




本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘
1. 重复值的处理
利用drop_duplicates()函数删除数据表中重复多余的记录, 比如删除重复多余的ID.
1 import pandas as pd
2 df = pd.DataFrame({"ID": ["A1000","A1001","A1002", "A1002"],
3 "departmentId": [60001,60001, 60001, 60001]})
4 df.drop_duplicates()
2. 缺失值的处理
缺失值是数据中因缺少信息而造成的数据聚类, 分组, 截断等
2.1 缺失值产生的原因
主要原因可以分为两种: 人为原因和机械原因.
1) 人为原因: 由于人的主观失误造成数据的缺失, 比如数据录入人员的疏漏;
2) 机械原因: 由于机械故障导致的数据收集或者数据保存失败从而造成数据的缺失.
2.2 缺失值的处理方式
缺失值的处理方式通常有三种: 补齐缺失值, 删除缺失值, 删除缺失值, 保留缺失值.
1) 补齐缺失值: 使用计算出来的值去填充缺失值, 例如样本平均值.
使用fillna()函数对缺失值进行填充, 使用mean()函数计算样本平均值.
1 import pandas as pd
2 import numpy as np
3 df = pd.DataFrame({'ID':['A10001', 'A10002', 'A10003', 'A10004'],
4 "Salary":[11560, np.NaN, 12988,12080]})
5 #用Salary字段的样本均值填充缺失值
6 df["Salary"] = df["Salary"].fillna(df["Salary"].mean())
7 df
2) 删除缺失值: 当数据量大时且缺失值占比较小可选用删除缺失值的记录.
示例: 删除entrytime中缺失的值, 采用dropna函数对缺失值进行删除:
1 import pandas as pd
2 df = pd.DataFrame({"ID": ["A1000","A1001","A1002"],
3 "entrytime": ["2015-05-06",pd.NaT,"2016-07-01" ]})
4 df.dropna()
3) 保留缺失值.
3. 删除前后空格
使用strip()函数删除前后空格.
1 import pandas as pd
2 df = pd.DataFrame({"ID": ["A1000","A1001","A1002"],
3 "Surname": [" Zhao ","Qian"," Sun " ]})
4 df["Surname"] = df["Surname"].str.strip()
5 df
4. 查看数据类型
查看所有列的数据类型使用dtypes, 查看单列使用dtype, 具体用法如下:
1 import pandas as pd
2 df = pd.DataFrame({"ID": [100000,100101,100201],"Surname": [" Zhao ","Qian"," Sun " ]})
3 #查看所有列的数据类型
4 df.dtypes
5 #查看单列的数据类型
6 df["ID"].dtype
5. 修改数据类型
使用astype()函数对数据类型进行修改, 用法如下
1 import pandas as pd
2 df = pd.DataFrame({"ID": [100000,100101,100201],"Surname": [" Zhao ","Qian"," Sun " ]})
3 #将ID列的类型转化为字符串的格式
4 df["ID"].astype(str)
6. 字段的抽取
使用slice(start, end)函数可完成字段的抽取, 注意start是从0开始且不包含end. 比如抽取前两位slice(0, 2).
1 import pandas as pd
2 df = pd.DataFrame({"ID": [100000,100101,100201],"Surname": [" Zhao ","Qian"," Sun " ]})
3 #需要将ID列的类型转换为字符串, 否则无法使用slice()函数
4 df["ID"]= df["ID"].astype(str)
5 #抽取ID前两位
6 df["ID"].str.slice(0,2)
7. 字段的拆分
使用split()函数进行字段的拆分, split(pat=None, n = -1, expand=True)函数包含三个参数:
第一个参数则是分隔的字符串, 默认是以空格分隔
第二个参数则是分隔符使用的次数, 默认分隔所有
第三个参数若是True, 则在不同的列展开, 否则以序列的形式显示.
1 import pandas as pd
2 df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
3 #对Surname_Age字段进行拆分
4 df_new = df["Surname_Age"].str.split("_", expand =True)
5 df_new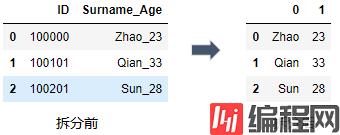
8. 字段的命名
有两种方式一种是使用rename()函数, 另一种是直接设置columns参数
1 import pandas as pd
2 df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
3 #第一种方法使用rename()函数
4 # df_new = df["Surname_Age"].str.split("_", expand =True).rename(columns={0: "Surname", 1: "Age"})
5 # df_new
6 #第二种方法直接设置columns参数
7 df_new = df["Surname_Age"].str.split("_", expand =True)
8 df_new.columns = ["Surname","Age"]
9 df_new两种方式同样的结果:

9. 字段的合并
使用merge()函数对字段进行合并操作.
1 import pandas as pd
2 df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
3 df_new = df["Surname_Age"].str.split("_", expand =True)
4 df_new.columns = ["Surname","Age"]
5 #使用merge函数对两表的字段进行合并操作.
6 pd.merge(df, df_new, left_index =True, right_index=True)
10. 字段的删除
利用drop()函数对字段进行删除.
1 import pandas as pd
2 df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
3 df_new = df["Surname_Age"].str.split("_", expand =True)
4 df_new.columns = ["Surname","Age"]
5 df_mer= pd.merge(df, df_new, left_index =True, right_index=True)
6 #drop()删除字段,第一个参数指要删除的字段,axis=1表示字段所在列,inplace为True表示在当前表执行删除.
7 df_mer.drop("Surname_Age", axis = 1, inplace =True)
8 df_mer删除Surname_Age字段成功:

11. 记录的抽取
1) 关系运算: df[df.字段名 关系运算符 数值], 比如抽取年龄大于30岁的记录.
1 import pandas as pd
2 df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
3 df_new = df["Surname_Age"].str.split("_", expand =True)
4 df_new.columns = ["Surname","Age"]
5 df_mer= pd.merge(df, df_new, left_index =True, right_index=True)
6 df_mer.drop("Surname_Age", axis = 1, inplace =True)
7 #将Age字段数据类型转化为整型
8 df_mer["Age"] = df_mer["Age"].astype(int)
9 #抽取Age中大于30的记录
10 df_mer[df_mer.Age > 30] 
2) 范围运算: df[df.字段名.between(s1, s2)], 注意既包含s1又包含s2, 比如抽取年龄大于等于23小于等于28的记录.
df_mer[df_mer.Age.between(23,28)]
3) 逻辑运算: 与(&) 或(|) 非(not)
比如上面的范围运算df_mer[df_mer.Age.between(23,28)]就等同于df_mer[(df_mer.Age >= 23) & (df_mer.Age <= 28)]
df_mer[(df_mer.Age >= 23 ) & (df_mer.Age <= 28)] 
4) 字符匹配: df[df.字段名.str.contains("字符", case = True, na =False)] contains()函数中case=True表示区分大小写, 默认为True; na = False表示不匹配缺失值.
1 import pandas as pd
2 import numpy as np
3 df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28"],"SpouseAge":[np.NaN,"32",np.NaN]})
4 #匹配SpouseAge中包含2的记录
5 df[df.SpouseAge.str.contains("2",na = False)] 
当na改为True时, 结果为:

5) 缺失值匹配: df[pd.isnull(df.字段名)]表示匹配该字段中有缺失值的记录.
1 import pandas as pd
2 import numpy as np
3 df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28"],"SpouseAge":[np.NaN,"32",np.NaN]})
4 #匹配SpouseAge中有缺失值的记录
5 df[pd.isnull(df.SpouseAge)]
12.记录的合并
使用concat()函数可以将两个或者多个数据表的记录合并一起, 用法: pandas.concat([df1, df2, df3.....])
1 import pandas as pd
2 df1 = pd.DataFrame({"ID": ["A10006","A10001"],"Salary": [12000, 20000]})
3 df2 = pd.DataFrame({"ID": ["A10008"], "Salary": [10000]})
4 #使用concat()函数将df1与df2的记录进行合并
5 pd.concat([df1, df2]) 
以上是部分内容, 还会持续总结更新....



0