




(1)加法的两端只能是数字或者字符串。
如 print( 'kkk' + 12 + 'kkk' ) 是错误的,可修改为 print( 'kkk' + str(12) + 'kkk' ) 。类似 str() 的函数还有 int(),float()。
print(str(0)) #输出字符串的0
print(int('33'))
print(int(3.26)) #输出3
print(float(3.402))
print(float(23)) #输出23.0
print(int(input())) (2)在用于条件时,0、0.0、和 ' ' (空字符串) 被当作False,其他值被当作 True
name = ''
while not name: #只有输入有效的名字才跳出循环
name = input()
print('your name:' + name)
name = 0
while not name:
name = int(input())
print('最终结果:' + str(name)) #输入非0整数结束
- 指数:**。如 2 ** 3 = 8。
- 整除://。如 6 // 4 = 1。
- 除法:/。如 6 / 4 = 1.5。
- * 操作符表示乘法,但是当 * 和字符串连用时,表示将字符串复制的操作。如
print('Jack' * 2) #输出JackJack。同时注意 只能同整数配套使用- 其他操作同 C 语言一致。
and,not,or 代替了 C 语言的 && 和 ||
(1)if-else: 关键是通过控制代码块的缩进距离,python没有花括号
name = 'Jack'
age = 2
if(name == 'Jack'):
print('Hello,Jack')
if(age > 10):
print('>10')
else:
print('<10')
else:
print('Who are you?')
(2)while 循环
age = 5
while age < 9:
age += 1 #不支持 age++
print('age: ' + str(age))
if(age == 7):
break
print('end')
sum = 0
while True:
if sum == 3:
print('错误次数超过三次!')
break
else:
name = input()
if name != '11':
sum += 1
print('用户名错误,重新输入用户名:')
continue
else:
print('用户名正确,输入密码:')
pwd = input()
if pwd != '11':
print('密码错误,重新输入用户名:')
sum += 1
continue
(3)for 循环。range(开始,停止【不包括它】,步长)
i = 0
for i in range(0,10,2):
print(i) #0,2,4,6,8
(1)字符串相等否,可直接用 == 或者 != 判断
a = 'q'
s = 'qq'
if a != s:
print("yes")
else:
print("no")
(2)字符串的截取。同 C 语言的差别就是标号的不一致
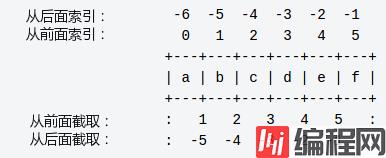
如上图所示,即 ‘abcdef’ 的下表是 0~5 或者 -6~-1。同时规则也常用:前闭后开。
str = 'abcdef'
print(str[0] + str[2]) #ac
print(str[-6] + str[-1]) #af
print(str[0:]) #abcdef
print(str[-3:]) #def
print(str[0:3]) #abc
print(str[3:2]) #无结果 不能逆序
print(str[1:-1]) #bcde
print(str[-6:2]) #ab
print(str[:2]) #ab
print(str[:]) #abcdef
(3)同样可使用 in 和 not in 操作符
str = '12345DDD6789'
print('ddd' in str) #True
print('012' not in str) #True
(4)数组是可变的,如append、insert、del等,但是字符串是 “不可变” ,如 str[0] = 'd' ,改变的方式是通过切边方式
str = '123456789'
str2 = str[0:2] + 'add' + str[6:8]
print(str2) #12add78
(5)字符串的输入。输入单引号、取消转义、多行字符串
#输入单引号
str = 'daf\'fdaf'
str2 = "fdaf'fda"
#因为\是转义符的意思,如果取消转义。即直接输出\
str3 = r'daf\'fdaf'
print(str, str2, str3, sep='*****')
#多行字符串。文本什么格式,输出也什么格式,一模一样
str4 = '''fdasfads\sssa
dsf'fdsa"\dfadasf
fadsfadsf'''
print(str4)
(6)常用方法 upper()、lower()、isupper()、islower()。这些方法都不是改变字符串本身,而是返回了一个新字符串
和数组的例如 a.insert(0,33) 是不一样的
str = 'fdaf898fdsa'
print(str.islower())
str = str.upper()
print(str) #FDAF898FDSA
(7)starswith()、endswith()。字面意思
(8)join()、split() 方法。前者参数是一个字符串列表,返回一个列表通过空格字母等串接之后的字符串。后者恰相反,传入字符串 -->> 字符串列表
str = {'ewe', 'wrewrw', '323'}
str = '&'.join(str)
print(str)
str2 = str.split('&')
print(str2)
str3 = '''fadsfas
fdsaf
fdsafffffff121ddds'''
print(str3.split('\n')) #按照行进行分割
(9)rjust()、ljust()、center()。对其文本用,前两者为右、左对齐,不足之处补充空格
str = '12345'
print(str.rjust(10))
print(str.ljust(10))
print(str.center(10,'*')) #居中 左右补充
(10)strip()、rstrip()、lstrip()
删除两端空格,单删除右 / 左边空格。又如:str.strip( ' abc ')。指只删除字符 ’abc‘ 的两端空格
(11)isdecimal()、isalpha()、isalnum()。
是否只包含数字字符且非空,只包含字母字符且非空,只包含字母和数字且非空。
(1)函数定义 def + 函数名(传参)
def hello(name): #传递的参数
print('你输入了:' + name)
i = 0
for i in range(0,3,1):
hello(input())
import random #导入函数,分为 import 和 from import(见补充)
def getNumber(j):
if j == 1:
print('随机数:' + str(j))
return 'A'
elif j == 2:
print('随机数:' + str(j))
return 'B'
else:
print('随机数:' + str(j))
return 'C'
i = 0
for i in range(0,3,1):
r = random.randint(1,3) #random.randint函数是产生 1<=*<=3 的整数
print(getNumber(r))
(2)print() 函数。print() 函数返回值为None
temp = print('测试返回值')
if temp == None:
print('yes',str(temp))print() 函数输出形式:
print('1','2','3') #空格自动分割
print('1', end='')
print('2') # print 函数自动会加入换行符,end = '' 就制止
print('1','2','3',sep='..') #输出通过 ‘..’ 分割
(3)global 语句。同 C 语言中一致,Python 中也分局部和全局变量,如果想通过局部函数修改全局变量,可以通过 global 函数
def k1():
global t
t = '已经修改1'
def k2():
t = '已经修改2'
t = '原始'
print(t) #原始
k2()
print(t) #原始
k1()
rint(t)p #已经修改1Python 中一个变量只能是局部或者全局变量,如
def k():
print(egg) #调用 K() 函数时,egg此句是全局变量,但在下一句中 egg 被重新声明被认为是局部变量。报错
egg = '123'
egg = '444'
k()
(4)try...except.. 函数
def k(divide):
try:
return 32 / divide
except:
return '报错'
print(k(3))
print(k(2))
print(k(0))
(5)函数返回多个值。书写形式上简单,但是返回多个值本质上返回的是一个元组,但是可通过多重赋值接受
def test():
return 'dfsa', 1221
a, b = test()
print(a, b) #dfsa 1221
(6)设置默认参数
def test(t, n=2): #如果传入2个参数,则n=2无效。否则n=2有效。默认参数必须放后面,否则会产生歧义,如此处,会分不清是t or n 没有传入参数
print(t * n)
test(2, 5)
test(2)
一个坑?:举例如下:
def add_end(L=[]):
L.append('end')
return L
print(add_end(['12', '23'])) #['12', '23', 'end']
print(add_end()) #['end'] ①
print(add_end()) #['end', 'end'] ②可以看出第一、二个例子,情况理想。但是第三个例子出现了两个 end 。这是由于第二次调用 add_end() 启用默认参数时,因为在①处调用之后,L= [ ] 已经被创建了,所以②处,没有重新创建一个新的对象,而是沿用了①处创建的对象,导致一二两处使用的默认对象是同一个。所以默认参数只能使用不变的对象。解决可如下:
def add_end(L = None):
if L == None:
L = []
L.append('end')
return L
print(add_end(['12', '23'])) #['12', '23', 'end']
print(add_end()) #['end']
print(add_end()) #['end']
(7)设置可变参数
其实设置可变参数的大部分场景,可以通过元组或者列表代以解决,但是使用可变参数稍微让代码优雅一些。那我就不客气啦,不用白不用。
举个求和例子一般写法:
#整数求和
def test(L):
sum = 0
for i in L:
sum += i
return sum
L = [1, 2, 3, 4]
print(test(L))这种写法的唯一看上去稍微不美妙的地方就是传参 L 。也就是必须传入列表。我们改造一番
#整数求和
def test(str ,*L):
print(str,end='')
sum = 0
for i in L:
sum += i
return sum
print(test("改造改造:",1 ,2,3,4)) #也可传入("dd",1,2,3,3,4,4,4)
#结果:改造改造:10
这次特意加了个 str 参数没有别的意思,就是为了举例说明可变参数的用法。即函数会自己匹配参数,从前往后先匹配 str-->"改造改造",随后是 *L ,只要见到 * 号,就会主动的将后面的参数自动包装成列表,也就是你不用提前组装成列表了。
(8)关键字参数
与上面的类似,只不过形式上是 **L(双星),这个就是会主动将你传入的参数组装成 dict 形式。如下:
#连接数据库
def test(str, *L, **T):
print(str, end='')
print(len(L))
for i in T.keys():
print(i, T.get(i))
test("密码位数:", 1, 2, 3, 密码= '123', 用户名= '123') #故意传入1,2,3测试*L。其次不加单引号
很明显可以看出,在便利 dict 的时候,因为**T 的存在,传入密码和用户名之后,已经自动组装成了字典形式 key-values。
密码位数---str
1,2,3------*L
{密码.....} --------**T
#连接数据库
def test(str, *L, **T):
print(str, end='')
print(len(L))
for i in T.keys():
print(i, T.get(i))
pwd = {'密码':'ddd'}
pas = [1,2,3]
test("密码位数:", 1, 2, 3, **pwd)
test("密码位数:", *pas, **pwd) #注意写法,如果上面test是*L,这里必须*pas,注意*号
def test2(str, L, T):
print(str, end='')
print(len(L))
for i in T.keys():
print(i, T.get(i))
test2("密码位数:", pas, pwd) #不用变量参数,关键参数
(9)命名关键字
这是在关键词上做进一步限制,也就是规定了传入的 dict 参数是具体哪些,不能多传或少传。
1 #连接数据库
2 def test(str, *, name, pwd):
3 print('name',name,'pwd',pwd)
4 pwd = {'name':123, 'pwd':111}
5
6 test("测试命名关键字:", **pwd) #不用变量参数,关键参数
即通过加将 * 号用逗号隔开,而 * 号之后的 name 和 pwd 就是必须要传入的参数了。如果第四行的 pwd 改成: pwd = {'name':123, 'pwd':111, 'user':'Bob'} 多了user,会报错。改成:pwd = {'name':123} 少了 pwd 也同样报错。
写法有很多:
#连接数据库
def test(str, *, name, pwd): # * 号是分割符
print('name',name,'pwd',pwd)
test("测试命名关键字:", name=123, pwd=111) #不组装pwd了,让函数自己组装
同时如果,我们在结合第七点 的可变参数,如果已经有了可变参数,写法略不同,就是 不需要将在写 * 号分隔符了,直接写参数
1 #连接数据库
2 def test(str, *L, name, pwd): #可变参数
3 print(str, end='')
4 print(len(L))
5 print('name=',name,'pwd=',pwd)
6
7 test("密码位数:", 1, 2, 3, name=123, pwd=123) #1,2,3传入当作可变参数,函数将其组装成列表 。这种写法同样在第七行只能传入name 和 pwd 两个key-value 多了或者少了就是报你的错,毫不留情。
。这种写法同样在第七行只能传入name 和 pwd 两个key-value 多了或者少了就是报你的错,毫不留情。
加大力度:
Http://n3xtchen.GitHub.io/n3xtchen/python/2014/08/08/python-args-and-kwargs
https://www.liaoxuefeng.com/wiki/1016959663602400/1017261630425888#0
(1)用 len() 取得列表长度
直接通过下表修改值
a = [12, 'dd', 2]
print(len(a))
a[0] = 'ppp'
print(a)
(2)数组的连接、复制、删除
a = [12, 'dd', 2]
b = ['14']
d = b
c = b + a
e = b * 3
print(d,c,e,sep='.....') #['14'].....['14', 12, 'dd', 2].....['14', '14', '14']
del a[0] #删除操作
print(a) #['dd', 2]
(3)数组循环
catName = []
while True:
print('请输入第' + str(len(catName) + 1) + '只猫名字')
name = input()
if name == '': #直接敲回车
break
catName += [name]
print('共'+ str(len(catName)) + '只猫')
for name in catName: #没有使用range
print(' ' + name)catName = ['fdas','fd','ioo','wew','dfs']
for i in range(0,len(catName),2): #常用 range(len(catName)) 遍历整个数组
print(' ' + catName[i]) #fdas ioo dfs
(4)某个值是否在数组中用,in 和 not in 判断
import random
catName = ['1','2','3','4','5']
i = 0
for i in range(0,4,1):
t = random.randint(1,10)
if(str(t) in catName):
print(str(t),'在')
if(str(t) not in catName):
print(str(t),'不在')
(5)多重赋值
name = ['1','2']
t,a = name
print(t,a) #输出 1 2
(6)index() 方法,append(),insert(),remove(),sort()。以及切片取值。
name = ['1','2','1','999']
print(name.index('1')) #返回在数组中第一个出现的下标 0
name.append('4') #在列表中添加新值
print(name) #['1', '2', '1', '999', '4']
name.insert(1,'999') #在下标 1 处添加新值
print(name) #['1', '999', '2', '1', '999', '4']
name.remove('999') #删除在数组中第一次出现的999,若不存在999则报错
print(name) #['1', '2', '1', '999', '4']
del name[0]
print(name) #['2', '1', '999', '4']
name.sort(reverse=True) #排序操作ASCII码进行排序,可直接name.sort()
print(name) #['999', '4', '2', '1']
# 切片取值
print(name[:4:2]) #['1', '1']。取前4个,每隔2个取一个print(name[::3]) #['1', '999']。取全部数,每隔3个取一个
(1)元组和数组十分类似,主要区别有两点如下
- 元组输入时使用 () 而非 [ ]
a = (1,2,3)
print(a) #输出 (1,2,3)
print(a[2]) #3- 元组中的值不能修改,和字符串类似。所以 Python 可以以更优化的方式对待元组。同时,元组中如果之后一个值,通过加逗号来标识其是元组。(否则Python认为你只是普通括号)
a = (1,) #不加逗号,下句出错.当元组长度只为1时使用
print(a[0])
(2)用 list 和 tuple 函数来转换类型
常用于返回元组或者列表形式。
str = '1234'
print(list(str)) #['1', '2', '3', '4']
print(tuple(str)) #('1', '2', '3', '4')
str2 = ('12','dd')
print(list(str2)) #['12', 'dd']
(1)Python 中关于引用的知识点同 C 语言中十分类似,C 语言中如:int a = 3,实际上 a 形参是通过地址找到存储 3 整个数字的 “格子
而数组 a[1,2,3] 则直接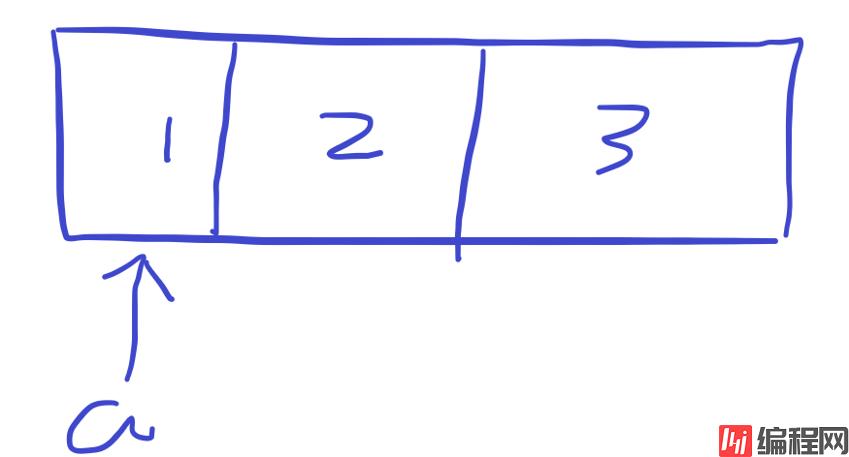 。这和 Python 几乎一致。所以在 Python 中,普通类型的复制如 b = a 复制值,而数组之间复制,复制的是引用(即地址)。同样,如果在传递给函数时,传递的参数是数组,则会改变原数组,传递的是一般数据类型,则不会修改原值,如:
。这和 Python 几乎一致。所以在 Python 中,普通类型的复制如 b = a 复制值,而数组之间复制,复制的是引用(即地址)。同样,如果在传递给函数时,传递的参数是数组,则会改变原数组,传递的是一般数据类型,则不会修改原值,如:
def test(str):
str += 'g'
def test2(name):
del name[0]
str = 'ddd'
test(str)
print(str) #ddd 未修改
name = [1,2,3]
test2(name)
print(name) #[2, 3] #[2, 3] 修改
(2)在处理列表时,传入的是引用,如果只想传入值,即修改了数组而不影响原有函数,通过 copy() 实现。如果要复制的列表中还包含列表,使用 deepcopy() 。
1 import copy
2
3 name = [1,2,3,[1,2,3]]
4
5 a = name
6 b = copy.copy(name)
7 c = copy.deepcopy(name)
8
9 a.append('aaa')
10 print(name) #[1, 2, 3, [1, 2, 3], 'aaa'] 说明对name原列表有效,a列表改变name列表也改变了
11
12 b.append('bbb')
13 print(name) #[1, 2, 3, [1, 2, 3], 'aaa'] 说明name原对列表有效
14
15 b[3].append('444')
16 print(name) #[1, 2, 3, [1, 2, 3, '444'], 'aaa'] 说明原列表有效
17
18 c.append('555')
19 print(name) #[1, 2, 3, [1, 2, 3, '444'], 'aaa'] 说明无效
(1)字典即 Map
由键值对组成。字典不同于列表,字典中表项是不排序的,如(字典不能排序)
t = [1,2,3]
e = [2,1,3]
print(t == e) #False
g = {'k':'j', 'kk':'jj'}
h = {'kk':'jj', 'k':'j'}
print(g == h) #True
print('k' in g) #True 判断 key 是否存在(2)keys() 方法,values() 方法,items() 方法
g = {'k':'j', 'kk':'jj'}
for v in g.keys(): #key
print(v)
for t in g.values(): #value
print(t)
for b in g.items(): #key-value
print(b) #输出元组
print(list(b)) #输出列表
for v,t in g.items(): #多重赋值
print('Key:',v,"Value",t)
(3)get() 方法
如果通过 key 值取值,存在 key 不存在的风险,get() 函数可以设置一个默认返回值,避免错误。
g = {'name':'Tom', 'age':'12'}
print('Welcom', g.get('name', 'Jack'), 'he lives in', g.get('home','shanghai')) #Jack 和 shanghai就是如果get不到值就,默认返回值
(4)setdefault() 方法
该方法可以设置默认 key 对应的 value。如果该 key 已经存在,则无效,如:
g = {'r':'rr','b':'bb'}
g.setdefault('k', 'kk')
print(g) #{'r': 'rr', 'b': 'bb', 'k': 'kk'} 修改有效
g.setdefault('k','mm')
print(g) #{'r': 'rr', 'b': 'bb', 'k': 'kk'} 修改无效有一个较实用的场景,统计字符:
msg = 'fadfasfasdfadsfs'
count = {}
for v in msg:
count.setdefault(v, 0) #很关键 设置为0,而不是1
count[v] += 1
print(count)
(1)①引入 re 模块。②按要求创建 regex 对象。③通过 regex 对象查找
import re #①
phoneNumRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d') #② \d 表示数字。此处查找目标格式如下行的电话号码。
mo = phoneNumRegex.search('My phone number is 123-123-1234') #③------------不过 search 只能匹配第一个符合的字符串。使用 findall 可以匹配到所有
if mo != None:
print(mo.group())
(2)利用括号进行分组
即在上一步基础上 r '(\d\d\d)-(\d\d\d)-(\d\d\d\d)' 添加括号,第一组括号就是第一组...,这样的目的是可以在获得整个电话号码的基础上,再细致的得到前三位,中间三位活末四位。
import re #①
phoneNumRegex = re.compile(r'(\d\d\d)-(\d\d\d)-(\d\d\d\d)') #②
mo = phoneNumRegex.search('My phone number is 111-222-3333') #③
if mo != None:
print(mo.group()) # 111-222-3333。或者用 mo.group(0)
print(mo.group(3)) #3333,第三组括号
print(mo.groups()) #可获得全部分组 ('111', '222', '3333')
arg1, arg2, arg3 = mo.groups() #用赋值
v1, v2 = mo.group(1), mo.group(0)
print(arg1, arg2, arg3, v1, v2)
(3)管道
①通过字符 ‘|’ 来匹配多个表达式中一个,类似 or 的作用。
import re
match = re.compile(r'Batman|Ironman') #匹配Batman 或者Ironman 字符
mo = match.search('Hi Ironman ABatman and CC Ironman')
print(mo.group())②也可以使用管道来匹配多个模式中的一个,如需要找112,113,114,前缀11均相同。
import re
match = re.compile(r'11(2|3|4)') #匹配112、113、114
mo = match.search('Hi 114 22811210114')
print(mo.group(), mo.group(1)) #114 4。前者输出完全匹配的完整内容,后者输出括号内匹配的文本4。
(4)用问号 ?实现可选匹配
import re
match = re.compile(r'11(2|3|4)?xx') #匹配112xx、113xx、114xx
mo = match.search('Hi 114xx')
print(mo.group()) #114xx
mo = match.search('Hi 11xx')
print(mo.group()) #11xx。因为(2|3|4)?表示这三个数字是可选内容。
(5)用星号匹配零次或任意多次。如果需要匹配星号,则通过添加斜杠完成
import re
match = re.compile(r'11(2|3|4|\*)*xx')
mo = match.search('Hi 114222*xx')
print(mo.group()) #114222*xx
mo = match.search('Hi 11xx')
print(mo.group()) #11xx
(6)用加号,则表示至少一次或者多次。与星号类似
import re
match = re.compile(r'11(2|3|4|\*\+)+xx')
mo = match.search('Hi 114222*+xx')
print(mo.group()) #114222*+xx
mo = match.search('Hi 11xx')
if mo == None:
print('没有匹配到') #没有匹配到
(7)通过添加花括号来限定匹配的次数
import re
e = re.compile(r'(11){2}') #{2}表示2次,{,2}表示0~2次,{2,}至少两次,{2,3}两次或者三次
mo = e.search('11231111232')
print(mo.group()) #1111还要注意一点,Python 默认是贪心策。如 (11){2,4},输入11111111,输出的是 11111111,而不是1111。但是如果(11){2,4}?则输出的是1111。问号的作用:①声明非贪心策略②表示可选分组。
(8)findall() 方法
search() 方法只能返回一个 match 对象。①如果在正则表达式中没有分组,则返回的是一个列表 ②有分组,则返回的是一个元组。如
import re
e = re.compile(r'(11){1}\d')
print(e.search('11231111432').group()) #112。只能找到第一次出现且符合要求的
print(e.findall('11231111432')) #['11', '11']。因为有分组即有括号,所以只能输出分组内容“(11)”,不能输出符合要求的112和114。此处分组为11
e2 = re.compile(r'1111\d')
print(e2.findall('1111231111232')) #['11112', '11112']。没有分组,这是最理想最期待看到的结果
e3 = re.compile(r'(11){2}\d')
print(e3.findall('1111231111232')) #['11', '11']。(11){2},即此处分组为 11,括号即分组
e4 = re.compile(r'(\d\d\d)-(\d\d\d)-(\d\d\d\d)')
print(e4.findall('cell 123-456-7890 work: 111-222-3333')) #[('123', '456', '7890'), ('111', '222', '3333')]
(9)字符的分类
- \d 0~9 任意数字
- \D 除了 0~9 之外任意数字
- \w 字母,数字,下划线
- \W 除......
- \s 匹配空白
- \S 除......
(10)建立自己的字符分类
- 用方括号定义自己的字符分类,如,[aeiou]
- 用短横线表示字母或者数组的范围,如,[0-1a-zA-Z]。注意:普通正则表达式符号在方括号内不会被解释,不需要加 \ 进行转义
- ^ 表示非。[ ^aeiou ],正好和第一条相反。在字符左方括号后加。
(11)插入字符和美元字符
可以在正则表达式开始处使用插入符号 ^ ,表明匹配必须发生在被查找文本开始处。类似的,可以在正则表达式末尾加上 $ ,表示该字符串必须以这个正则表达式模式结束。
import re
begin = re.compile(r'^hello')
print(begin.search('hello').group())
end = re.compile(r'\d$')
print(end.search('da233').group())
a = re.compile(r'^\d+$') #从头到尾是数字。加号关键,表示个数不限制
print(a.search('121t4')) #None
print(a.search('12164').group()) #12164
(12)通配符
“ .” (句号) 是通配符,匹配除了换行之外的所有字符,但是只匹配一位。要匹配真正的句号,需要用转义符:\ . 。
(13)用点-星匹配除换行符之外所有字符
点可以匹配除了换行符之外的所有字符,星表示前面的字符出现0次或多次。
import re
test = re.compile(r'<.*?>')
mo = test.search('<To serve man> for dinner.>')
print(mo.group())
test2 = re.compile(r'<.*>') #去掉问号,默认贪心策略
mo = test2.search('<To serve man> for dinner.>')
print(mo.group())
通过传入参数:re.DOTALL 来做到匹配换行符:
import re
test2 = re.compile('.*')
mo = test2.search('<To serve man>\n for dinner.>')
print(mo.group()) #<To serve man>
test3 = re.compile('.*', re.DOTALL)
mo = test3.search(r'<To serve man>\n for dinner.>')
print(mo.group()) #<To serve man>\n for dinner.>
(点击图片查看原文)

(14)不区分大小写的匹配
通过传入参数:re.IGNORECASE 或 re.I 。
import re
t = re.compile('aaBB', re.I)
print(t.search('AAbbdd').group()) #AAbb
(15)用 sub() 方法替换字符串
即找到目标文字段,并替换,返回替换之后的字符串 。
import re
t = re.compile('Alice \w+') #表示Alice+空格+一个单词(\w => 字母数字下划线)
print(t.sub('替换掉', 'Alice hello Pattern')) #替换掉 Pattern
有时候,可能需要使用匹配文本本身,作为替换的一部分。在 sub() 的第一个参数中,可以输入 \1, \2, \3.....。表示 “ 在替换中输入分组1、2、3..... 的文本”。(-----《Python编程快速上手》)
如,假定想要隐去密探的姓名,只显示他们姓名的第一个字母。可以使用正则表达式 Agent(\w)\w* ,传入 r ' \1**** ' 作为 sub() 的第一个参数。字符串中的 \1 将由分组 1 匹配的文本所替代,也就是正则表达式的(\w)分组。
import re
agentName = re.compile(r'Agent (\w)\w*') #写成 (\w)\w* 的形式完全为了取得首字母,若名字全部*代替,则直接 \w*
str = 'Agent Alice told Agent that Agent Jack knew Agent Bob was a double agent'
print(agentName.sub(r'\1****', str)) #A**** told t**** J**** knew B**** was a double agent
agentName = re.compile(r'Agent (\w)\w*(\w)')
print(agentName.sub(r'\1**\2', str)) #A**e told t**t J**k knew B**b was a double agent
(16)一个简单的应用
#电话号码/E-mail提取
import re
phoneNumb = re.compile(r'''
(\d{3}|\(d{3}\))? #①注意(需要转义符 ②表示:数字三个或者被括号包围的数字三个或者不存在--问号的意义
(\s|-\.)? #号码可通过空格,短线,或者"."--此处表示真正意义上的点,所以需要转义符。问号(表示0次或1次)和句点在正则表达式中均有特殊意义,所以需要转义符
(\d{3})
(\s|-\.)
(\d{4}) #形如(111)-223-4444
''')
email = re.compile(r'''
[a-zA-Z0-9.%+-]+ #Email 用户名可以是一个或多个字母/数字/./%/+/-
@
[a-zA-Z0-9.-]+ #域名
''')
(17)几个例子
①匹配隔至多三个数字之后必须要有一个逗号,如【42】【1,234】【6,222,111】---------------------------- r ’ ^ \d {1,3} (,\d{3}) * $ ‘ 。有点循环的味道
(1)① windows 下的倒斜杠和 OS X 下的正斜杠。前者是 / ,后者是 \。可以通过 os.path.join() 函数返回在 OS X 下目录格式。 ② os.getcwd() 得到当前工作目录。 ③ “ . (句点)” 表示当前目录。os.path.abspath() 将返回参数的绝对路径字符串。os.path.isabs() 将判断是否为绝对路径。os.path.relpath(path, start) 将返回path 相对于 start 的相对路径,start 默认是当前路径。
import os
print(os.path.join('usr', 'bin', 'spam')) #usr\bin\spam
print(os.getcwd()) #F:\Python
print(os.path.abspath('..')) #F:\
print(os.path.isabs('F:\\')) #True 错误写法:(r'F:\')
print(os.path.relpath('F:\\')) #..
print(os.path.relpath('F:\Python', 'F:\\')) #Python (path, start)
(2)os.makedirs() 创建新文件夹。 os.path.dirname(path) 返回最后一个斜杠之前的所有内容,os.path.basename(path) 返回最后一个斜杠之后的内容。 os.path.split() 返回一个元组正好是前两者的内容。如果想通过 \ 对路径进行分割,可以通过字符串的 split() 的分割方法。
import os
str = 'F:\\test\\test2'
#os.makedirs(str) #创建了F:\test\test2
print(os.path.dirname(str)) #F:\test
print(os.path.basename(str)) #test2
print(os.path.split(str)) #('F:\\test', 'test2') 输出以上两条合并的元组
print(os.path.sep) # \ 反斜杠
print(str.split(os.path.sep)) # ['F:', 'test', 'test2']。或者str.split('\\')
(3)查看文件大小和内容。os.listdir(path) , os.path.getsize(path)。
import os
print(os.path.getsize('F:\\Python\\Hello.py')) #得到文件大小
print(os.listdir('F:\\Python')) #得到整个目录
totalsize = 0
for file in os.listdir('F:\\Python'):
#totalsize += os.path.getsize('F:\\Python\\' + file) #集算整个目下文件字节数。写法二
totalsize += os.path.getsize(os.path.join('F:\\Python', file))
print(totalsize)
(4)检查路径的有效性。os.path.exists(path) 判断路径是否正确。os.path.isfile(path) 判断是否为文件。os.path.isdir(path) 是否是目录。
import os
str = 'F:\\Python\\Hello.py'
print(os.path.exists(str), os.path.isdir(str), os.path.isfile(str))
(5)Python 读取文件一样是 Open()、Read()、Close() 等基本步骤。
#读文件
import os
if os.path.isfile(".\\t.py") == True:
testFile = open(".\\t.py", encoding='UTF-8') #被读内容含中文。具体有待深究。先插眼
#content = testFile.read() #还方法将文件内容看成是单个大字符串。法一
content = testFile.readlines() #从该文件取得一个字符串列表,列表中的每个字符串就是文本的每一行。
print(content)#读写文件
import os
if os.path.isfile(".\\t.py") == True:
testFile = open(".\\t.py", 'a', encoding='UTF-8') #传入参数 w 写模式,a 添加模式。如果文件不存在,这两种模式会创建新文件
testFile.write('写入测试\n')
testFile.close() #写入完成之后必须关闭
testFile = open('.\\t.py', 'r', encoding='UTF-8') #重新打开,为了再次读
print(testFile.read())
(6)用 shelve 模块保存变量。主要功能是可以将一些变量存储在硬盘上,下次运行时直接加载它们。
import shelve
shelveFile = shelve.open('.\\data') #在当前目录创建。会产生三个文件 data.bak,data.dat,data.dir
cats = ['zo', 'to', 'po']
shelveFile['yo'] = cats #可以将 shelvesFile 看成key-value形式的Map
shelveFile.close()import shelve
shelveFile = shelve.open('.\\data')
print(shelveFile['yo']) #['zo', 'to', 'po']
shelveFile.close()



0