



使用python的requests库简单爬取,使用xpath解析内容
可以获取个人信息、个人照片、成绩单和课表
GitHub地址:https://github.com/PythonerKK/GZCC-Spider
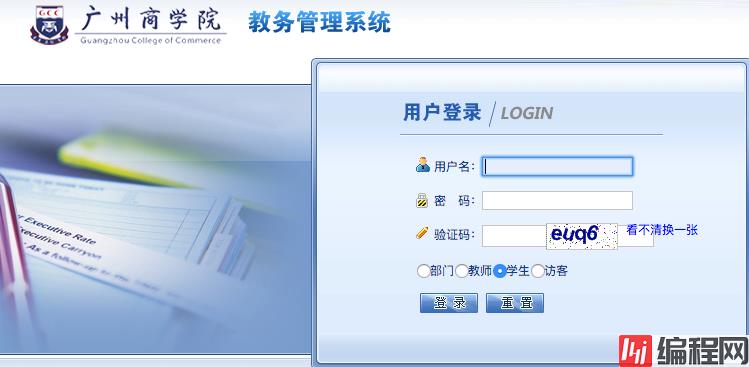
首先使用浏览器开发者调试工具找到登录页面的准确地址:Http://jwxw.gzcc.cn/default2.aspx
然后找到验证码的地址:http://jwxw.gzcc.cn/CheckCode.aspx
将验证码保存让用户输入即可
登录时发送POST请求,需要注意要提交一个叫__VIEWSTATE的字段,并且要携带cookies
发送POST后,如果登录成功则返回用户页面,判断即可
__VIEWSTATE=re.compile('name="__VIEWSTATE" value="(.*?)"').findall(data.text)[0]
resource=requests.post(login_url,data=post_data,cookies=cookies,headers=headers).text
if '活动报名' in resource:
print('登录成功!')
dom_tree=etree.html(resource)
name=dom_tree.xpath('//span[@id="xhxm"]/text()')
name=name[0]
print('欢迎回来 '+name)
return (cookies,name.split('同')[0])
else:
print('登录失败!')
exit(0)登录成功,输出:xxx同学,你好!
接下来需要获取个人信息、个人照片、成绩单
原理同上,注意携带cookies,成绩页面获取还需要携带__VIEWSTATE字段
效果如下:

全部代码:
# -*- coding: utf-8 -*-
"""
:author: KK
:url: http://github.com/PythonerKK
:copyright: © 2018 KK <705555262@qq.com.com>
:license: MIT, see LICENSE for more details.
"""
import requests
import re
from lxml import etree
from urllib.request import quote
import csv
def login(username,passWord):
'''
登录方正教务系统(广州商学院)
:param username: 学号
:param password: 密码
:return: tuple(cookies,name) 返回一个元组
'''
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWEBKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
}
login_url = 'http://jwxw.gzcc.cn/default2.aspx'
checkcode_url = 'http://jwxw.gzcc.cn/CheckCode.aspx'
data=requests.get(login_url)
__VIEWSTATE=re.compile('name="__VIEWSTATE" value="(.*?)"').findall(data.text)[0]
cookies=data.cookies
checkcode=requests.get(checkcode_url,cookies=cookies,headers=headers)
with open('checkcode.jpg','wb') as f:
f.write(checkcode.content)
code=input('请输入验证码:')
while '-' in code:
checkcode = requests.get(checkcode_url, cookies=cookies, headers=headers)
with open('checkcode.jpg', 'wb') as f:
f.write(checkcode.content)
code = input('请重新输入验证码:')
post_data={
'__VIEWSTATE':__VIEWSTATE,
'txtUserName':username,
'Textbox1':'',
'TextBox2':password,
'txtSecretCode':code,
'RadioButtonList1':'%D1%A7%C9%FA',
'Button1':'',
'lbLanguage':'',
'hidPdrs':'',
'hidsc':'',
}
resource=requests.post(login_url,data=post_data,cookies=cookies,headers=headers).text
if '活动报名' in resource:
print('登录成功!')
dom_tree=etree.HTML(resource)
name=dom_tree.xpath('//span[@id="xhxm"]/text()')
name=name[0]
print('欢迎回来 '+name)
return (cookies,name.split('同')[0])
else:
print('登录失败!')
exit(0)
def get_infORMation(cookies,username,name):
'''
获取个人信息,并导出照片
:param cookies: cookies
:param username: 学号
:param name: 姓名
:return: None
'''
#获取用户个人信息
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'Referer':'http://jwxw.gzcc.cn/xs_main.aspx?xh='+username
}
information_url='http://jwxw.gzcc.cn/xsgrxx.aspx?xh='+username+'&xm='+name+'&gnmkdm=N121501'
data=requests.get(information_url,cookies=cookies,headers=headers)
dom_tree=etree.HTML(data.text)
sex=dom_tree.xpath('//span[@id="lbl_xb"]/text()')[0]
born=dom_tree.xpath('//span[@id="lbl_csrq"]/text()')[0]
id=dom_tree.xpath('//span[@id="lbl_sfzh"]/text()')[0]
race=dom_tree.xpath('//span[@id="lbl_mz"]/text()')[0]
polity=dom_tree.xpath('//span[@id="lbl_zzmm"]/text()')[0]
academic=dom_tree.xpath('//span[@id="lbl_xy"]/text()')[0]
xi=dom_tree.xpath('//span[@id="lbl_xi"]/text()')[0]
major=dom_tree.xpath('//span[@id="lbl_zymc"]/text()')[0]
c=dom_tree.xpath('//span[@id="lbl_pyfx"]/text()')[0]
edu=dom_tree.xpath('//span[@id="lbl_CC"]/text()')[0]
phone=dom_tree.xpath('//input[@name="TELNUMBER"]/@value')[0]
school=dom_tree.xpath('//input[@name="byzx"]/@value')[0]
dorm=dom_tree.xpath('//input[@name="ssh"]/@value')[0]
email=dom_tree.xpath('//input[@name="dzyxdz"]/@value')[0]
loc_code=dom_tree.xpath('//input[@name="yzbm"]/@value')[0]
#获取用户照片
headers_image={
'Accept':'image/webp,image/apng,image*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'Referer':'http://jwxw.gzcc.cn/xsgrxx.aspx?xh='+username+'&xm='+quote(name)+'&gnmkdm=N121501',
}
image_url=re.compile('img id="xszp" src="(.*?)"').findall(data.text)
image_url='http://jwxw.gzcc.cn/'+image_url[0]
image_url=image_url.replace('amp;','')
image_data=requests.get(image_url,headers=headers_image,cookies=cookies)
with open('photo.png', 'wb') as f:
f.write(image_data.content)
print('照片导出成功!')
from docx import Document
from docx.shared import Inches
document = Document()
document.styles['Normal'].font.name = u'黑体'
document.add_heading(name+'的个人信息',0)
pic = document.add_picture('photo.png', width=Inches(1.5))
document.add_paragraph('个人资料')
document.add_paragraph('姓名:'+name)
document.add_paragraph('性别:' + sex)
document.add_paragraph('出生:' + born)
document.add_paragraph('身份证号:' + id)
document.add_paragraph('种族:' + race)
document.add_paragraph('政治面貌:' + polity)
document.add_paragraph('系部:' + xi)
document.add_paragraph('学院:' + academic)
document.add_paragraph('专业:' + major)
document.add_paragraph('班级:' + c)
document.add_paragraph('学历:' + edu)
document.add_paragraph('手机号:' + phone)
document.add_paragraph('毕业高中:' + school)
document.add_paragraph('宿舍号:' + dorm)
document.add_paragraph('邮箱号:' + email)
document.add_paragraph('邮编:' + loc_code)
document.save(username+'个人信息.docx')
print('个人资料导出成功!')
def get_curriculum(cookies,username,name):
'''
获取学生当前课表
:param cookies:cookies
:param username: 学号
:param name: 姓名
:return: None
'''
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'Referer':'http://jwxw.gzcc.cn/xs_main.aspx?xh='+username
}
curriculum_url='http://jwxw.gzcc.cn/xskbcx.aspx?xh='+username+'&xm='+password+'&gnmkdm=N121603'
data=requests.get(curriculum_url,cookies=cookies,headers=headers)
# import lxml
# dom_tree=etree.HTML(data.text)
# curriculum=dom_tree.xpath('//table[@id="Table1"]')
print(data.text)
def get_score(cookies,username,name):
'''
获取所有考试成绩,并导出csv
:param cookies: cookies
:param username: 学号
:param name: 姓名
:return: Boolean
'''
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'Referer':'http://jwxw.gzcc.cn/xs_main.aspx?xh='+username
}
first_url='http://jwxw.gzcc.cn/xscjcx.aspx?xh='+username+'&xm='+name+'&gnmkdm=N121605'
data=requests.get(first_url,cookies=cookies,headers=headers)
viewstate=re.compile('name="__VIEWSTATE" value="(.*?)"').findall(data.text)
viewstate=viewstate[0]
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'Referer':'http://jwxw.gzcc.cn/xscjcx.aspx?xh='+username+'&xm='+quote(name)+'&gnmkdm=N121605'
}
print(headers)
score_url='http://jwxw.gzcc.cn/xscjcx.aspx?xh='+username+'&xm='+name+'&gnmkdm=N121605'
post_data={
'__EVENTTARGET':'',
'__EVENTARGUMENT':'',
'__VIEWSTATE':viewstate,
'hidLanguage':'',
'ddlXN':'',
'ddlXQ':'',
'ddl_kcxz':'',
'btn_zcj':'%C0%FA%C4%EA%B3%C9%BC%A8'
}
scores=requests.post(score_url,cookies=cookies,headers=headers,data=post_data)
all=re.compile('<td>(.*?)</td><td>(\d+)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td><td></td><td></td>').findall(scores.text)
for i in all:
with open('score.csv', 'a', newline='') as f:
try:
csv_out=csv.writer(f,dialect='excel')
csv_out.writerow([i[0],i[1],i[2],i[3],i[4],i[5].replace(' ',''),i[6],i[7],i[8],i[9].replace(' ',''),i[10].replace(' ',''),i[11].replace(' ',''),i[12].replace(' ','')])
except Exception:
print('导出失败!')
return False
print('成绩导出成功!')
return True
def change_password(cookies,username,password,password1,password2):
'''
修改密码
:param cookies: cookies
:param username: 学号
:param password: 原密码
:param password1: 新密码
:param password2: 再次输入新密码
:return: None
'''
url='http://jwxw.gzcc.cn/mmxg.aspx?xh='+username+'&gnmkdm=N121502'
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'Referer':'http://jwxw.gzcc.cn/xs_main.aspx?xh='+username
}
data=requests.get(url,headers=headers,cookies=cookies)
viewstate=re.compile('name="__VIEWSTATE" value="(.*?)"').findall(data.text)
viewstate=viewstate[0]
postdata={
'Button1':'%D0%DE++%B8%C4',
'__VIEWSTATE':viewstate,
'TextBox2':password,
'TextBox3':password1,
'Textbox4':password2,
}
data=requests.post(url,data=postdata,cookies=cookies,headers=headers)
print('密码修改成功!')
if __name__ == '__main__':
print('广州商学院正方教务系统登录')
username=input('请输入学号:')
password=input('请输入密码:')
cookies,name=login(username,password)
#get_information(cookies,username,name)
#get_curriculum(cookies,username,name)
#get_score(cookies,username,name)
#change_password(cookies,username,password,password1=password,password2=password)

0