Python 官方文档:入门教程 => 点击学习
目录SpringCloud Stream什么是springcloud Stream什么是Binder为什么使用StreamStream使用案例前置知识Stream处理消息的架构Str
现在市面上有很多的消息中间件,每一个公司使用的都有所不同,为了减少学习的成本,springcloud Stream可以让我们不再关注消息中间件MQ的具体细节,我们只需要通过适配绑定的方式即可实现不同MQ之间的切换,但是遗憾的是springcloud Stream目前只支持RabbitMQ和kafka。
SpringCloud Stream是一个构建消息驱动微服务的框架,应用程序通过inputs或者 outputs来与SpringCloud Stream中的binder进行交互,我们可以通过配置来binding ,而 SpringCloud Stream 的binder负责与中间件交互,所以我们只需要搞清楚如何与Stream交互就可以很方便的使用消息驱动了!
Binder是SpringCloud Stream的一个抽象概念,是应用与消息中间件之间的粘合剂,通过定义绑定器Binder作为中间层,实现了应用程序与消息中间件细节之间的隔离,可以动态的改变消息的destinations(对应于 Kafka的topic,RabbitMQ的exchanges),这些都可以通过外部配置项来做到,甚至可以任意的改变中间件的类型但是不需要修改一行代码
比方说我们用到了RabbitMQ和Kafka,由于这两个消息中间件的架构上的不同像RabbitMQ有exchange,kafka有Topic和Partitions分区,这些中间件的差异性导致我们实际项目开发给我们造成了一定的困扰,我们如果用了两个消息队列的其中一种,后面的业务需求,我想往另外一种消息队列进行迁移;这时候无疑就是一个灾难性的,一大堆东西都要重新推倒重新做,因为它跟我们的系统耦合了,这衬候springcloud Stream给我们提供了一种解耦合的方式。
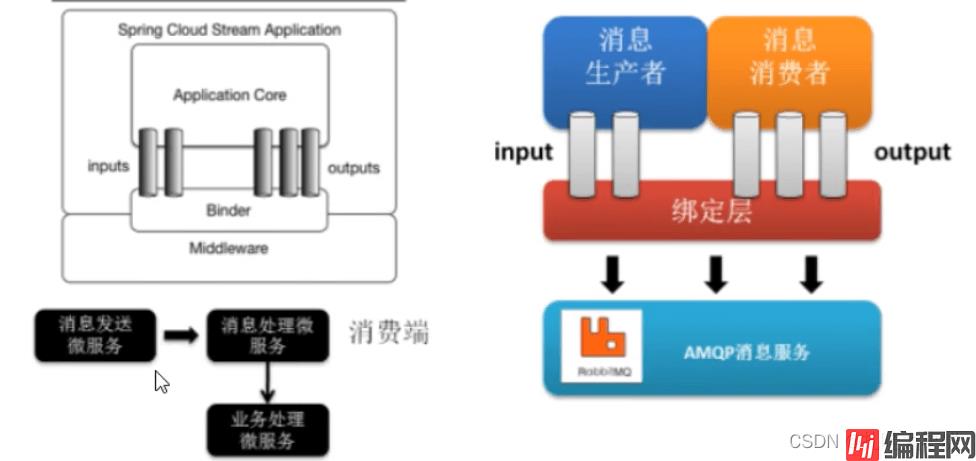

Source、Sink: 简单的可理解为参照对象是spring cloud Stream自身,从Stream发布消息就是输出,接受消息就是输入。Channel: 通道,是队列Queue的一种抽象,在消息通讯系统中就是实现存储和转发的媒介。Binder: 消息的生产者和消费者中间层,实现了应用程序与消息中间件细节之间的隔离
通过以上两张图片可知,消息的处理流向是:消息生产者处理完业务逻辑之后消息到达source中,接着前往Channel通道进行排队,然后通过binder绑定器将消息数据发送到底层mq,然后又通过binder绑定器接收到底层mq发送来的消息数据,接着前往Channel通道进行排队,由Sink接收到消息数据,消息消费者拿到消息数据执行相应的业务逻辑

第一步: 创建一个Maven模块,引入相关依赖,最主要的就是stream整合rabbitmq的依赖
<!--stream的rabbitmq依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>第二步: 配置文件的编写
server:
port: 8801spring:
application:
name: cloud-stream-provider
cloud:
stream:
binders: # 在此处配置要绑定的rabbitmq的服务信息;
defaultRabbit: # 表示定义的名称,用于于binding整合
type: rabbit # 消息组件类型
environment: # 设置rabbitmq的相关的环境配置
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
passWord: guest
bindings: # 服务的整合处理
output: # 这个名字是一个通道的名称
destination: studyExchange # 表示要使用的Exchange名称定义
content-type: application/JSON # 设置消息类型,本次为json,文本则设置“text/plain”
binder: defaultRabbit # 设置要绑定的消息服务的具体设置eureka:
client: # 客户端进行Eureka注册的配置
service-url:
defaultZone: Http://localhost:7001/eureka
第三步: 主程序类
@SpringBootApplication
public class CloudStreamRabbitmqProvider8801Application {
public static void main(String[] args) {
SpringApplication.run(CloudStreamRabbitmqProvider8801Application.class, args);
System.out.println("启动成功");
}
}第四步: 业务层service代码编写,注意:这里实现类注入的对象由之前的dao层对象换成了channel通道对象,详细的发送由实现类的第12完成
public interface IMessageProviderService {
String send();
}
@EnableBinding(Source.class)
public class MessageProviderServiceImpl implements IMessageProviderService {
@Resource
private MessageChannel output;
@Override
public String send() {
String serial = UUID.randomUUID().toString();
output.send(MessageBuilder.withPayload(serial).build());
System.out.println("*****serial: " + serial);
return serial;
}
}
第五步: controller接口
@RestController
public class SendMessageController {
@Resource
private IMessageProviderService messageProviderService;
@GetMapping(value = "/sendMessage")
public String sendMessage() {
return messageProviderService.send();
}
}第一步: 创建一个maven模块,引入相关依赖,最主要的就是stream整合rabbitmq的依赖
<!--stream的rabbitmq依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
第二步: 配置文件的编写,与生产者的区别就在于bindings下的是input而不是output
server:
port: 8802spring:
application:
name: cloud-stream-consumer
cloud:
stream:
binders: # 在此处配置要绑定的rabbitmq的服务信息;
defaultRabbit: # 表示定义的名称,用于于binding整合
type: rabbit # 消息组件类型
environment: # 设置rabbitmq的相关的环境配置
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
bindings: # 服务的整合处理
input: # 这个名字是一个通道的名称
destination: studyExchange # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: defaultRabbit # 设置要绑定的消息服务的具体设置
eureka:
client: # 客户端进行Eureka注册的配置
service-url:
defaultZone: http://localhost:7001/eureka
第三步: 主程序类
@SpringBootApplication
public class CloudStreamRabbitmqConsumer8802Application {
public static void main(String[] args) {
SpringApplication.run(CloudStreamRabbitmqConsumer8802Application.class, args);
System.out.println("启动成功");
}
}第四步: controller接口,使用url请求生产者8801,即可在消费者8802端接收到8801发送的消息
@Component
@EnableBinding(Sink.class)
public class ReceiveMessageListener {
@Value("${server.port}")
private String serverPort;
@StreamListener(Sink.INPUT)
public void input(Message<String> message) {
System.out.println("消费者1号 ----> port:" + serverPort + "\t从8801接受到的消息是:" + message.getPayload());
}
}
两个模块搭建完成进行测试,首先启动注册中心7001,然后分别启动消息生产者8801和消息消费者8802,通过url请求访问8001的发送消息请求,会向指定管道中发送一条消息,如果此时这个管道中有消费者即可接收到这条消息。而如何指定消息的管道归属呢,就是通过配置文件中的indings.input.destination来指定,命名相同的服务就会处在同一条管道中
按照之前的使用,会带来重复消费问题: 也就是说一个通道上有不止一个消息消费者,stream上默认每一个消费者都属于不同的组,这样的话就会导致这个消息被多个组的消费者重复消费
知道了问题出现的原因就很容易解决了,只要我们自定义配置分组,将这些消费者都分配到同一个组中就能避免重复消费的问题出现了(同一个组间的消费者是竞争关系,不管组间有多少的消费者都只会消费一次)
只需要在配置文件修改一处配置即可实现自定义组名并且自定义分组,组名相同的服务会被分配到同一组,通道内的消息数据会被该组中的所有消费者轮询消费
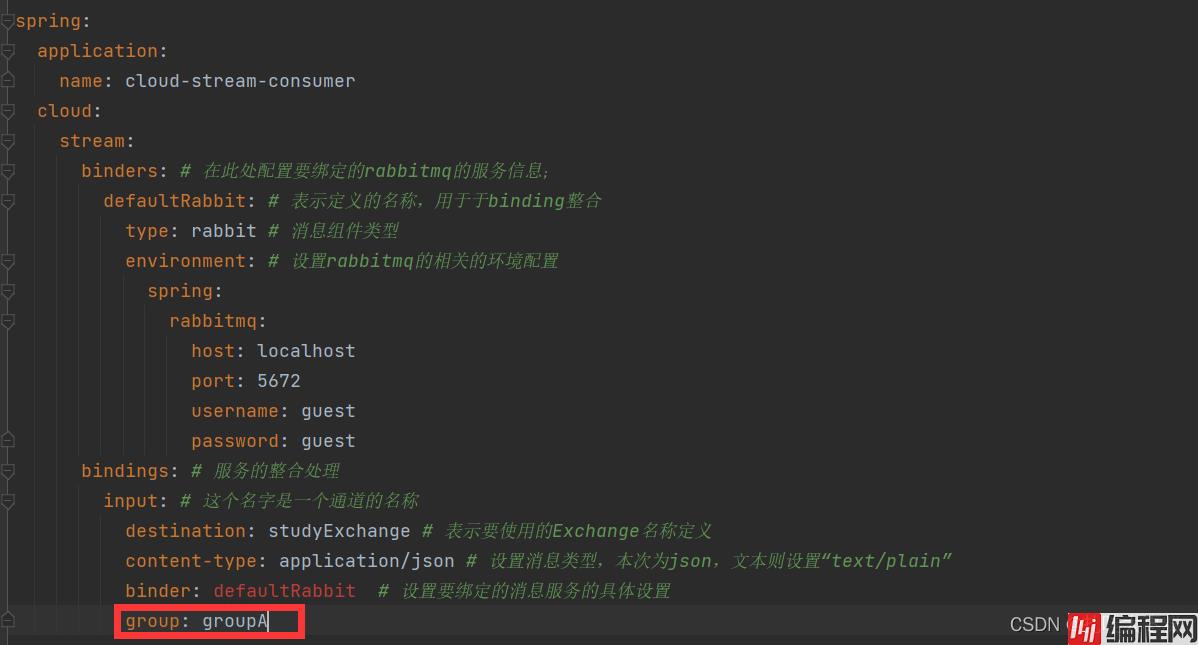
上面自定义分组使用的group配置除了可以自定义分组和分组名之外,还可以实现消息的持久化,也就是说使用group配置自定义分组和分组名的消息消费者,就算在消息生产者发送消息的时候挂掉了,等这个消费者重启之后依然是能够消费之前发送的消息
这里一个生产者和两个消费者存在以下十三种情况(生产者发送四次消息):
1、都使用group分组的两个不同组成员,在生产者生产的时候
2、都使用group分组的两个同组成员,在生产者生产的时候
3、其中一个使用group分组的两个成员,在生产者生产的时候
4、都不使用group分组的两个成员,在生产者生产的时候
总之一句话,通道里的消息会持久化给使用group配置的消息消费者(每一组都有一份),就算发送消息的时候这些消费者挂了,如果同组的消费者有没挂的就会把这些消息竞争消费完;如果同组没有消费者,等他重启之后还是会消费这些消息
到此这篇关于Springcloud Stream消息驱动工具使用介绍的文章就介绍到这了,更多相关Springcloud Stream内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: SpringcloudStream消息驱动工具使用介绍
本文链接: https://www.lsjlt.com/news/167512.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0