目录正文index.js 主入口文件读主入口文件对依赖文件进行读取操作解决依赖成环问题正文 本文带你实现 webpack 最基础的打包功能,同时解决包缓存和环依赖的问题 ~ 发车,先
本文带你实现 webpack 最基础的打包功能,同时解决包缓存和环依赖的问题 ~
发车,先来看示例代码。
我们这里三个文件,index.js 是主入口文件:
// filename: index.js
import foo from './foo.js'
foo();
//filename: foo.js
import message from './message.js'
function foo() {
console.log(message);
}
// filename: message.js
const message = 'hello world'
export default message;
接下来,我们会创建一个 bundle.js 打包这三个文件,打包得到的结果是一个 JS 文件,运行这个 JS 文件输出的结果会是 'hello world'。
bundle.js 就是 WEBpack 做的事情,我们示例中的 index.js 相当于 webpack 的入口文件,会在 webpack.config.js 的 entry 里面配置。
让我们来实现 bundle.js 的功能。
最开始的,当然是读主入口文件了:
function createAssert(filename) {
const content = fs.readFileSync(filename, {
encoding: 'utf-8'
});
return content;
}
const content = createAssert('./example/index.js');

接下来,需要做的事情就是把 import 语法引入的这个文件也找过来,在上图中,就是 foo.js,同时还得把 foo.js 依赖的也找过来,依次递推。
现在得把 foo.js 取出来,怎么解析 import foo from './foo.js' 这句,把值取出来呢?
把这行代码解析成 ast 会变成:
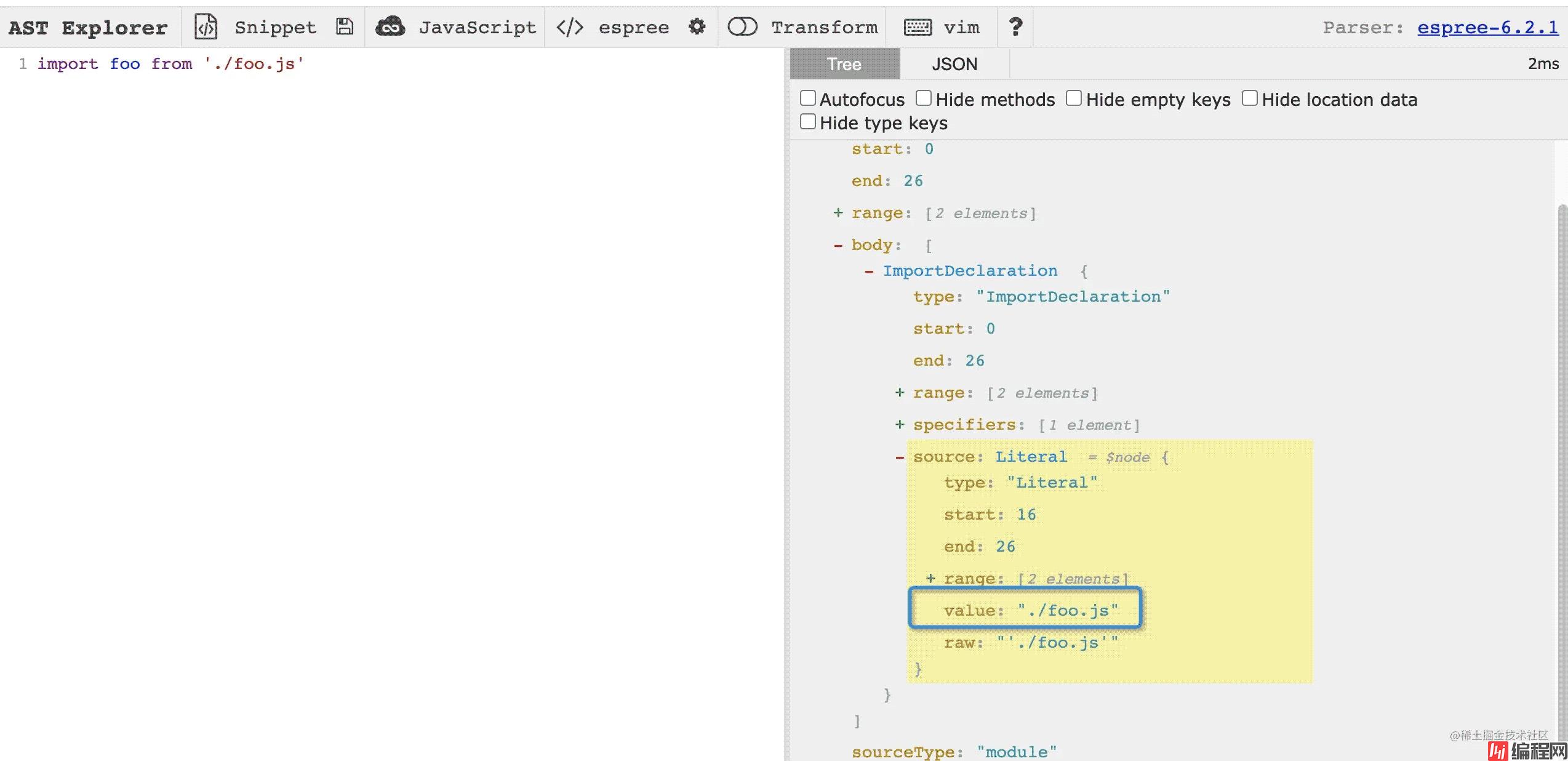
接下来的思路就是把上面的代码转化成 ast,接着去取上图框框里那个字段。
const fs = require('fs');
const babylon = require('babylon');
const traverse = require('babel-traverse').default;
function createAssert(filename) {
const dependencies = [];
const content = fs.readFileSync(filename, {
encoding: 'utf-8'
});
const ast = babylon.parse(content, {
sourceType: 'module',
});
traverse(ast, {
ImportDeclaration: ({node}) => {
dependencies.push(node.source.value);
}
})
console.log(dependencies); // [ './foo.js' ]
return content;
}
上面我们做的事情就是把当前的文件读到,然后再把当前文件的依赖加到一个叫做 dependencies 的数组里面去。
然后,这里的 createAssert 只返回源代码还不够,再完善一下:
let id = 0;
function getId() { return id++; }
function createAssert(filename) {
const dependencies = [];
const content = fs.readFileSync(filename, {
encoding: 'utf-8'
});
const ast = babylon.parse(content, {
sourceType: 'module',
});
traverse(ast, {
ImportDeclaration: ({ node }) => {
dependencies.push(node.source.value);
}
})
return {
id: getId(),
code: content,
filename,
dependencies,
mapping: {},
};
}
假如对主入口文件 index.js 调用,得到的结果会是(先忽略 mapping):
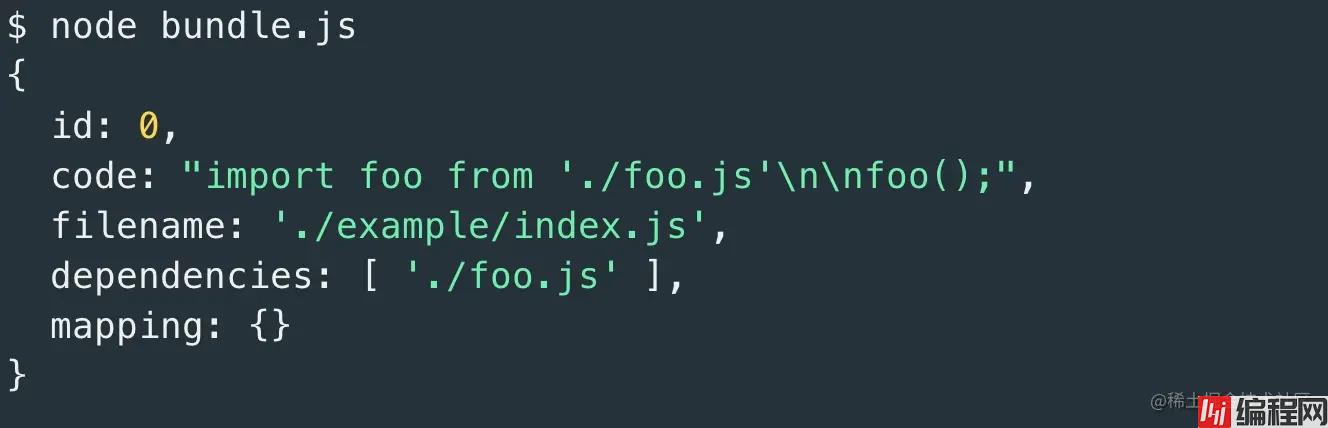
我们不能只对主入口文件做这件事,得需要对所有在主入口这链上的文件做,上面 createAssert 针对一个文件做,我们基于这个函数,建一个叫做 crateGraph 的函数,里面进行递归调用。
不妨先直接看结果,来了解这个函数是做什么的。
运行这个函数,得到的结果如下图所示:

mapping 字段做了当前项 dependencies 里的文件和其他项的映射,这个,我们在后面会用到。
function createGraph(entry) {
const modules = [];
createGraphImpl(
path.resolve(__dirname, entry),
);
function createGraphImpl(absoluteFilePath) {
const assert = createAssert(absoluteFilePath);
modules.push(assert);
assert.dependencies.forEach(relativePath => {
const absolutePath = path.resolve(
path.dirname(assert.filename),
relativePath
);
const id = createGraphImpl(absolutePath);
assert.mapping[relativePath] = child.id;
});
return assert.id
}
return modules;
}
大家可以注意到,截图中,数组中每一项的 code 就是我们的源代码,但是这里面还留着 import 语句,我们先使用 babel 把它转成 commonJS 。
做的也比较简单,就是用 babel 修改 createAssert 中返回值的 code:
const code = transfORMFromAst(ast, null, {
presets: ['env'],
}).code
截取其中一项,结果变成了:
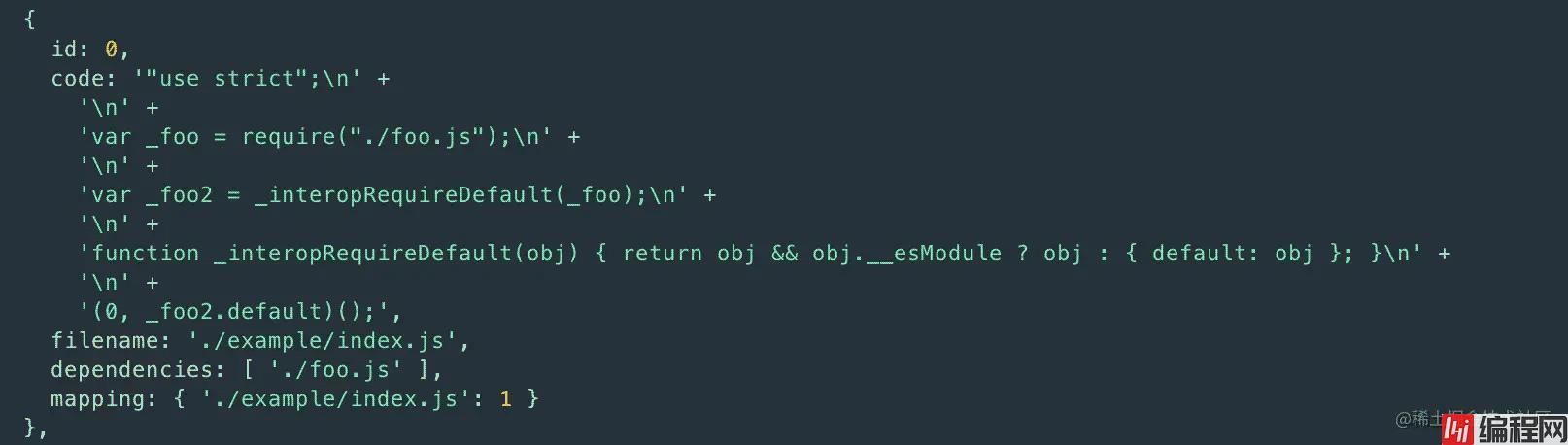
接下来要做的一步刚上来会比较难以理解,最关键的是我们会重写 require 函数,非常的巧妙,不妨先看:
我们新建一个函数 bundle 来处理 createGraph 函数得到的结果。
function bundle(graph) {
let moduleStr = '';
graph.forEach(module => {
moduleStr += `
${module.id}: [
// require,module,exports 作为参数传进来
// 在下面我们自己定义了,这里记作【位置 1】
function(require, module, exports) {
${module.code}
},
${JSON.stringify(module.mapping)}
],
`
})
const result = `
(function(modules){
function require(id) {
const [fn, mapping] = modules[id];
// 这其实就是一个空对象,
// 我们导出的那个东西会挂载到这个对象上
const module = { exports: {} }
// fn 就是上面【位置 1】 那个函数
fn(localRequire, module, module.exports)
// 我们使用 require 是 require(文件名)
// 所有这里要做一层映射,转到 require(id)
function localRequire(name) {
return require(mapping[name])
}
return module.exports;
}
require(0);
})({${moduleStr}})
`
return result;
}
最终的使用就是:
const graph = createGraph('./example/index.js');
const res = bundle(graph);
res 就是最终打包的结果,复制整段到控制台运行,可见成功输出了 'hello world':
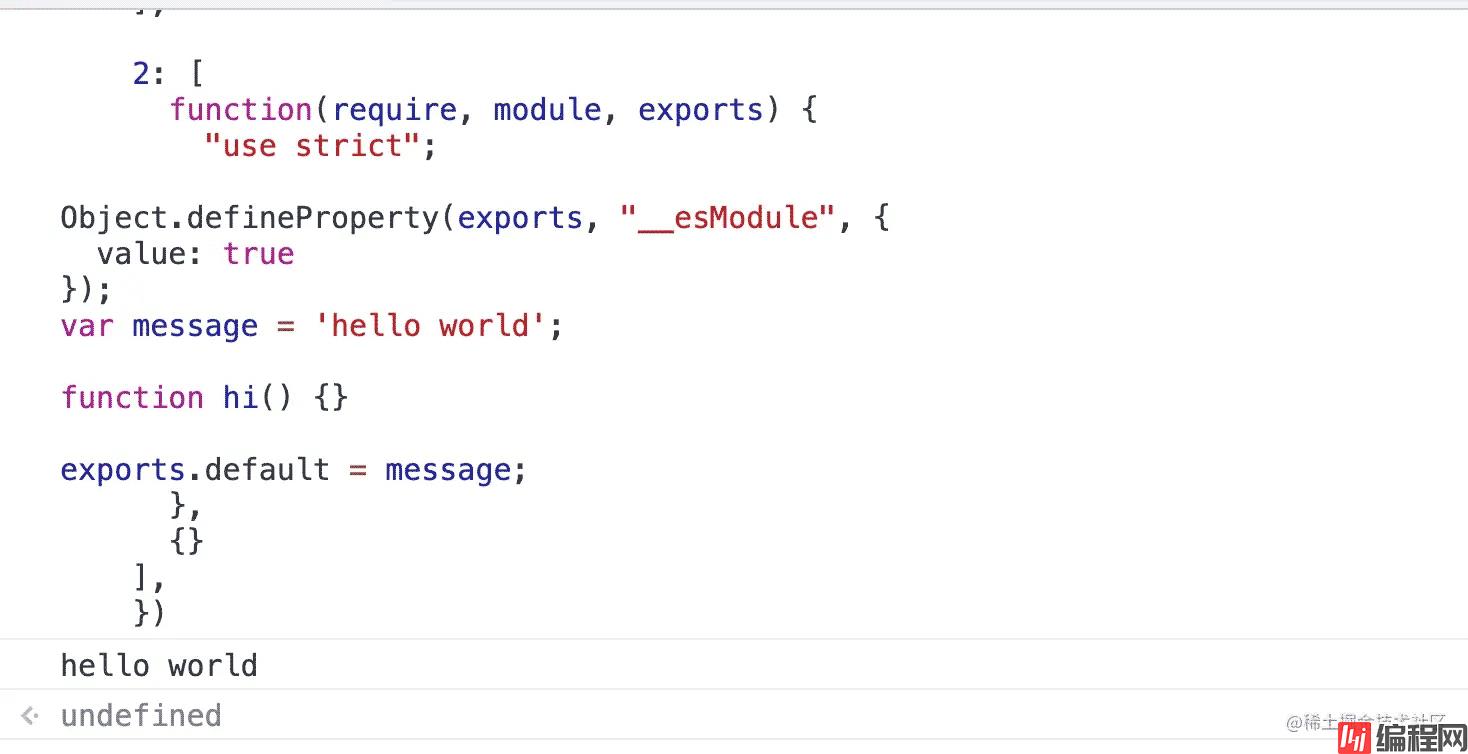
于是基本的功能就完成了,也就是 webpack 最基本的功能。
接下来解决包缓存的问题,目前来说,import 过的文件,会被转成 require 函数。每一次都会重新调用 require 函数,现在先办法把已经调用过的缓存起来:
function createGraph(entry) {
const modules = [];
const visitedAssert = {}; // 增加了这个对象
createGraphImpl(
path.resolve(__dirname, entry),
);
function createGraphImpl(absoluteFilePath) {
// 如果已经访问过了,那就直接返回
if (visitedAssert[absoluteFilePath]) {
return visitedAssert[absoluteFilePath]
}
const assert = createAssert(absoluteFilePath);
modules.push(assert);
visitedAssert[absoluteFilePath] = assert.id;
assert.dependencies.forEach(relativePath => {
const absolutePath = path.resolve(
path.dirname(assert.filename),
relativePath
);
// 优化返回值,只返回 id 即可
const childId = createGraphImpl(absolutePath);
assert.mapping[relativePath] = childId;
});
return assert.id
}
return modules;
}
function bundle(graph) {
let moduleStr = '';
graph.forEach(module => {
moduleStr += `
${module.id}: [
function(require, module, exports) {
${module.code}
},
${JSON.stringify(module.mapping)}
],
`
})
const result = `
(function(modules){
// 增加对已访问模块的缓存
let cache = {};
console.log(cache);
function require(id) {
if (cache[id]) {
console.log('直接从缓存中取')
return cache[id].exports;
}
const [fn, mapping] = modules[id];
const module = { exports: {} }
fn(localRequire, module, module.exports)
cache[id] = module;
function localRequire(name) {
return require(mapping[name])
}
return module.exports;
}
require(0);
})({${moduleStr}})
`
return result;
}
这个问题比较经典,如下所示,这个例子来自于 node.js 官网:
// filename: a.js
console.log('a starting');
exports.done = false;
const b = require('./b.js');
console.log('in a, b.done = %j', b.done);
exports.done = true;
console.log('a done');
// filename: b.js
console.log('b starting');
exports.done = false;
const a = require('./a.js');
console.log('in b, a.done = %j', a.done);
exports.done = true;
console.log('b done');
// filename: main.js
console.log('main starting');
const a = require('./a.js');
const b = require('./b.js');
console.log('in main, a.done = %j, b.done = %j', a.done, b.done);
目前我们只支持额外把 import 语句引用的文件加到依赖项里,还不够,再支持一下 require。做的也很简单,就是 解析 AST 的时候再加入 require 语法的解析就好:
traverse(ast, {
ImportDeclaration: ({ node }) => {
dependencies.push(node.source.value);
},
CallExpression ({ node }) {
if (node.callee.name === 'require') {
dependencies.push(node.arguments[0].value)
}
}
})
然后,如果这样,我们直接运行,按照现在的写法处理不了这种情况,会报错栈溢出:

但是我们需要改的也特别少。先看官网对这种情况的解释:
When main.js loads a.js, then a.js in turn loads b.js. At that point, b.js tries to load a.js. In order to prevent an infinite loop, an unfinished copy of the a.js exports object is returned to the b.js module. b.js then finishes loading, and its exports object is provided to the a.js module.
解决方法就是这句话:『an unfinished copy of the a.js exports object is returned to the b.js module』。也就是,提前返回一个未完成的结果出来。我们需要做到也很简单,只需要把缓存的结果提前就好了。
之前我们是这么写的:
fn(localRequire, module, module.exports)
cache[id] = module;
接着改为:
cache[id] = module;
fn(localRequire, module, module.exports)
这样就解决了这个问题:

到现在我们就基本了解了它的实现原理,实现了一个初版的 webpack,撒花~
明白了它的实现原理,我才知道为什么网上说 webpack 慢是因为要把所有的依赖都先收集一遍,且看我们的 createGraph 。它确实是做了这件事。
但是写完发现,这个题材不适合写文章,比较适合视频或者直接看代码,你觉得呢?ಥ_ಥ
所有的代码在这个仓库
以上就是mini webpack打包基础解决包缓存和环依赖的详细内容,更多关于mini webpack包缓存环依赖的资料请关注编程网其它相关文章!
--结束END--
本文标题: mini webpack打包基础解决包缓存和环依赖
本文链接: https://www.lsjlt.com/news/168514.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-01-12
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0