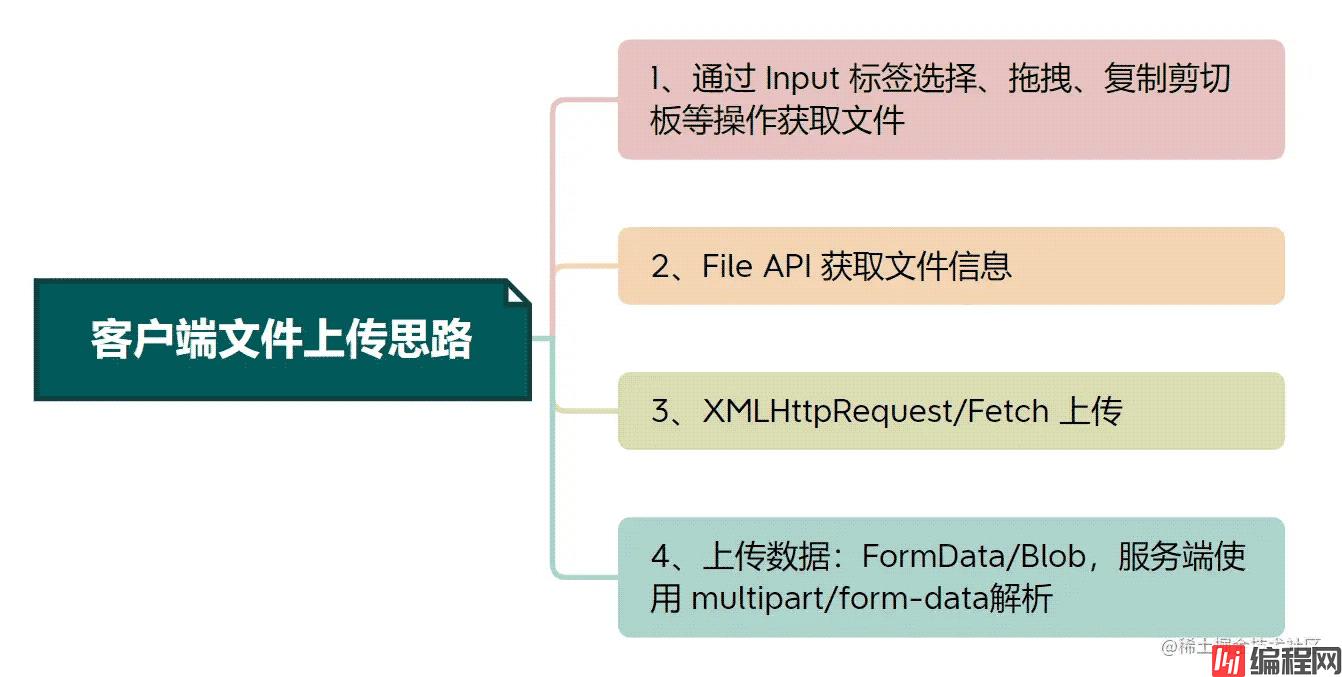
目录文件下载1.通过a标签点击直接下载2.open或location.href3.Blob和Base64文件上传文件上传思路File文件上传单个文件-客户端上传文件-服务端多文件上传
<a href="https:xxx.xlsx" rel="external nofollow" download="test">下载文件</a>
download属性标识文件需要下载且下载名称为test
如果有 Content-Disposition 响应头,则不需要设置download属性就能下载,文件名在响应头里面由后端控制
此方法有同源和请求headers鉴权的问题
window.open('xxx.zip');
location.href = 'xxx.zip';
需要注意 url 长度和编码问题
不能直接下载浏览器默认预览的文件,如txt、图片
function downloadFile(res, Filename) {
// res为接口返回数据,在请求接口的时候可进行鉴权
if (!res) return;
// IE及IE内核浏览器
if ("msSaveOrOpenBlob" in navigator) {
navigator.msSaveOrOpenBlob(res, name);
return;
}
const url = URL.createObjectURL(new Blob([res]));
// const fileReader = new FileReader(); 使用 Base64 编码生成
// fileReader.readAsDataURL(res);
// fileReader.onload = function() { ...此处逻辑和下面创建a标签并释放代码一致,可从fileReader.result获取href值...}
const a = document.createElement("a");
a.style.display = "none";
a.href = url;
a.download = Filename;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url); // 释放blob对象
}
注意 请求发送的时候注明 responseType = "blob",如无设置则需要 new Blob的时候传入第二个参数,如
new Blob([res], { type: xhr.getResponseHeader("Content-Type") });
此方法可以解决请求headers鉴权和下载浏览器默认直接预览的文件,并得知下载进度

<input id="uploadFile" type="file" accept="image
async function getFileHash(fileList) {
console.time("filehash");
const spark = new SparkMD5.ArrayBuffer();
// 获取全部内容
const result = fileList.map((item, key) => {
return getFileContent(item.file);
});
try {
const contentList = await Promise.all(result);
for (let i = 0; i < contentList.length; i++) {
spark.append(contentList[i]);
}
// 生成指纹
const res = spark.end();
console.timeEnd("filehash");
return res;
} catch (e) {
console.log(e);
}
}
async function getFileHash2(fileList) {
console.time("filehash");
const spark = new SparkMD5.ArrayBuffer();
// 获取全部内容
const content = await getFileContent(fileList);
try {
spark.append(content);
// 生成指纹
const result = spark.end();
console.timeEnd("filehash");
return result;
} catch (e) {
console.log(e);
}
}
function getFileContent(file) {
return new Promise((resolve, reject) => {
const fileReader = new FileReader();
// 读取文件内容
fileReader.readAsArrayBuffer(file);
fileReader.onload = (e) => {
// 返回读取到的文件内容
resolve(e.target.result);
};
fileReader.onerror = (e) => {
reject(fileReader.error);
fileReader.abort();
};
});
}
async function uploadChunks(chunks, fileName) {
const requestList = chunks
.map(({ chunk, hash, fileHash, index, fileCount, size, totalSize }) => {
//生成每个切片上传的信息
const fORMData = new FormData();
formData.append("hash", hash);
formData.append("index", index);
formData.append("fileCount", fileCount);
formData.append("size", size);
formData.append("splitSize", DefaultChunkSize);
formData.append("fileName", fileName);
formData.append("fileHash", fileHash);
formData.append("chunk", chunk);
formData.append("totalSize", totalSize);
return { formData, index };
})
.map(async ({ formData, index }) =>
singleRequest({
url: "Http://127.0.0.1:3000/uploadBigFile",
data: formData,
})
);
//全部上传
await Promise.all(requestList);
}
function singleRequest({ url, method = "post", data, headers = {} }) {
return new Promise((resolve) => {
const xhr = new XMLHttpRequest();
xhr.open(method, url);
Object.keys(headers).forEach((key) => xhr.setRequestHeader(key, headers[key]));
xhr.send(data);
xhr.onload = (e) => {
resolve({
data: e.target.response,
});
};
});
}
window.upload = {
start: start,
};
...
import { checkFileIsMerge, chunkMerge } from "./upload";
const multiparty = require("multiparty");
const fse = require("fs-extra");
// 上传成功后返回URL地址
const resourceUrl = `http://127.0.0.1:${port}/`;
// 存储文件目录
const uploadDIr = path.join(__dirname, "/upload");
//设置静态访问目录
app.use(express.static(uploadDIr));
const extractExt = (filename) => filename.slice(filename.lastIndexOf("."), filename.length); // 提取后缀名
app.post("/uploadBigFile", function (req, res, _next) {
const multipart = new multiparty.Form();
multipart.parse(req, async (err, fields, files) => {
if (err) {
console.error(err);
return res.JSON({
code: 5000,
data: null,
msg: "上传文件失败",
});
}
//取出文件内容
const [chunk] = files.chunk;
//当前chunk 文件hash
const [hash] = fields.hash;
//大文件的hash
const [fileHash] = fields.fileHash;
//大文件的名称
const [fileName] = fields.fileName;
//切片索引
const [index] = fields.index;
//总共切片个数
const [fileCount] = fields.fileCount;
//当前chunk 的大小
// const [size] = fields.size;
const [splitSize] = fields.splitSize;
//整个文件大小
const [totalSize] = fields.totalSize;
const saveFileName = `${fileHash}${extractExt(fileName)}`;
//获取整个文件存储路径
const filePath = path.resolve(uploadDIr, saveFileName);
const chunkDir = path.resolve(uploadDIr, fileHash);
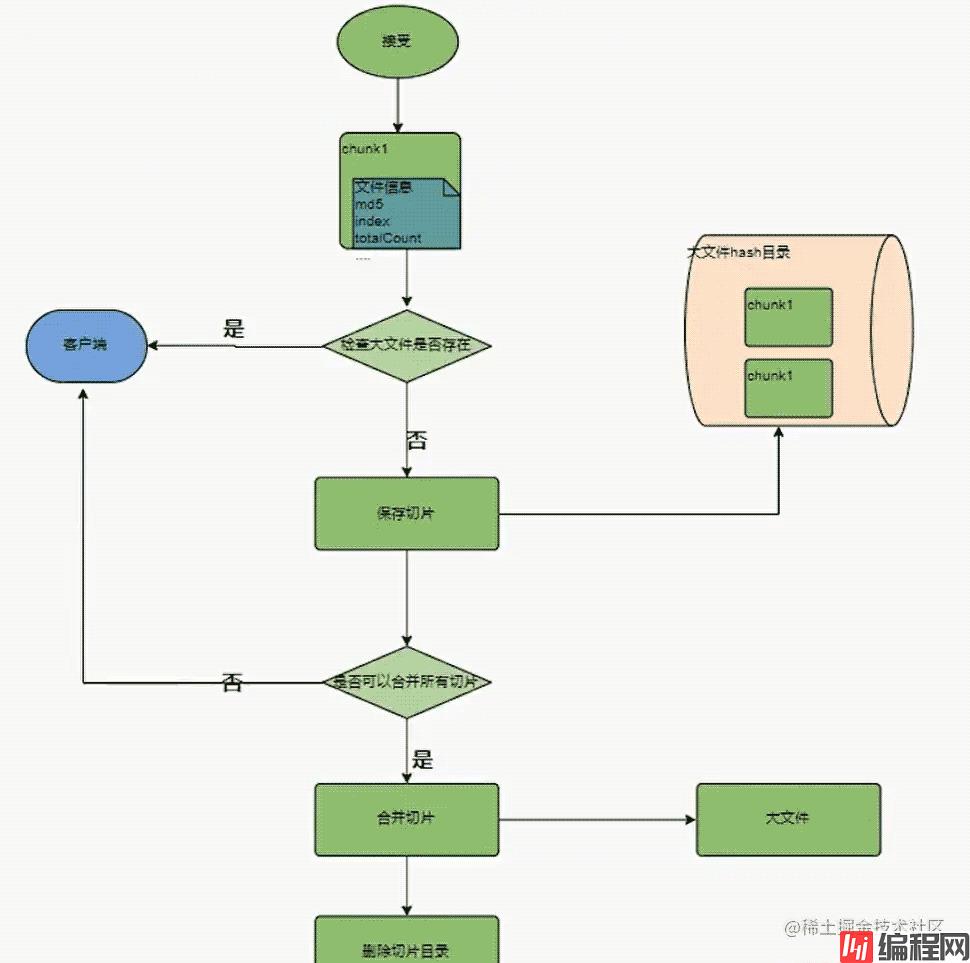
// 大文件存在直接返回,根据内容hash存储,可以实现后续秒传
if (fse.existsSync(filePath)) {
return res.json({
code: 1000,
data: { url: `${resourceUrl}${saveFileName}` },
msg: "上传文件已存在",
});
}
// 切片目录不存在,创建切片目录
if (!fse.existsSync(chunkDir)) {
await fse.mkdirs(chunkDir);
}
const chunkFile = path.resolve(chunkDir, hash);
if (!fse.existsSync(chunkFile)) {
await fse.move(chunk.path, path.resolve(chunkDir, hash));
}
const isMerge = checkFileIsMerge(chunkDir, Number(fileCount), fileHash);
if (isMerge) {
//合并
await chunkMerge({
filePath: filePath,
fileHash: fileHash,
chunkDir: chunkDir,
splitSize: Number(splitSize),
fileCount: Number(fileCount),
totalSize: Number(totalSize),
});
return res.json({
code: 1000,
data: { url: `${resourceUrl}${saveFileName}` },
msg: "文件上传成功",
});
} else {
return res.json({
code: 200,
data: { url: `${resourceUrl}${filePath}` },
msg: "文件上传成功",
});
}
});
});
upload.ts
const fse = require("fs-extra");
const path = require("path");
const pipeStream = (path, writeStream) =>
new Promise((resolve) => {
const readStream = fse.createReadStream(path);
readStream.on("end", () => {
// fse.unlinkSync(path);
resolve(null);
});
readStream.pipe(writeStream);
});
export async function chunkMerge({
filePath,
fileHash,
chunkDir,
splitSize,
fileCount,
totalSize,
}) {
const chunkPaths = await fse.readdir(chunkDir);
//帅选合适的切片
const filterPath = chunkPaths.filter((item) => {
return item.includes(fileHash);
});
//数量不对,抛出错误
if (filterPath.length !== fileCount) {
console.log("合并错误");
return;
}
// 根据切片下标进行排序,方便合并
filterPath.sort((a, b) => a.split("-")[1] - b.split("-")[1]);
await Promise.all(
chunkPaths.map((chunkPath, index) => {
//并发写入,需要知道开始和结束位置
let end = (index + 1) * splitSize;
if (index === fileCount - 1) {
end = totalSize + 1;
}
return pipeStream(
path.resolve(chunkDir, chunkPath),
// 指定位置创建可写流
fse.createWriteStream(filePath, {
start: index * splitSize,
end: end,
})
);
})
);
//删除所有切片
// fse.rmdirSync(chunkDir); // 合并后删除保存切片的目录
return filePath;
}
export function checkFileIsMerge(pathName, totalCount, hash) {
var dirs = [];
//同步读取切片存储目录
const readDir = fse.readdirSync(pathName);
//判断目录下切片数量 小于 总切片数,不能合并
if (readDir && readDir.length < totalCount) return false;
//获取目录下所有真正属于该文件的切片,以大文件hash为准
(function iterator(i) {
if (i == readDir.length) {
return;
}
const curFile = fse.statSync(path.join(pathName, readDir[i]));
//提出目录和文件名不包含大文件hash的文件
if (curFile.isFile() && readDir[i].includes(hash + "")) {
dirs.push(readDir[i]);
}
iterator(i + 1);
})(0);
//数量一直,可以合并
if (dirs.length === totalCount) {
return true;
}
return false;
}
这里的大文件上传有几处问题,我没有解决,留给各位思考啦
以上就是javascript进阶之前端文件上传和下载示例详解的详细内容,更多关于JavaScript前端文件上传下载的资料请关注编程网其它相关文章!
--结束END--
本文标题: JavaScript进阶之前端文件上传和下载示例详解
本文链接: https://www.lsjlt.com/news/168794.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-01-12
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0