Python 官方文档:入门教程 => 点击学习
XPath 语法 XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。 XML 实例文档 我们将在下面的例子中使用这个 XML 文档。 <
XPath 语法
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
XML 实例文档
我们将在下面的例子中使用这个 XML 文档。
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。 下面列出了最有用的路径表达式:
表达式 描述
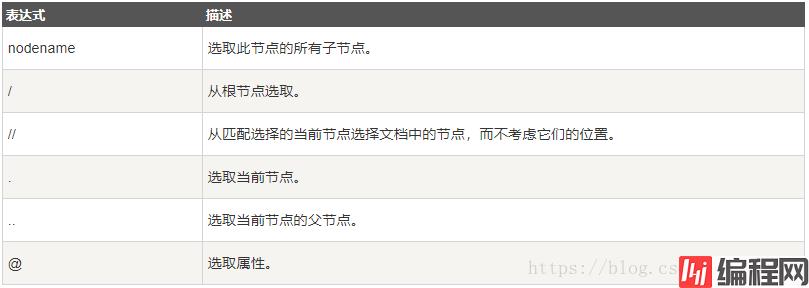
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
路径表达式 结果

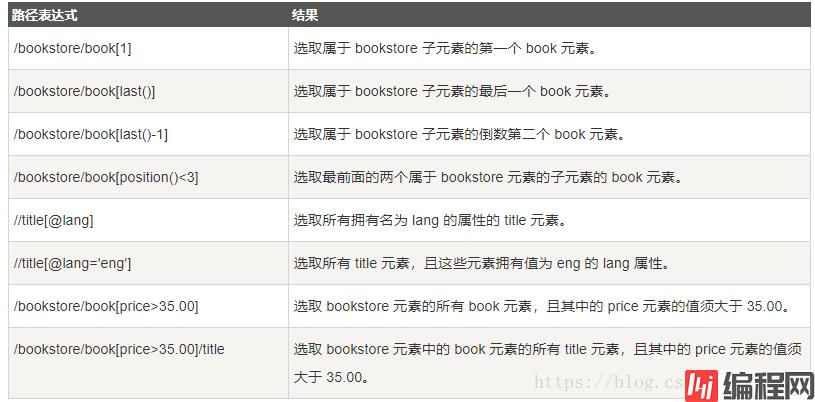
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
路径表达式 结果
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
通配符 描述
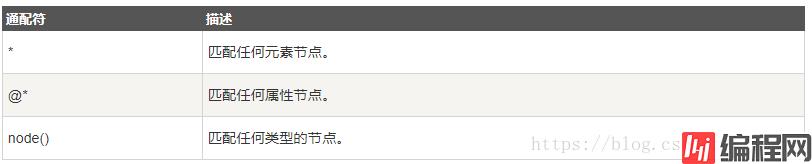
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
路径表达式 结果

选取若干路径
通过在路径表达式中使用”|”运算符,您可以选取若干个路径。
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
路径表达式 结果

--结束END--
本文标题: 【Python】Python爬虫之Sel
本文链接: https://www.lsjlt.com/news/184284.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0