



selenium+phantomjs爬取京东商品信息
今天自己实战写了个爬取京东商品信息,和上一篇的思路一样,附上链接:https://www.cnblogs.com/cany/p/10897618.html
打开 Https://www.jd.com/ 首先不需要登陆就可搜索,淘宝不一样,所以淘宝我还没试过。
开启F12 定位一下搜索框和搜索按钮
input = WaiT.until(EC.presence_of_element_located((By.XPATH,'//*[@id="key"]')))
submit = WAIT.until(EC.element_to_be_clickable((By.XPATH,'//*[@id="search"]/div/div[2]/button')))
input.send_keys(Goods)
submit.click()接下来我们要的是按销量排名,那就要点击这个 onclick事件
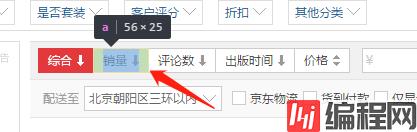
发现使用click()还是无法进行点击,因为这是个js跳转 所以得用下面代码
submit_js = WAIT.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="J_filter"]/div[1]/div[1]/a[2]')))
browser.execute_script("$(arguments[0]).click()", submit_js)接下来就还是检测是否加载了下面的元素
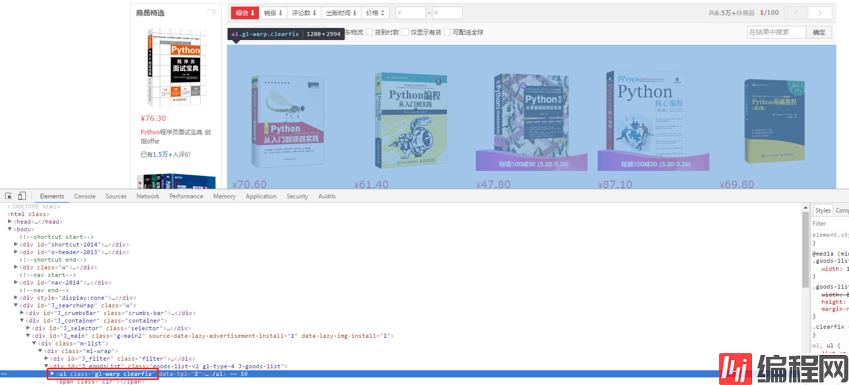
开始分析各项 怎么获取里面的数据就不说了
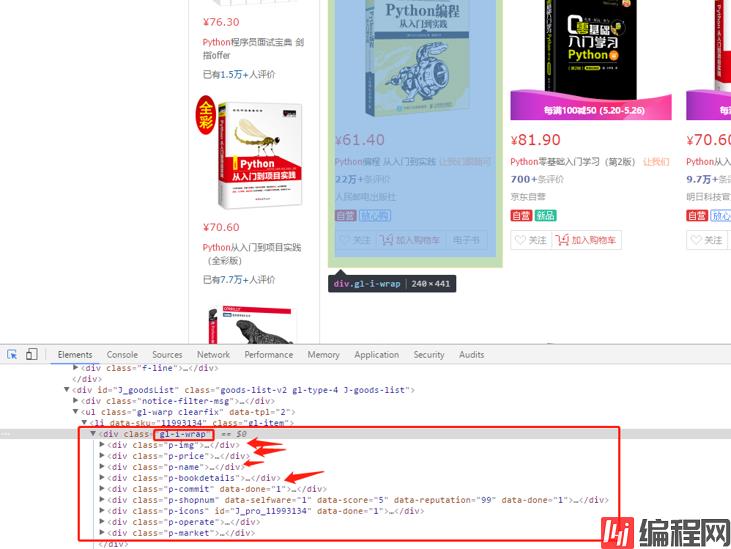
这时候可能爬的不完全,因为京东是动态加载的 需要去模拟一下把页面拉到底部
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")按照这样子进行循环遍历,把每一个值添加到goods_data列表里去,但也保证不了可能会出现找不到对象的属性,抛出AttributeError异常,这里已经尝试过了,所以写下这个异常处理!
然后获取完一页就下一页,然后得写个代码来检查是否跳转到指定页面
WAIT.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#J_bottomPage > span.p-num > a.curr'),str(page_num)))再获取每一页当前页面源码进行解析提取内容,保存到 goods_data 列表中,最后写入xls文件!
Tips:里面sleep 时间视情况而定,太快会导致获取不全,但如果网速快能弥补这一点,目前测试情况来看是这样子的问题!
附上代码:
from selenium import WEBdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import xlwt
import time
goods = input('请输入你要爬取的商品名称:')
goods_data = []
browser = webdriver.PhantomJS()
WAIT = WebDriverWait(browser,10)
browser.set_window_size(1000,600)
def seach(goods):
try:
print('开始自动化爬取京东商品信息......')
browser.get('https://www.jd.com/')
input = WAIT.until(EC.presence_of_element_located((By.XPATH,'//*[@id="key"]')))
submit = WAIT.until(EC.element_to_be_clickable((By.XPATH,'//*[@id="search"]/div/div[2]/button')))
input.send_keys(goods)
submit.click()
submit_js = WAIT.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="J_filter"]/div[1]/div[1]/a[2]')))
browser.execute_script("$(arguments[0]).click()", submit_js)
time.sleep(1)
get_source()
except TimeoutException:
return seach(goods)
def get_source():
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(1)
WAIT.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#J_goodsList > ul')))
html = browser.page_source
soup = BeautifulSoup(html,'lxml')
save_data(soup)
def save_data(soup):
html = soup.find_all(class_='gl-i-wrap')
for item in html:
try:
goods_name = item.find(class_='p-name').find('em').text
goods_link = 'https:' + item.find(class_='p-img').find('a').get('href')
goods_evaluate = item.find(class_='p-commit').text
goods_store = item.find(class_='curr-shop').text
goods_money = item.find(class_='p-price').find('i').text
print(('爬取: ' + goods_name))
goods_data.append([goods_name,goods_link,goods_evaluate,goods_store,goods_money])
except AttributeError:
pass
def next_page(page_num):
try:
print('获取下一页数据')
next_btn = WAIT.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_bottomPage > span.p-num > a.pn-next')))
next_btn.click()
WAIT.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#J_bottomPage > span.p-num > a.curr'),str(page_num)))
get_source()
except TimeoutException:
browser.refresh()
return next_page(page_num)
def save_to_excel():
book = xlwt.Workbook(encoding='utf-8', style_compression=0)
sheet = book.add_sheet(goods, cell_overwrite_ok=True)
sheet.col(0).width = 256 * 80
sheet.col(1).width = 256 * 40
sheet.col(2).width = 256 * 20
sheet.col(3).width = 256 * 25
sheet.col(4).width = 256 * 20
sheet.write(0, 0, '商品名称')
sheet.write(0, 1, '商品链接')
sheet.write(0, 2, '评价人数')
sheet.write(0, 3, '店名')
sheet.write(0, 4, '价格')
for item in goods_data:
n = goods_data.index(item) + 1
sheet.write(n, 0, item[0])
sheet.write(n, 1, item[1])
sheet.write(n, 2, item[2])
sheet.write(n, 3, item[3])
sheet.write(n, 4, item[4])
book.save(str(goods) + u'.xls')
def main():
try:
seach(goods)
for i in range(2,11):
next_page(i)
print('-'*50)
print('数据爬取完毕,正在写入xls.....')
save_to_excel()
print('写入成功!!!')
finally:
browser.close()
browser.quit()
if __name__ == '__main__':
main()

0