: 524288
# 服务器地址
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094
生产者
@RestController
public class KafkaController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
private void send(String key, String data) {
// topic 名称 key data 消息数据
kafkaTemplate.send("kaico", key, data);
}
// test 主题 1 my_test 3
@RequestMapping("/kafka")
public String testKafka() {
int iMax = 6;
for (int i = 1; i < iMax; i++) {
send("key" + i, "data" + i);
}
return "success";
}
}消费者
@Component
public class TopicKaicoConsumer {
@KafkaListener(topics = "kaico") //监听的主题
public void receive(ConsumerRecord<?, ?> consumer) {
System.out.println("topic名称:" + consumer.topic() + ",key:" +
consumer.key() + "," +
"分区位置:" + consumer.partition()
+ ", 下标" + consumer.offset());
//输出key对应的value的值
System.out.println(consumer.value());
}
}到此这篇关于Java分布式学习之Kafka消息队列的文章就介绍到这了,更多相关Java Kafka内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Java分布式学习之Kafka消息队列
本文链接: https://www.lsjlt.com/news/165490.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0